д»ҠеӨ©еј•еӯҗжҜ”иҫғй•ҝпјҢе…ҲиҜҙзӮ№е’Ңдё»йўҳж— е…ізҡ„пјҢдҪҶеҚідҫҝж— е…іпјҢзӣёе…іеҶ…е®№д№ҹжҳҜжңүж„Ҹд№үзҡ„гҖӮ
еүҚеҮ еӨ©ж–Үз« йҮҢиҜҙпјҢжҲ‘зҡ„з”ЁжҲ·ж–°еўһж–ӯеҙ–ејҸдёӢи·ҢпјҢе—ҜпјҢжңүиҜ„и®әиҜҙпјҢеӣ дёәе№Іиҙ§и¶ҠжқҘи¶Ҡе°‘пјҢйӮЈдёӘпјҢе…¶е®һжҲ‘иҰҒиҜҙдёҖдёӘи§ӮзӮ№пјҢе…¬дј—еҸ·иҺ·еҸ–и®ўйҳ…з”ЁжҲ·зҡ„иғҪеҠӣпјҢе’ҢдҪ жҸҗдҫӣзҡ„ж–Үз« иҙЁйҮҸд»·еҖјпјҢе…¶е®һе№¶ж— зӣҙжҺҘе…іиҒ”гҖӮ

жҲ‘们е…ҲиҜҙдёҖдёӘиҜқйўҳпјҢе…¬дј—еҸ·зҡ„и®ўйҳ…д»Һе“ӘйҮҢжқҘгҖӮжҲ‘们数数зңӢе•Ҡ
жңӢеҸӢеңҲпјҢеҫ®дҝЎзҫӨпјҢеҹәдәҺз”ЁжҲ·зҡ„иҮӘеҸ‘иҪ¬еҸ‘е’ҢжҺЁиҚҗгҖӮ
еҗҢзұ»зҹҘеҗҚдёӘдәәе…¬дј—еҸ·зҡ„еҸӢжғ…жҺЁиҚҗгҖӮ
иЎҢдёҡеҶ…зҹҘеҗҚе…¬дј—еҸ·зҡ„иҪ¬иҪҪжҺЁиҚҗпјҢжҜ”еҰӮ36ж°ӘпјҢиҷҺе—…дј еӘ’зӯүгҖӮ
д»Ҡж—ҘеӨҙжқЎпјҢзҪ‘жҳ“пјҢзҷҫеәҰзҷҫ家пјҢеҮӨеҮ°дј еӘ’ зӯүе…¶д»–еӘ’дҪ“дҪң家зӣҙжҺҘе…Ҙй©»еј•жөҒгҖӮ
еҫ®еҚҡдёӘдәәеҸ·пјҢеҸҠеӨ§Vеј•жөҒгҖӮ
зҹҘд№ҺејҖи®ҫдё“ж ҸпјҢеӣһзӯ”й—®йўҳеј•жөҒгҖӮиұҶз“Јеј•жөҒпјҢеҲҶзӯ”пјҢеҖјд№Һеј•жөҒгҖӮ
иҙҙеҗ§пјҢзҷҫеәҰзҹҘйҒ“еҸӮдёҺи®Ёи®әеј•жөҒгҖӮ
и…ҫи®Ҝе№ҝзӮ№йҖҡд№°е№ҝе‘Ҡеј•жөҒгҖӮ
еӨ§еһӢиҮӘеӘ’дҪ“иҒ”зӣҹйҮҮиҙӯе№ҝе‘ҠпјҢеҸ‘еёғиҪҜж–Үеј•жөҒгҖӮ
е…¶д»–дёҖдәӣзҒ°иүІзҡ„пјҢеҰӮеҫ®дҝЎе°ҸеҸ·еҠ зҫӨзҫӨеҸ‘пјҢQQе°ҸеҸ·еҠ зҫӨзҫӨеҸ‘пјҢж·ҳе®қд№°еғөе°ёзІүзӯүзӯүпјҢе°ұдёҚдёҖдёҖеҲ—еҮәдәҶгҖӮ
д»ҘдёҠз§Қз§ҚпјҢйғҪжҳҜеҜје…Ҙз”ЁжҲ·пјҢеўһеҠ и®ўйҳ…зҡ„ж–№жі•пјҢеҪ“然пјҢе’ҢеҶ…е®№д№ҹжңүе…ізі»пјҢеҗҺйқўжҲ‘дјҡеҶҚиҜҙпјҢе…ҲиҜҙеҰӮдёҠйҖ”еҫ„пјҢжҲ‘з”ЁеҲ°зҡ„пјҢжңүж•Ҳжһңзҡ„гҖӮ
1гҖҒзҹҘеҗҚдёӘдәәеҸ·зҡ„еҸӢжғ…жҺЁиҚҗ
еҶҜеӨ§иҫүзҡ„е°ҸйҒ“ж¶ҲжҒҜжҺЁиҚҗж•ҲжһңжңҖеҘҪпјҢеҗҺжқҘеҘізҪ‘зәўangela zhuзҡ„жҺЁиҚҗж•Ҳжһңд№ҹйқһеёёеҘҪгҖӮжӯӨеӨ–д№ҹжңүдёҖдәӣе…¶д»–жңӢеҸӢжҺЁиҚҗиҝҮпјҢйғҪжңүдёҚй”ҷзҡ„ж•ҲжһңпјҢдҪҶжҜ•з«ҹжҳҜдёҖж¬ЎжҖ§иЎҢдёәпјҢеҫҲйҡҫе…·жңүжҢҒз»ӯзҡ„з”ЁжҲ·еј•жөҒж•ҲжһңгҖӮ
д»ҘдёҠеқҮдёәеҸӢжғ…жҺЁиҚҗпјҢйқһе•ҶдёҡиЎҢдёәгҖӮ
2гҖҒзҹҘеҗҚиЎҢдёҡе…¬дј—еҸ·иҪ¬иҪҪжҺЁиҚҗ
36ж°Әе’ҢиҷҺе—…еқҮеҒҡиҝҮеӨҡж¬ЎжҺЁиҚҗпјҢеҲҡејҖе§Ӣж•ҲжһңеҫҲеҘҪпјҢеҗҺжқҘеҹәжң¬дёҚеҶҚжңүж•ҲжһңпјҢжҲ‘зҡ„зҗҶи§ЈжҳҜпјҢиҜҘе…іжіЁзҡ„еҹәжң¬йғҪе…іжіЁдәҶгҖӮ
3гҖҒжңӢеҸӢеңҲпјҢеҫ®дҝЎзҫӨпјҢи®ўйҳ…иҖ…иҮӘеҸ‘жҺЁиҚҗе’ҢиҪ¬иҪҪ
иҝҷжҳҜзӣ®еүҚдёҖзӣҙд»Қ然иҺ·еҫ—ж–°еўһзҡ„йҖ”еҫ„гҖӮд№ҹжҳҜзӣ®еүҚеҮ д№Һе”ҜдёҖиҺ·еҫ—и®ўйҳ…зҡ„йҖ”еҫ„гҖӮ
дҪҶе®һйҷ…дёҠпјҢд№ҹеӯҳеңЁиҜҘе…іжіЁзҡ„еҹәжң¬е…іжіЁпјҢиҰҶзӣ–йқўзҡ„иҝӣдёҖжӯҘжҸҗеҚҮе·Із»ҸеҫҲйҡҫгҖӮ
4гҖҒзҹҘд№ҺпјҢеҫ®еҚҡеј•жөҒ
жңҖејҖе§ӢжҲ‘иҜ•иҝҮзҹҘд№Һеј•жөҒпјҢзЁҚеҫ®жҠҠзҹҘд№ҺиҙҰжҲ·жҗһжҙ»и·ғдёҖдәӣпјҢиҝҳжҳҜеҸҜд»ҘеёҰжқҘзЁіе®ҡзҡ„з”ЁжҲ·и®ўйҳ…пјҢе®һйҷ…дёҠзӣҙеҲ°зҺ°еңЁпјҢжҲ‘зҹҘд№ҺдёҠзҡ„и®ўйҳ…з”ЁжҲ·дҫқ然жҜ”еҫ®дҝЎе…¬дј—еҸ·й«ҳжҺҘиҝ‘дёҖеҖҚгҖӮ дҪҶеҗҺжқҘиҮӘе·ұжҖ„ж°”пјҢзҹҘд№ҺиҙҰжҲ·дёҚеҶҚжӣҙж–°пјҢжүҖд»ҘиҝҷжқЎи·Ҝиў«жҲ‘иҮӘе·ұж–ӯдәҶгҖӮ
иҝҷйҮҢзЁҚеҫ®и§ЈйҮҠдёҖдёӢпјҢзҹҘд№Һе®ҳ方并жңӘе°ҒзҰҒпјҢеҲ йҷӨпјҢеұҸи”ҪжҲ‘зҡ„еҶ…е®№пјҢдёҖеҲҮйғҪжҳҜжҲ‘иҮӘе·ұеҒҡзҡ„еҶіе®ҡпјӣжӯӨеӨ–пјҢжҲ‘ж—ўдёҚеҗҰи®ӨзҹҘд№Һзҡ„д»·еҖјпјҢд№ҹдёҚзңӢиЎ°зҹҘд№Һзҡ„еүҚжҷҜпјҢеҸӘжҳҜеҚ•зәҜдёӘдәәй—®йўҳпјҢеёҢжңӣиҜ»иҖ…дёҚиҰҒиҝҮеәҰиҒ”жғігҖӮ
еҫ®еҚҡпјҢеӣ дёәеҮ е№ҙеүҚе°ұдёҚжҙ»и·ғдәҶпјҢиҖҢдё”еҫ®еҚҡе®ҳж–№еҜ№еҫ®дҝЎеҜјжөҒзҡ„йҷҗеҲ¶иҝҳжҳҜиӣ®еӨҡпјҢжүҖд»ҘеҜјжөҒж•Ҳжһңд№ҹдёҚеҘҪгҖӮ
е…¶д»–зҡ„йҖ”еҫ„дёҖжҰӮжІЎжңүиҜ•иҝҮпјҢе…¶е®һеҢ…жӢ¬д»Ҡж—ҘеӨҙжқЎпјҢзҪ‘жҳ“пјҢзҷҫеәҰзҷҫ家пјҢиҝҳжңүе…¶д»–еҫҲеӨҡеӘ’дҪ“е№іеҸ°пјҢйғҪжңүдёҚеҗҢзҡ„дәәз»ҷжҲ‘еҸ‘иҝҮйӮҖиҜ·йӮ®д»¶пјҢеёҢжңӣжҲ‘еҠ е…Ҙ他们зҡ„еӘ’дҪ“е№іеҸ°пјҢдҪҶжңҖеҗҺжҲ‘дёҖдёӘйғҪжІЎеҠ е…ҘпјҢеҪ“然пјҢж ёеҝғеҺҹеӣ иҝҳжҳҜиҮӘе·ұжҮ’пјҢдҪҶд№ҹеӯҳеңЁдёҖдёӘеҜ№еӘ’дҪ“е№іеҸ°зҡ„и®ӨзҹҘе’ҢдёӘдәәд»·еҖји§Ӯзҡ„й—®йўҳпјҢжҲ‘жҖ»и§үеҫ—иҮӘе·ұжІЎеҠһжі•иҜҙжңҚиҮӘе·ұпјҢеҺ»иҜ•еӣҫд»ҘеӘ’дҪ“иҝҗиҗҘзҡ„ж–№ејҸиҝҺеҗҲиҜ»иҖ…зҡ„еҸЈе‘ігҖӮ
еҹәдәҺеҰӮдёҠпјҢзӣ®еүҚеҹәжң¬жІЎжңүзү№еҲ«зҡ„еј•жөҒйҖ”еҫ„пјҢеҚ•зәҜдҫқйқ з”ЁжҲ·иҮӘеҸ‘дј ж’ӯпјҢеңЁж–Үз« еҶ…е®№жІЎжңүжҳҺжҳҫзҡ„ж–№еҗ‘иҪ¬еҸҳпјҢд»ҘеҸҠжІЎжңүжҳҺжҳҫзҡ„зғӯзӮ№дәӢ件иҝҪйҡҸзҡ„еүҚжҸҗдёӢпјҢе·Із»Ҹеҹәжң¬иҫҫеҲ°дәҶдёҖдёӘ瓶йўҲгҖӮ
иҝҷжҳҜ第дәҢдёӘй—®йўҳпјҢејҖе§ӢжҺҘиҝ‘жҲ‘们д»ҠеӨ©зҡ„дё»йўҳгҖӮ
еҶ…е®№дёҺз”ЁжҲ·еҗёеј•еҠӣзҡ„й—®йўҳгҖӮ
жҳҜзҡ„пјҢжҹҗдәӣзҹҘеҗҚеӨ§VиҜҙпјҢжңүйқһеёёеҖјй’ұзҡ„ж–№жі•пјҢйқ еҶ…е®№зҲҶж–ҮпјҢжқҘиҺ·еҫ—еӨ§йҮҸз”ЁжҲ·гҖӮ
е…¶е®һиҝҷдәӣжҲ‘иҝҳзңҹдјҡпјҢжҲ‘д»ҠеӨ©е°ұиғҪж•ҷдҪ 们гҖӮ
1гҖҒж—¶ж•ҲжҖ§пјҢеңЁзғӯзӮ№дәӢ件еҮәзҺ°ж—¶пјҢ第дёҖж—¶й—ҙеҸ‘ж–ҮпјҢ并且具жңүе®Ңж•ҙеҶ…е®№гҖӮ
2гҖҒи§ӮзӮ№йІңжҳҺпјҢеҜ№й”ҷдёҚи®әпјҢжҢ‘еҠЁдәүи®®пјҢз…ҪеҠЁжғ…з»ӘгҖӮ
3гҖҒж ҮйўҳпјҢеҚұиЁҖиҖёеҗ¬пјҢж•…еј„зҺ„иҷҡгҖӮ
4гҖҒеҶ…е®№пјҢеҹәдәҺдҪ жүҖиЎЁиҫҫзҡ„и§ӮзӮ№пјҢжҗңйӣҶжңүеҲ©дәҺдҪ зҡ„жЎҲдҫӢжҲ–иҖ…жқңж’°дҪ зҡ„жҹҗдёӘжңӢеҸӢпјҢзүөејәйҷ„дјҡпјҢе“—дј—еҸ–е® еҚіеҸҜгҖӮ
иҮідәҺдәӢе®һеҰӮдҪ•пјҢеҜ№иҜ»иҖ…зҡ„её®еҠ©е’Ңд»·еҖјеҰӮдҪ•пјҢзңӢзңӢйӮЈдәӣе·ЁVзҡ„зғӯзӮ№ж–Үз« пјҢйңҖиҰҒд№Ҳпјҹ
йӮЈд№ҲзҺ°еңЁејҖе§Ӣд»ҠеӨ©зҡ„дё»йўҳгҖӮ
д»Ҡж—ҘеӨҙжқЎ жҳҜдёҖдёӘйқһеёёжҲҗеҠҹзҡ„移еҠЁдә’иҒ”зҪ‘еҲӣдёҡдјҒдёҡпјҢе…¶з”ЁжҲ·жҙ»и·ғеәҰпјҢиҗҘ收规模еқҮе·Із»ҸиҫҫеҲ°дәҶдёҖдёӘжғҠдәәзҡ„й«ҳеәҰгҖӮеёӮеҖјд№ҹзӣёеҪ“дәҶдёҚиө·пјҢеҸҜд»Ҙи®ӨдёәжңҖиҝ‘еҮ е№ҙйҷӨдәҶзҫҺеӣўе’Ңж»ҙж»ҙд»ҘеӨ–пјҢеӨ§жҰӮжңҖжңүжҪңеҠӣиө°е…Ҙе·ЁеӨҙйўҶеҹҹзҡ„дә’иҒ”зҪ‘е…¬еҸёпјҢеҫҲжғӯ愧пјҢеҗҺзҹҘеҗҺи§үзҡ„жҲ‘е…¶е®һжңҖиҝ‘еҮ е№ҙдёҖзӣҙжІЎзңӢиҝҮд»Ҡж—ҘеӨҙжқЎпјҢжңҖиҝ‘пјҢжҚўдәҶйғЁж–°жүӢжңәпјҢжүҚжіЁж„ҸеҲ°йҮҢйқўйў„иЈ…дәҶд»Ҡж—ҘеӨҙжқЎпјҢйӮЈд№Ҳд№ҹе°ұйҡҸд№Ӣжү“ејҖзңӢдәҶзңӢпјҢеҲ«иҜҙпјҢиҝҳжҢәиҝҮзҳҫзҡ„пјҢжҜҸеӨ©йғҪдјҡеҲ·еҮ йҒҚпјҢиҜ»дёҖдәӣеҘҮжҖӘзҡ„ж–Үз« гҖӮ
д»Ҡж—ҘеӨҙжқЎзҡ„жҲҗеҠҹпјҢиў«и®ӨдёәжҳҜз®—жі•зҡ„жҲҗеҠҹпјҢеҹәдәҺз”ЁжҲ·зҡ„зӮ№еҮ»пјҢйҳ…иҜ»иЎҢдёәпјҢеҒҡеҮәзҡ„дёҖз§ҚеҲӨж–ӯпјҢд»ҺиҖҢеҪўжҲҗдёӘжҖ§жҺЁйҖҒгҖӮ
дҪҶеҫҲжғӯ愧зҡ„жҳҜпјҢжҲ‘зӣёдҝЎпјҢеңЁд»Ҡж—ҘеӨҙжқЎзҡ„з®—жі•ж•°жҚ®йҮҢпјҢжҲ‘еӨ§зәҰжҳҜдёӘеҫҲдҪҺдҝ—пјҢеҫҲи„‘ж®Ӣзҡ„дәәгҖӮ
жҲ‘иғҪзҗҶи§ЈйӮЈдәӣдҪңиҖ…пјҢдёәдәҶиҝҺеҗҲеўһеҠ зӮ№еҮ»зҺҮзҡ„иҜүжұӮпјҢ他们жүҖеҒҡеҮәзҡ„з§Қз§ҚеҠӘеҠӣпјҢжҲ‘жүҖзңӢеҲ°зҡ„ж»ЎеұҸзҡ„ж ҮйўҳпјҢеҹәжң¬йғҪжҳҜж•…еј„зҺ„иҷҡпјҢеҚұиЁҖиҖёеҗ¬зҡ„дёңиҘҝпјҢе®һиҜқиҜҙпјҢжҲ‘зЎ®е®һд№ҹеӯҳеңЁеҘҪеҘҮеҝғпјҢжҢЁдёӘзӮ№иҝҮеҺ»зңӢзңӢеҲ°еә•жҳҜе•ҘдёңиҘҝй…Қзҡ„дёҠеҰӮжӯӨеҘҮе№»зҡ„ж ҮйўҳпјҢ然еҗҺе°ұжҳҜж„ӨжҖ’пјҢжҲ‘жүҝи®ӨжҲ‘жңүж—¶еҖҷдјҡиҝҮдәҺиҫғзңҹпјҢдёҖдәӣжҳҺжҳҫжүҜж·ЎпјҢи°ЈиЁҖпјҢд»ҘеҸҠиҺ«еҗҚе…¶еҰҷпјҢеӣ жһңдёҚеҲҶзҡ„дёңиҘҝпјҢжҲ–иҖ…жҳҜзүөејәйҷ„дјҡзҡ„ж–Үеӯ—пјҢе ӮиҖҢзҡҮд№Ӣзҡ„еҮәзҺ°еңЁж–Үз« йҮҢпјҢ然иҖҢпјҢеӣ дёәжҲ‘зӮ№еҮ»дәҶпјҢжөҸи§ҲдәҶпјҢзі»з»ҹеӨ§зәҰдјҡи®ӨдёәпјҢжҲ‘е°ұе–ңж¬ўиҝҷж ·зҡ„ж–Үеӯ—гҖӮ
жҳҜзҡ„пјҢжңүдәәдјҡиҜҙпјҢдҪ еҸҜд»ҘзӮ№еҸүе•ҠпјҢеҸҜд»ҘжҸҗдәӨдёҚж„ҹе…ҙи¶Је•ҠгҖӮжҲ‘еҫҲеҘҪеҘҮжңүеӨҡе°‘дәәдјҡеңЁзңӢе®ҢдёҖзҜҮж— иҒҠзҡ„ж–Үеӯ—еҗҺпјҢиҝҳиҰҒеҒҡиҝҷж ·зҡ„дәӢжғ…гҖӮ
дҪҶиҝҷдёӘй—®йўҳпјҢд№ҹ并йқһжҳҜд»Ҡж—ҘеӨҙжқЎжүҚдјҡжңүзҡ„гҖӮ
д№ӢеүҚпјҢеҫҲеӨҡдәәдјҡиҜҙзҷҫеәҰжңүйқһеёёеқҸзҡ„жЎҲдҫӢпјҢжҜ”еҰӮжҹҗдёӘиҜҚжұҮзҡ„жҗңзҙўз»“жһңпјҢдјҡиҺ«еҗҚе…¶еҰҷзҡ„еҮәзҺ°дёҖдәӣиүІжғ…еҶ…е®№пјҢеҫҲеӨҡдәәи§үеҫ—жҳҜзҷҫеәҰз®—жі•зғӮпјҢдҪҶе…¶е®һд»ҠеӨ©жҲ‘иҰҒе…¬е№іиҜҙдёҖеҸҘпјҢиҝҷдёҖеҸҘиҜқеҜ№дәҺйғЁеҲҶд»ҺдёҡиҖ…жқҘиҜҙпјҢжҳҜйқһеёёйқһеёёеҖјй’ұзҡ„пјҢд»ҠеӨ©еҸ‘еңЁиҝҷйҮҢпјҢжҲ‘зҢңжңүдәӣжңӢеҸӢдјҡе«ҢжҲ‘еӨҡеҳҙдәҶгҖӮ
жҗңзҙўеј•ж“ҺжңүдёҖжқЎи§„еҲҷпјҢжҳҜеҹәдәҺз”ЁжҲ·зӮ№еҮ»зҺҮжҸҗжқғпјҢз®—жі•и®ӨдёәпјҢе“ӘдёӘз»“жһңзҡ„зӮ№еҮ»зҺҮи¶Ҡй«ҳпјҢе°ұи¶Ҡи¶Ӣиҝ‘дәҺз”ЁжҲ·зҡ„жҗңзҙўзӣ®ж ҮпјҢиҝҷдёӘ规еҲҷйҖӮз”ЁдәҺйқһеёёеӨҡзҡ„жҗңзҙўеңәжҷҜпјҢдёҚд»…д»…жҳҜзҪ‘йЎөжҗңзҙўпјҢд№ҹеҢ…жӢ¬иӢ№жһңпјҢе®үеҚ“еёӮеңәзҡ„жҗңзҙўгҖӮжӣҙеӨҡжңәеҷЁеӯҰд№ и§ЈиҜ»пјҡwww.yangfenzi.com/tag/jiqixuexi
иҝҷдёӘдәӢжғ…иҝҪжәҜдёҖдёӢпјҢе…¶жңҖеҲқзҡ„зҗҶз”ұжҳҜиҝҷж ·зҡ„пјҢеҪ“жҗңзҙўеј•ж“Һи°ғж•ҙз®—жі•зҡ„ж—¶еҖҷпјҢйңҖиҰҒиҜ„дј°дҪ и°ғж•ҙзҡ„ж•ҲжһңеҘҪпјҢиҝҳжҳҜдёҚеҘҪеҜ№дёҚеҜ№пјҢиҜ·й—®жҖҺд№ҲйҖҡиҝҮж•°жҚ®иҜ„дј°е‘ўпјҹе°ұжҳҜз®—жі•и°ғж•ҙеүҚпјҢи°ғж•ҙеҗҺпјҢжҺ’еҗҚе’ҢзӮ№еҮ»зҺҮзҡ„е…ізі»жҳҜжҖҺж ·зҡ„пјҢжҜ”еҰӮ第дёҖеҗҚзӮ№еҮ»зҺҮеҰӮдҪ•пјҢеүҚдә”еҗҚзӮ№еҮ»зҺҮеҰӮдҪ•пјҢ第дёҖйЎөзӮ№еҮ»зҺҮеҰӮдҪ•пјҢзҝ»йЎөзҺҮжҳҜеӨҡе°‘гҖӮзҗҶи®әдёҠпјҢжҗңзҙўз®—жі•и¶Ҡе®Ңе–„пјҢз”ЁжҲ·зҡ„зӮ№еҮ»иЎҢдёәе°ұеә”иҜҘи¶Ҡи¶Ӣиҝ‘дәҺжҗңзҙўз»“жһңзҡ„第дёҖеҗҚпјҢжҲ‘们жғіжғіпјҢжҠӣејҖеүҚйқўзҡ„жүҖжңүй“әеһ«пјҢеҸӘд»ҺжҠҖжңҜе’Ңж•°жҚ®и§’еәҰеҺ»жғіиҝҷдёӘйҖ»иҫ‘пјҢжҳҜдёҚжҳҜиҝҷеӣһдәӢгҖӮжүҖд»ҘпјҢ既然зӮ№еҮ»зҺҮжҳҜиҜ„дј°жҗңзҙўз®—жі•и°ғж•ҙдјҳеҠЈзҡ„йҮҚиҰҒж•°жҚ®пјҢйӮЈд№Ҳе°Ҷе®ғдҪңдёәи°ғж•ҙжҗңзҙўжҺ’еҗҚзҡ„йҮҚиҰҒеҸӮж•°пјҢеІӮдёҚжҳҜдёҖеҠіж°ёйҖёпјҢз®ҖеҚ•зӣҙжҺҘзҡ„и§ЈеҶідәҶиҝҷдёӘй—®йўҳпјҒжӣҙеӨҡз®—жі•зҹҘиҜҶпјҡwww.yangfenzi.com/tag/suanfa
д»ҺжҠҖжңҜйҖ»иҫ‘пјҢиҝҷжҳҜдёҖдёӘйқһеёёз®ҖеҚ•жңүж•ҲеҸҲжё…жҷ°зҡ„жү§иЎҢж–№жЎҲгҖӮ
дҪҶй—®йўҳжқҘдәҶпјҢиүІжғ…еҶ…е®№зҡ„зӮ№еҮ»зҺҮпјҢдёҚи®әеңЁд»»дҪ•е…ій”®иҜҚпјҢйғҪдјҡеҚ жңүдјҳеҠҝгҖӮжҲ‘еҒҡиҝҮдёҚеҚҒеҲҶдёҘи°Ёзҡ„жҜ”еҜ№жөӢиҜ•пјҢжңүдёҖдёӘдёҚеҚҒеҲҶдёҘи°Ёзҡ„дёӘдәәи®ӨиҜҶпјҢдјјд№ҺGoogleеҜ№зӮ№еҮ»зҺҮжүҖеёҰжқҘзҡ„жҗңзҙўжқғеҖјпјҢжІЎжңүзҷҫеәҰз»ҷзҡ„й«ҳгҖӮеҪ“然д№ҹеҸҜиғҪжҳҜ他们еҜ№иүІжғ…еҶ…е®№еңЁйқһиүІжғ…жҗңзҙўиҜҚдёӯзҡ„жҺ’еҗҚпјҢеҒҡдәҶйўқеӨ–зҡ„йҷҚжқғеӨ„зҗҶгҖӮ
еӣһеҲ°д»Ҡж—ҘеӨҙжқЎпјҢд№ҹе°ұжҳҜд»ҠеӨ©зҡ„дё»йўҳпјҢеңЁжҺЁиҚҗз®—жі•е’ҢжңәеҷЁеӯҰд№ зҡ„дҪ“зі»йҮҢпјҢеҫҲеӨҡдҪңиҖ…д№ҹеҫҲжҳҺзҷҪиҝҷйҮҢзҡ„еҲ©зӣҠе’Ңд»·еҖје…ізі»пјҢдёәдәҶиҝҪжұӮз”ЁжҲ·зҡ„зӮ№еҮ»пјҢжөҸи§ҲпјҢд№ҹе°ұжҳҜиҮӘе·ұзҡ„еҶ…е®№жӣҙеӨҡзҡ„иў«жҺЁиҚҗпјҢ他们жӣҙеҖҫеҗ‘дәҺйҮҮзәіж•…еј„зҺ„иҷҡпјҢеҚұиЁҖиҖёеҗ¬зҡ„ж ҮйўҳпјҢиҖҢзі»з»ҹпјҢиҝҷеҘ—з®—жі•пјҢеңЁе®һи·өиҝҗиҗҘдёӯпјҢд№ҹжҳҺжҳҫжҝҖеҠұдәҶиҝҷж ·зҡ„иЎҢдёәгҖӮ
д»Һж•°жҚ®жқҘиҜҙпјҢиҝҷжҳҜдёҖдёӘеӨҡиөўпјҢз”ЁжҲ·зҡ„жҙ»и·ғеәҰеҫҲй«ҳпјҢзӮ№еҮ»зҺҮеҫҲеҘҪзңӢпјҢе№ҝе‘ҠеҚ–зҡ„еҫҲеҘҪпјҢдҪңиҖ…еҲҶеҲ°дәҶеҫҲеӨҡй’ұпјҢиҖҢиҝҷ家公еҸёиҺ·еҫ—дәҶйқһеёёжјӮдә®зҡ„иҙўеҠЎжҠҘе‘ҠгҖӮ
дҪҶжҲ‘иҝҳжҳҜеҫҲжӢ…еҝғиҝҷж ·зҡ„дәӢжғ…пјҢжҲ‘д»ҘеүҚи®ІиҝҮеҫҲеӨҡж¬ЎпјҢйҖүжӢ©жҖ§йҳ…иҜ»жҳҜдә’иҒ”зҪ‘ж—¶д»Јзҡ„дёҖдёӘйқһеёёеҸҜжҖ•зҡ„дәӢжғ…пјҢеҠ еү§дәҶеҒҸжҝҖпјҢеӮІж…ўпјҢж—ҸзҫӨзҡ„еҲҶиЈӮгҖӮд»ҺдёӯеӣҪеӨ§йҷҶпјҢеҲ°е®қеІӣеҸ°ж№ҫпјҢеҲ°йҰҷжёҜпјҢеҲ°зҫҺеӣҪпјҢжҲ‘们已з»ҸзңӢеҲ°дәҶиҝҷз§Қдә’иҒ”зҪ‘ж—¶д»ЈйҮҢпјҢдәә们ж”ҝжІ»и§ӮзӮ№е’ҢиҜүжұӮдёҘйҮҚеҶІзӘҒе’ҢеҜ№з«Ӣзҡ„жғ…еҶөи¶ҠжқҘи¶ҠжҝҖзғҲгҖӮдә’иҒ”зҪ‘жІЎжңүеҮҸе°‘еҒҸи§ҒпјҢжІЎжңүеўһеҠ еҪјжӯӨзҡ„зҗҶи§Је’ҢдәӨжөҒпјҢиҖҢжҳҜзӣёеҸҚпјҢеҠ еү§дәҶеҶІзӘҒе’ҢеҜ№з«ӢгҖӮ
жҺЁиҚҗз®—жі•пјҢеҲҷеҜ№жӯӨжҺЁжіўеҠ©жҫңгҖӮ
д»ҠеӨ©пјҢжҲ‘зңӢеҲ°иҝҷдәӣд»ҘзӮ№еҮ»зҺҮдёәиҜүжұӮзҡ„ж–Үз« пјҢжҲ‘еҸҜд»ҘеҪ“дёҖдёӘ笑иҜқзңӢпјҢжҲ–иҖ…еҪ“дёҖдёӘе…«еҚҰзңӢпјӣдҪҶжҳҜеҜ№дәҺе№ҙиҪ»дәәжқҘиҜҙпјҢжҚ®жҲ‘жүҖзҹҘпјҢеҫҲеӨҡдәәзҡ„дё–з•Ңи§ӮпјҢд»·еҖји§ӮпјҢдёҖзӣҙиў«иҝҷж ·зҡ„ж–Үеӯ—жүҖеј•еҜјпјҢжүҖзҒҢиҫ“гҖӮ
еүҚеҮ еӨ©е’Ңдәәе–қиҢ¶иҒҠеӨ©пјҢжңүдёӘеңЁж–°еҠ еқЎеӣҪз«ӢеӨ§еӯҰиҜ»д№Ұзҡ„е№ҙиҪ»дёӯеӣҪз•ҷеӯҰз”ҹпјҢж„Өж„Өзҡ„иҜҙпјҢж–°еҠ еқЎжҳҜеҰӮдҪ•е№Іжү°е’Ңз ҙеқҸе…ӢжӢүе…ӢиҝҗжІійЎ№зӣ®зҡ„пјҢд»–зҡ„жӢіжӢізҲұеӣҪеҝғжҳҜеҫҲдёҚй”ҷпјҢдҪҶжҲ‘зңҹзҡ„еҫҲжғҠиҜ§д»–е№іж—¶зҡ„йҳ…иҜ»д№ жғҜе’ҢдҝЎжҒҜжқҘжәҗпјҢиҝҷ件дәӢжғ…ж— и®әжҳҜдёӯеӣҪж”ҝеәңпјҢиҝҳжҳҜжі°еӣҪж”ҝеәңпјҢж—©е°ұеҮәйқўиҫҹи°ЈдәҶпјҢеҸҢеҸҢеҗҰи®ӨжңүжӯӨж„Ҹеҗ‘пјҢд»ҺеӨҙеҲ°е°ҫпјҢж №жң¬е°ұжІЎеӯҳеңЁиҝҮд»»дҪ•ж”ҝеәңеұӮйқўзҡ„жҙҪи°Ҳе’Ңе•Ҷи®ЁпјҢз ҙеқҸе’Ңе№Іжү°дёҖиҜҙеҸҲд»ҺдҪ•иҖҢжқҘпјҹ
еҪ“然пјҢжҲ‘зҹҘйҒ“пјҢйҳҙи°Ӣи®әиҖ…дёҖе®ҡдёҚзӣёдҝЎиҝҷдәӣпјҢзӮ№еҮ»зҺҮе’ҢжҺЁиҚҗз®—жі•е–ңж¬ўиҝҷж ·зҡ„дёңиҘҝгҖӮ
дёӢйқўж”ҫдёӨзҜҮж—§ж–Ү
еҒҸи§Ғзҡ„з”ұжқҘ-йҖүжӢ©жҖ§йҳ…иҜ»
еҶҚи°ҲйҖүжӢ©жҖ§йҳ…иҜ» – е·ҙй»ҺжғЁжЎҲзҡ„иҜқйўҳ
д»ҘдёҠж—§ж–ҮеҶ…е®№пјҢе…¶е®һжҜ”д»ҠеӨ©еҶҷзҡ„жӣҙжңүд»·еҖјгҖӮ
еҫҲеӨҡд»Ҡж—ҘеӨҙжқЎзҡ„ж–Үз« пјҢжҲ‘д№ҹжіЁж„ҸеҲ°дәҶпјҢдёәдәҶи§ӮзӮ№пјҢиӮҶж„ҸжӣІи§ЈдәӢе®һпјҢж··ж·Ҷеӣ жһңпјҢзӣёеҪ“дёҘйҮҚпјҢз”ҡиҮіжҳҜд»Өдәәйҡҫд»Ҙе®№еҝҚгҖӮжӯЈеҰӮ第дәҢзҜҮж–Үз« дёӯзҡ„иҢғдҫӢдёҖж ·гҖӮ
еҝ…йЎ»иҜҙпјҢи®©жҠҖжңҜеҺ»жүҝжӢ…еӨӘеӨҡзҡ„иҙЈд»»е’Ңд№үеҠЎпјҢжҳҜдёҚе…¬е№ізҡ„пјӣи®©е•Ҷдёҡе…¬еҸёеҺ»жүҝжӢ…жӢҜж•‘дәәзұ»зҡ„йҮҚд»»пјҢд№ҹжҳҜдёҚзҺ°е®һзҡ„гҖӮ
жҺЁиҚҗз®—жі•пјҢиҝҪйҡҸз”ЁжҲ·пјҢд»Һ常规жқҘиҜҙпјҢжҳҜдёҖж¬ҫеҘҪдә§е“Ғзҡ„ж ҮзӯҫпјҢдҪҶпјҢеңЁжҒ¶и¶Је‘ідёҠи¶Ҡйҷ·и¶Ҡж·ұпјҢжІүжәәдәҺиҝҪжұӮж•°жҚ®жҢҮж ҮпјҢиҖҢеӨұеҺ»еҜ№д»·еҖјзҡ„еҲӨе®ҡпјҢжҲ‘дёӘдәәдёҚе–ңж¬ўиҝҷж ·зҡ„з®—жі•йҖ»иҫ‘гҖӮ
гҖҗж–Ү/жӣ№ж”ҝВ В вҖңcaoz зҡ„жўҰе‘“вҖқпјҲеҫ®дҝЎеҸ·пјҡcaozsayпјүгҖ‘

В·ж°§еҲҶеӯҗзҪ‘пјҲhttp://www.yangfenzi.comпјү延伸йҳ…иҜ»пјҡ
вһӨВ д»ҺжҰӮеҝөжҸҗеҮәеҲ°иө°еҗ‘з№ҒиҚЈпјҡдәәе·ҘжҷәиғҪAIгҖҒжңәеҷЁеӯҰд№ е’Ңж·ұеәҰеӯҰд№ зҡ„еҢәеҲ«
вһӨВ FacebookејҖжәҗж·ұеәҰеӯҰд№ жЎҶжһ¶TorchnetдёҺи°·жӯҢTensorFlowжңүдҪ•дёҚеҗҢ
вһӨ гҖҠеҚ«жҠҘгҖӢпјҡз®—жі•еҰӮдҪ•еҪұе“ҚжҲ‘们зҡ„е·ҘдҪңе’Ңз”ҹжҙ»пјҢз®—жі•еҜ№з©·дәәжңүжӯ§и§Ҷ
вһӨВ зҷҫеәҰеҗҙжҒ©иҫҫи°Ҳж·ұеәҰеӯҰд№ еұҖйҷҗпјҡAIз»ҸжөҺд»·еҖјзӣ®еүҚд»…жқҘиҮӘзӣ‘зқЈеӯҰд№
вһӨВ еҚЎиҖҗеҹәжў…йҡҶеӨ§еӯҰйӮўжіўпјҡдёәдәәе·ҘжҷәиғҪиЈ…дёҠеј•ж“ҺвҖ”еҝҶж јжӢүдё№дёңзҷ»еұұд№Ӣж—…
вһӨВ еӮ…зӣӣпјҡж·ұеәҰеӯҰд№ жҳҜд»Җд№ҲпјҹдјҒдёҡж ёеҝғз«һдәүеҠӣжӯЈеңЁд»Һз®—жі•иҪ¬еҸҳдёәж•°жҚ®
вһӨВ иҙЁз–‘AIжіЎжІ«пјҡеҪ“жҲ‘们и°Ҳи®әжңәеҷЁеӯҰд№ ж—¶пјҢжҲ‘们究з«ҹеңЁиҜҙдәӣд»Җд№Ҳ
вһӨВ и°·жӯҢе®Је‘ҠвҖңдә‘1.0 ж—¶д»ЈвҖқз»Ҳз»“пјҢжңәеҷЁеӯҰд№ дјҡи®©е®ғз§°йңёжҷәиғҪдә‘еёӮеңәпјҹ
вһӨВ е“ҘдјҰжҜ”дәҡеӨ§еӯҰж•ҷжҺҲпјҡжңәеҷЁеӯҰд№ иғңиҝҮдәәзұ»зј–зЁӢпјҹAI з»ҲжһҒжҢ‘жҲҳжҳҜеҲӣйҖ еҠӣ






е…ҲиөһеҗҺзңӢжҳҜзҫҺеҫ·гҖӮеҸҰиҜ·ж•ҷжӣ№еӨ§дёӘй—®йўҳпјҢд№°еҚ–жөҒйҮҸеҸҢж–№йғҪжІЎз»ҹи®Ўе·Ҙе…·йӮЈд»Ҙе•ҘдёәеҮҶ
дёӢиҪҪеӨҙжқЎзңӢдәҶдёҖдёӢпјҢеӨ§иҮҙжөҸи§ҲдәҶдёҖйҒҚе°ұеҚёиҪҪдәҶгҖӮжҲ‘и§үеҫ—е…іжіЁиҖҒеёҲеҫ®дҝЎе…¬дј—еҸ·зҡ„дәәпјҢжІЎжңүеҮ дёӘдәәз»ҸеёёзңӢеӨҙжқЎгҖӮеҗҢж„Ҹзҡ„зӮ№иөһпјҒ
еҜ№д»Ҡж—ҘеӨҙжқЎ е’Ңжӣ№иҖҒеёҲи§Ӯж„ҹдёҖж · жҺЁиҚҗзҡ„ж–Үз« жңүж—¶зЎ®е®һдёҚй”ҷпјҢдҪҶеӨ§йғЁеҲҶеҶ…е®№ж„ҹи§үе°ұжҳҜйӮЈз§ҚиҜ»еӨҡдәҶж„ҹи§үиҮӘе·ұжҷәе•ҶдјҡдёӢйҷҚдјҡеҸҳlowзҡ„ж„ҹи§үгҖӮ еҪ“然жӣ№иҖҒеёҲд»ҺжҷәиғҪжҺЁиҚҗзӯүж–№йқўеҲҶжһҗеҫ—жӣҙйҖҸеҪ»пјҢиҖҢжҲ‘ з»јеҗҲиҖғиҷ‘е°ұжҳҜж”ҫејғд»Ҡж—ҘеӨҙжқЎдәҶгҖӮ
еҫ®иҪҜе°Ҹи–Үзҡ„дёӢзәҝд№ҹеҸҜд»ҘдҪңдёәдҫӢеӯҗ
жҲ‘д№ҹдёҖзӣҙиў«д»Ҡж—ҘеӨҙжқЎзҡ„жҲҗеҠҹиҝ·жғ‘пјҢеӣ д№ӢжҲ‘иҝҳеҺ»дёӢиҪҪз”ЁдәҶеҮ еӨ©пјҢйҮҢйқўзҡ„еҶ…е®№йғҪеҫҲдёҚз¬ҰеҗҲжҲ‘зҡ„е®ЎзҫҺе’Ңи§ӮзӮ№пјҢжңҖеҗҺиҝҳжҳҜеҚёиҪҪдәҶпјҢиҝҳжҳҜдёҚжҮӮдёәд»Җд№Ҳиҝҷд№ҲеӨҡдәәеҗ№жҚ§е®ғ
жҺЁиҚҗз®—жі•зҡ„зӣ®зҡ„жҳҜйҖҡиҝҮжӣҙзІҫеҮҶзҡ„дҝЎжҒҜжҠ•ж”ҫжҸҗй«ҳжҖ»дҪ“ж•ҲзӣҠпјҢзІ—з•Ҙең°иҜҙпјҢжҳҜе°ҶдјҒдёҡйҮҸеҢ–收зӣҠе’Ңз”ЁжҲ·ж»Ўж„ҸеәҰиҝҷдёӨдёӘзӣ®ж ҮжңҖеӨ§еҢ–гҖӮ科еӯҰ家е’Ңе·ҘзЁӢеёҲ们еңЁе»әжЁЎж—¶еҫҖеҫҖжҳҜжҠҠдјҒдёҡзҡ„еҲ©зӣҠж‘ҶеңЁйҰ–дҪҚзҡ„пјҢ然еҗҺеҜ»жүҫдјҒдёҡеҲ©зӣҠе’Ңз”ЁжҲ·еҲ©зӣҠжңҖдҪізҡ„жқғиЎЎгҖӮжЁЎеһӢе’Ң算法并дёҚиғҪеӨ„зҗҶжүҖжңүзҡ„жғ…еҶөпјҢиҖҢжҳҜе°ҪйҮҸд»Һзі»з»ҹзә§зҡ„и§’еәҰеҺ»жӣҙеҘҪең°жңҚеҠЎдјҒдёҡпјҲе’Ңз”ЁжҲ·пјүпјҢиҰҒжҖӘд№ҹеҸӘиғҪжҖӘеҪ“еүҚзҡ„з®—жі•иҝҳдёҚеӨҹгҖҢжҷәиғҪгҖҚпјҢд»ҘеҸҠдәәжҖ§зҡ„еӨҚжқӮдәҶ~
йқһеёёдёҚе–ңж¬ўд»Ҡж—ҘеӨҙжқЎпјҢеӣ дёәжҜ•з«ҹеңЁдә’иҒ”зҪ‘иЎҢдёҡе·ҘдҪңпјҢдёӢиҝҮдёӨж¬ЎпјҢеҝҚзқҖз”ЁдәҶдёҖж®өж—¶й—ҙиҝҳжҳҜеҲ дәҶгҖӮдёӨзӣёеҜ№жҜ”жӣҙеҠ и§үеҫ—еҫ®дҝЎзҡ„е…ӢеҲ¶ вҖңеҘҪдә§е“Ғеә”иҜҘз”Ёе®ҢеҚіиө°вҖқзҡ„зҗҶеҝөеҫҲдәҶдёҚиө·
иҝҷж ·зңӢжқҘпјҢд»·еҖји§ӮдёҖиҮҙжҜ”еҜ№дёҖдёӘдәәзҡ„жҖҒеәҰеңЁй•ҝд№…зҡ„дәӨеҫҖдёӯжӣҙйҮҚиҰҒгҖӮ
еӣ дёәзӣ®ж Үз”ЁжҲ·дёәз•ҷеӯҰз”ҹпјҢеҒҡиҝҮе°ҸеҸ·жҪңдјҸеҫ®дҝЎзҫӨпјҢзҶҹжӮүдёҖзӮ№иЎҢжғ…еҗҺеҸ‘зҺ°дёҚе°‘з•ҷеӯҰз”ҹзҡ„еҗҢеӯҰзҫӨе·®дёҚеӨҡдёҖеҚҠд»ҘдёҠжҳҜдёӯд»Ӣе’Ңеҫ®е•ҶдәҶ
иҜҙеҲ°жҺЁиҚҗпјҢеңЁеӣҪеҶ…пјҢзҪ‘жҳ“дә‘йҹід№җ зўҫеҺӢгҖӮ е…¶д»–зҡ„з®Җзӣҙи®©дәәи§үзқҖжғіжөҒжіӘпјҢжҜ”еҰӮжҲ‘д№°дәҶзғӨз®ұпјҢзҷҫеәҰзҡ„йӮЈдёӘеҸ«д»Җд№ҲжқҘзқҖе°ұйғҪеҲ°еӨ„жҳҜзғӨз®ұзҡ„е°ҸеӣҫзүҮпјҲдҪ еҠЁеҠЁи„‘еӯҗж”ҫдёӘзғӨз®ұзҡ„е…іиҒ”еәҰжңҖй«ҳзҡ„жҜ”еҰӮзғ§зғӨзҡ„ж–ҷ зғӨзӣҳ иҝҷдәӣ дјҡжӯ»д№ҲпјүпјҢд№°дёӘеҮүйһӢпјҢејҖж·ҳе®қйғҪжҳҜеҮүйһӢпјҲдҪ иҮӘе·ұз”ЁдҪ 们平еҸ°зҡ„ж•°жҚ®з®—з®— иҝһзқҖд№°дёӨ件еҗҢе“Ғзұ»е•Ҷе“Ғзҡ„дәәжңүеӨҡе°‘пјүпјҢжҢәжӮІе“Җзҡ„ жҳҜиҝҷдәӣдә’иҒ”зҪ‘е…¬еҸёйғҪжҳҜжҷәе•ҶеӨӘй«ҳжғ…е•ҶеӨӘдҪҺзҡ„зәҜжҠҖжңҜй«ҳжқҗз”ҹзјҳж•…еҗ—пјҹ еҸҰеӨ–жүҜдёҖеҸҘпјҢе…ідәҺжңәеҷЁеӯҰд№ пјҢеҪ“ж—¶йҳҝжі•зӢ—жҗһжқҺдё–зҹізҡ„ж—¶еҖҷпјҢжңүдёӘиҜ„и®әжңүзӮ№ж„ҸжҖқпјҢвҖңеҰӮжһңзӢ—жҳҜдёҖејҖе§Ӣе°ұе·Із»ҸвҖңйў„жөӢвҖқеҲ°дәҶжңҖз»Ҳзҡ„з»“жһңпјҢйӮЈд№Ҳд»–зҡ„зӣ®зҡ„е°ұжҳҜи®©еұҖйқўеҗ‘иҮӘе·ұи®ҫжғізҡ„з»“жһңеҸ‘еұ•пјҢйӮЈд№Ҳд»–зҡ„жҜҸдёҖжӯҘжЈӢйғҪеҸӘжҳҜдёәдәҶе®һзҺ°жңҖз»Ҳзӣ®ж ҮиҖҢдёӢзҡ„пјҢиҖҢдёҚжҳҜеғҸдәәзұ»жЈӢжүӢйӮЈж ·жҳҜеңЁдәүдёҖдёӘеӯҗдёҖеқ—ең°з”ҡиҮіж•ҙдёӘеұҖеҠҝзҡ„зҡ„зҹӯй•ҝпјҢжүҖд»Ҙд»–дјҡдёӢеҮәдёҖдәӣеҪ“ж—¶зңӢжқҘеҫҲжҢ«дҪҶжҳҜиҝҮ50 100жүӢеҗҺеҸ‘зҺ°д»–еҪ“ж—¶еҸӘжҳҜеңЁдёәвҖңжңӘжқҘвҖқиҖҢиЎҢеҠЁпјҢеҸҜиғҪдәәзұ»жЈӢжүӢиҝҳжҳҜеңЁдёә зҺ°еңЁ иҖҢиЎҢеҠЁгҖӮ
е–ңж¬ўе°ҸйҒ“ж¶ҲжҒҜе’Ңcaozд»ҘеҸҠе’ҢиҸңеӨҙзҡ„йЈҺж ј
е…јеҗ¬еҲҷжҳҺпјҢеҒҸдҝЎеҲҷжҡ—гҖӮжҺЁиҚҗз®—жі•жңҖеӨ§зҡ„зјәзӮ№еңЁдәҺйҷ·е…ҘеҒҸдҝЎзҡ„еұҖйқўпјҢж— жі•жҺҢжҸЎе…Ёйқўзҡ„и®ӨзҹҘгҖӮ
е…¶е®һд»Ҡж—ҘеӨҙжқЎзҡ„жҺЁиҚҗеҶ…е®№пјҢжүҫдёҖдёӘзңҹжҮӮеӘ’дҪ“зҡ„дәәжқҘйҖүжӢ©жҳҜе·®дёҚеӨҡзҡ„пјҢзӨҫдјҡж–°й—»пјҢзҢҺеҘҮеҹәжң¬йғҪжҳҜеӨ§йғЁеҲҶдәәж„ҹе…ҙи¶Јзҡ„гҖӮдёӘдәәзҢңжөӢпјҢд»Ҙд»Ҡж—ҘеӨҙжқЎж”¶йӣҶеҲ°зҡ„ж•°жҚ®дёӯпјҢи„Ҹж•°жҚ®зҡ„жҜ”дҫӢеә”иҜҘйқһеёёй«ҳпјҢз”ҡиҮій«ҳеҲ°д»–жүҖиҜҙзҡ„еӨ§ж•°жҚ®з®—жі•ж— жі•зІҫз»ҶдёҺеҮҶзЎ®гҖӮ
зӣ®еүҚзҡ„дёҖдёӘзғӯзӮ№иҜқйўҳжҳҜеӣҫеғҸеҲҶзұ»зӯүйўҶеҹҹзҡ„еҚҠзӣ‘зқЈеӯҰд№ пјҢеҫҲе°‘жңүж Үи®°зҡ„дҫӢеӯҗеӨ§еһӢж•°жҚ®йӣҶзҡ„ж–№жі•гҖӮејәеҢ–еӯҰд№ жҳҜжӣҙе®№жҳ“еңЁжңәеҷЁдәәжҺ§еҲ¶дёҺе…¶д»–жҺ§еҲ¶зі»з»ҹзӯүйўҶеҹҹжңүеә”з”ЁгҖӮ
е…ҲзңӢеҗҺиөһиөҸпјҢд№ӢеҗҺеҲҶдә«жңӢеҸӢеңҲе’ҢеҘҪеҸӢ
жҠҖжңҜеӮ¬з”ҹжөҒйҮҸй»‘дә§
жңүдёҖеҸҘиҜқзү№еҲ«еҗёеј•дәҶжҲ‘зҡ„жіЁж„Ҹ: дёҖж¬ЎжҖ§иЎҢдёәгҖӮ
жңүдёҖеӨ©пјҢжҲ‘еҗҢдәӢеҫҲдёҘеҺүзҡ„и·ҹжҲ‘иҜҙпјҢдҪ иҝһд»Ҡж—ҘеӨҙжқЎйғҪдёҚзңӢпјҢеҒҡд»Җд№ҲXXеҳӣпјҹжҲ‘еҫҲдёҚеҘҪж„ҸжҖқпјҢ然еҗҺиЈ…дәҶеӨҙжқЎпјҢзӮ№ејҖзңӢдәҶзңӢпјҢ并没жңүд»Җд№Ҳж„ҹе…ҙи¶Јзҡ„дёңиҘҝпјҢеҫҲд№…жІЎзңӢпјҢжңҖеҗҺеҲ дәҶгҖӮжҲ‘ж„ҸиҜҶеҲ°пјҢеҲ«дәәж„ҹе…ҙи¶Јзҡ„дёңиҘҝи·ҹжҲ‘ж №жң¬дёҚдёҖж ·пјҢе°ұеғҸеҲ«дәәиҜҙXXXз”өеҪұеҘҪзңӢзҡ„ж—¶еҖҷпјҢжҲ‘зӣёдҝЎд»–жҳҜзңҹеҝғзҡ„пјҢдҪҶжҳҜжҲ‘жІЎе…ҙи¶ЈгҖӮйӮЈдәӣжүҖи°“е°ҸзІүзәўпјҢXXи„‘ж®ӢзІүпјҢзҲұеӣҪиҙјзӯүзӯүпјҢ他们иӮҜе®ҡи®ӨдёәиҮӘе·ұзҡ„иЎҢдёәжҳҜеҜ№зҡ„гҖӮеҫҲеӨҡдәәеҸҜиғҪж №жң¬дёҚзңӢйӮЈдәӣзҗҶжҷәзҡ„ж–Үз« пјҢеҸӘзңӢз…ҪеҠЁжҖ§ж–Үз« гҖӮиҝҷеҮ еӨ©зӘҒ然жғізҺ©wotпјҢеҺ»зҪ‘еҗ§зҺ©дәҶзҺ©пјҢзҪ‘еҗ§йҮҢеҫҲеӨҡзҺ©жёёжҲҸзңӢзӣҙж’ӯпјҢзңӢи„‘ж®Ӣз”өеҪұз”өи§Ҷеү§зҡ„пјҢиҝҷдәӣдәәеҸҜиғҪ平时并没жңүе…¶д»–жё йҒ“жҺҘи§Ұдә’иҒ”зҪ‘пјҢиҝҷдәӣеЁұд№җе·Із»ҸжҳҜ他们е·ҘдҪңд№ӢеӨ–зҡ„е…ЁйғЁдәҶгҖӮеҸӘжңүеӘ’дҪ“жҺЁиҚҗзҡ„йӮЈдәӣзҲҶзӮёжҖ§ж–°й—»иғҪеј•иө·жіЁж„ҸпјҢе…¶д»–йғҪж— и§ҶвҖҰ
е…¶е®һи®әеқӣйҮҢзҡ„еЈ°йҹідјҡжӣҙеҠ еӨҡе…ғеҢ–дәӣпјҢиҝҷжҳҜеңЁзҺ°еңЁзҡ„移еҠЁдә’иҒ”ж—¶д»ЈпјҢи®әеқӣдјјд№ҺдёҚдјҡеҶҚеҙӣиө·дәҶгҖӮ
ејҘеҗҲдҝЎжҒҜж—¶д»ЈзӮ№зӨҫдјҡеҲҶжӯ§жҳҜдёӘеҫҲиҜҫйўҳгҖӮе…¶е®һжҲ‘д№ҹдёҚиөһеҗҢдјҡи®©дәәи¶ҠжқҘи¶ҠеҒҸжҝҖзҡ„жҺЁиҚҗз®—жі•пјҢдҪҶжҳҜдҪ зҡ„еӨҙжқЎи®©е°‘ж•°еӘ’дҪ“дәәе’Ңе№іеҸ°жүҖжҺҢжҺ§еҸҲжҳҜзңҹзҡ„еҘҪеҗ—пјҹе®һйҷ…еҠ дёҖдёӘиҙҹеҸҚйҰҲпјҢйҳ…иҜ»ж—¶й•ҝдёҚж»ЎдёҖе®ҡж•°еҖјпјҢжҲ–жҳҜз«ӢеҚіе…ій—ӯпјҢиҝӣиЎҢйҷҚжқғгҖӮеҜ№д»Ҡж—ҘеӨҙжқЎдёҚйҡҫеҗ§гҖӮзҷҫеәҰseoйӮЈеқ—еә”иҜҘд№ҹжңүзӣёеә”иҙҹеҸҚйҰҲпјҹеҫҲеӨҡж—¶еҖҷдёҚжҳҜеҒҡдёҚеҲ°пјҢиҖҢжҳҜеҲ©зӣҠй“ҫжқЎе·Із»ҸеҪўжҲҗгҖӮжӣ№еӨ§пјҢ2011е№ҙзҡ„TED TALK Eli Pariser: Beware online "filter bubbles" д»ҘGе’ҢFдёәдҫӢеү–жһҗиҝҮиҝҷдёӘй—®йўҳгҖӮ
еңЁиҮӘе·ұзҶҹзҹҘзҡ„дёҖдёӘжҲ–иҖ…еҮ дёӘйўҶеҹҹпјҢдёҖзӣҙиҫ“еҮәй«ҳиҙЁйҮҸзҡ„еҶ…е®№йҡҫйҒ“еҘҪеӨ§
еӨҙжқЎе…¶е®һеҸӘжҳҜеңЁеҶ·еҗҜеҠЁзҡ„ж—¶еҖҷдјҡеёҰжҜ”иҫғеӨҡзҡ„иүІжғ…е’ҢдҪҺдҝ—еҶ…е®№пјҢеӨҡеҲ·еҮ еӨ©пјҢжҗңдәӣж„ҹе…ҙи¶Јзҡ„еҶ…е®№пјҢеӨҙжқЎз»ҷдҪ жҺЁзҡ„еҶ…е®№е°ұжҢәдёҚй”ҷдәҶгҖӮ
жӣҫз»ҸдёҖеәҰд№ҹйқһеёёжІүиҝ·д»Ҡж—ҘеӨҙжқЎпјҢж•ҙеӨ©еҲ·дёҚе®ҢпјҢзү№еҲ«жҳҜеҗҺжқҘеҲ·еҲ°е°Ҹи§Ҷйў‘пјҢжӣҙеҠ дёҚеҸҜ收жӢҫпјҢж„ҹи§үжңүдёҚеҒңең°зңӢжү“жһ¶жҡҙеҠӣи§Ҷйў‘зҡ„зҷ–еҘҪгҖӮжңҖеҗҺиҝҳжҳҜеҲ дәҶпјҢдё»иҰҒеҺҹеӣ жҳҜеӨӘиҙ№жөҒйҮҸпјҢи¶…еҘ—йӨҗеҗҺжөҒйҮҸзҡ„й’ұеҫҲеҝғз—ӣпјҢж¬ЎиҰҒеҺҹеӣ жҳҜи§үеҫ—иҝҷдёӘд№ҹеӨӘжөӘиҙ№ж—¶й—ҙдәҶпјҢзңӢдәҶеҚҠеӨ©д№ҹе°ұжҳҜиҝҮиҝҮзҳҫгҖӮ
ж·ұеҲ»иөһеҗҢжӣ№еӨ§иҜҙзҡ„пјҢзҺ°еңЁзңӢеҲ°и¶ҠжқҘи¶ҠеӨҡзҡ„ж–Үз« ж ҮйўҳиҜқдёҘйҮҚпјҢжҒЈж„ҸеҰ„дёәпјҢиҜҙзҡ„дёңиҘҝеҫҲжңүй—®йўҳпјҢдҪҶжҳҜиҝҳзңҹзҡ„жңүйӮЈд№ҲеӨҡдәәе°ұж„ҝж„ҸеҺ»зӣёдҝЎгҖӮ
д»Ҡж—ҘеӨҙжқЎеҲҡеҮәжқҘзҡ„ж—¶еҖҷиҝҳз”ЁиҝҮпјҢзҺ°еңЁе·Із»Ҹж—©е°ұдёҚз”ЁдәҶпјҢеӣ дёәеңЁд»–зҡ„жҺЁиҚҗзі»з»ҹдёӯйғҪжҳҜдёҺиүІжғ…пјҢи°ЈиЁҖзӣёе…ізҡ„пјҒдёҺиҮӘе·ұжғіиҰҒиҺ·еҸ–зҡ„зҹҘиҜҶе®Ңе…ЁдёҚеҗҢпјҒ
жӣ№иҖҒеёҲи§үеҫ—д»Ҡж—ҘеӨҙжқЎиғҪиө°иҝңеҗ—пјҹжҖ»и§үеҫ—зҺ°еңЁд»Ҡж—ҘеӨҙжқЎжңүзӮ№иҷҡеҒҮз№ҒиҚЈгҖӮ
зңҹе®һз№ҒиҚЈпјҢжҲ‘дёҚзңӢиЎ°гҖӮ
з®—жі•жҜ•з«ҹжІЎжңүдәәзҡ„еҘҪеҘҮеҝғдёҺжұӮзҹҘж¬І
д»Ҡж—ҘеӨҙжқЎе’ҢзҪ‘жҳ“йғҪдјҡи®©дәәзңӢзқҖжқҘж°”
зңӢжқҘйңҖиҰҒз»ҷжҺЁиҚҗеј•ж“ҺеҠ е…Ҙзұ»дјјжңәеҷЁдәәдёүеӨ§е®ҡеҫӢдәҶпјҢж»Ўи¶іе®ҡеҫӢиҰҒжұӮзҡ„ж–Үз« жүҚеҸҜд»Ҙиў«жҺЁиҚҗз»ҷдәәзұ»пјҒжҲ‘дёҚе–ңж¬ўжҺЁиҚҗз®—жі•пјҢж„ҹи§үйӮЈж ·дјҡд»ӨиҮӘе·ұеӣәжӯҘдәҺиҮӘе·ұзҡ„е°ҸеӨ©ең°гҖӮжүҖд»Ҙе°ҪйҮҸйҒҝе…ҚдҪҝз”ЁжҺЁиҚҗзҡ„еҠҹиғҪпјҢ并且йқһеҝ…иҰҒж—¶дёҚзҷ»еҪ•иҙҰеҸ·пјҢжіЁж„Ҹжё…зҗҶжіЁж„Ҹжё…зҗҶcookiesгҖӮеёҢжңӣиғҪеӨҹжӣҙе…Ёйқўең°иҺ·еҸ–дҝЎжҒҜпјҢж— и®әжҳҜдёҚжҳҜиҮӘе·ұж„ҹе…ҙи¶Јзҡ„гҖӮ
еҸҜд»Ҙж №жҚ®ж–Үз« зҡ„и·іеҮәж—¶й—ҙжқҘи°ғж•ҙз®—жі•пјҢжҠҠйӮЈдәӣзӮ№еҮ»зҺҮй«ҳдҪҶжҳҜеҒңз•ҷж—¶й—ҙдҪҺзҡ„йҷҚжқғгҖӮ
з®—жі•еҗҺйқўжҳҜдәәзҡ„жҖқжғіпјҢеҝ…е®ҡжңүдәәжҖ§еңЁдҪңжў—гҖӮ
еҺ»е№ҙзҡ„ж—¶еҖҷз»ҸжңӢеҸӢжҺЁиҚҗпјҢдёӢиҪҪиҝҮд»Ҡж—ҘеӨҙжқЎпјҢдҪҶз»ҷжҲ‘жҺЁиҚҗзҡ„ж»ЎеұҸ幕йғҪжҳҜдёҖдәӣж Үйўҳе…ҡпјҢзҢҺеҘҮж–Үз« пјҢеҘҪеҘҮзӮ№иҝӣеҺ»дёҖзңӢзңҹжҒЁдёҚеҫ—дёҫжҠҘпјҢзңҹжӯЈжңүд»·еҖјзҡ„еҶ…е®№еӨӘе°‘дәҶпјҢеҮ ж¬Ўд№ӢеҗҺзӣҙжҺҘеҚёиҪҪпјҢиҷҪ然е®ғзҺ°еңЁеҸ‘еұ•еҫҲеҘҪпјҢдёәдәҶдёҚжҡҙйңІиҮӘе·ұеңЁйҳ…иҜ»дёҠзҡ„жҒ¶и¶Је‘іпјҢжҲ‘еңЁиЈ…е®Ңд»Ҡж—ҘеӨҙжқЎеҗҺжІЎеӨҡд№…е°ұжҠҠе®ғз»ҷеҚёдәҶгҖӮжҺЁиҚҗз®—жі•зҰ»зңҹжӯЈзҡ„дәәе·ҘжҷәиғҪиҝҳе·®зҡ„еҫҲиҝңеҫҲиҝңпјҢе……е…¶йҮҸжҳҜзҢңдҪ е–ңж¬ўгҖӮ
еҸӘиғҪиҜҙпјҢеӨ§еӨҡж•°дәәиҝҳжҳҜе–ңж¬ўе…«еҚҰзҡ„
еӨҙжқЎеңЁжңәеҷЁеӯҰд№ пјҢжҺЁиҚҗз®—жі•дёҠжҠ•е…ҘеҫҲеӨ§пјҢдҪҶжҳҜеҪўжҲҗдә§еҮәдёҚдјҡйӮЈд№Ҳеҝ«гҖӮеӨҙжқЎзҡ„жҺЁиҚҗпјҢзӣ®еүҚеә”иҜҘдәәе·Ҙе№Ійў„зҡ„жҲҗеҲҶжӣҙеӨ§пјҢиҝҗиҗҘKPI зҡ„жҒ¶жһңзҪўдәҶ
жҳҜдёҚжҳҜеҸҜд»ҘеҲ¶е®ҡдёҖеҘ—гҖҠз®—жі•жҺЁиҚҗе’Ңжҗңзҙўеј•ж“Һзҡ„дәәе·Ҙе№Ійў„жі•еҲҷгҖӢпјҢ然еҗҺеҗ„жңәжһ„еҸҜд»Ҙж №жҚ®жі•еҲҷеҺ»зҺ©пјҢдёҚиҝҮд№ҹе°ұжҳҜж‘Ҷи®ҫпјҢдәәжҖ§еҳӣпјҢйғЁеҲҶиҝҳжҳҜиҰҒејәеҲ¶жҖ§гҖӮдҫӢеҰӮз”өеҪұеҲҶзә§д»Җд№Ҳзҡ„
еҗҙеҶӣж–°д№ҰжҸҗеҲ°дәҶпјҢдё»жөҒжҗңзҙўеј•ж“ҺзӮ№еҮ»иҙЎзҢ®йғҪеңЁ60%д»ҘдёҠ
е…¶е®һжҺЁиҚҗз®—жі•д№ҹ并йқһеҸӘжҳҜдёҖе‘іиҝҪжұӮж•°жҚ®жҢҮж Үеҗ§пјҢдёҖдёӘеҘҪзҡ„жҺЁиҚҗз®—жі•дёҚд»…д»…иҰҒжұӮиғҪеҮҶзЎ®йў„жөӢеҮәз”ЁжҲ·ж„ҹе…ҙи¶Јзҡ„еҶ…е®№пјҢиҝҳеә”иҜҘиғҪеӨҹеё®еҠ©з”ЁжҲ·жҢ–жҺҳ他们жҪңеңЁзҡ„е…ҙи¶ЈпјҢејҖжӢ“з”ЁжҲ·зҡ„зңјз•ҢпјҢд№ҹеҸӘжңүиҝҷж ·зҡ„з®—жі•жүҚиғҪи®©жҺЁиҚҗзі»з»ҹиҮӘжҲ‘жј”еҢ–еҫ—и¶ҠжқҘи¶ҠеҘҪгҖӮжҲ–и®ёзӣ®еүҚжқҘиҜҙпјҢеӨ§йғЁеҲҶдә§е“ҒиҝҳжҳҜдёҚеҫ—дёҚиҝҪжұӮеҮҶзЎ®зҺҮзӮ№еҮ»зҺҮиҝҷдәӣжҢҮж ҮпјҢдҪҶе…іжіЁиҰҶзӣ–зҺҮж–°йў–еәҰзҡ„з ”з©¶д№ҹдёҚе°‘дәҶгҖӮ
д»Ҡж—ҘеӨҙжқЎд№ҹеҸӘжҳҜжңҖиҝ‘жүҚиЈ…жқҘж— иҒҠж—¶еҲ·еҲ·пјҢеҲ·еҮ йҒҚйғҪжңӘеҝ…жңүдёҖзҜҮжғізӮ№иҝӣеҺ»зңӢпјҢжӣҙж„ҝж„ҸеңЁиұҢиұҶиҚҡдёҖи§ҲдёҠзңӢдёҖдәӣдј з»ҹеӘ’дҪ“зҡ„ж–Үз« гҖӮ
жҲ‘еңЁеӨҙжқЎзҡ„з®—жі•йҮҢд№ҹжҳҜдёӘдҪҺжҷәе•ҶпјҢдҪҺи¶Је‘ізҡ„дҝ—дәә
иҪҜиүІжғ…гҖҒжҳҺжҳҹе…«еҚҰгҖҒзӨҫдјҡеҘҮй—»гҖҒе…»иә«жҠҖе·§гҖҒйҮҺеҸІпјҢиҝҷ5зұ»жҳҜзӮ№еҮ»зҺҮдҝқйҡңпјҢй—ЁжҲ·ж—¶д»Је°ұиҝҷж ·дәҶпјҢдәәжҖ§пјҢеҸҳдёҚдәҶгҖӮ
иҝҷдёӘжҡ‘еҒҮеңЁBloombergе®һд№ еҒҡзҡ„е°ұжҳҜжңүе…іжҺЁиҚҗз®—жі•пјҢжқҘзӯ”дёҖдёӢгҖӮд»…д»…жҳҜдёүдёӘжңҲзҡ„зҗҶи§Је’Ңз§ҜзҙҜжүҖд»Ҙдјҡжңүй”ҷиҜҜе’ҢдёҚе…Ёйқўзҡ„ең°ж–№пјҢж¬ўиҝҺеӨҡеӨҡдәӨжөҒпјҒ
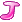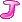 е°ұжҳҜз”ЁжҲ·iеҜ№з”өеҪұjзҡ„иҜ„еҲҶгҖӮеҸҜиғҪеӯҳеңЁпјҢд№ҹеҸҜиғҪдёҚеӯҳеңЁпјҲеҰӮжһңiжІЎзңӢиҝҮjзҡ„иҜқпјүгҖӮеҒҮи®ҫжңүmдёӘз”ЁжҲ·пјҢnдёӘз”өеҪұпјҢйӮЈд№ҲиҝҷдёӘзҹ©йҳөе°ұжҳҜm*nзҹ©йҳөгҖӮзҺ°еңЁпјҢжҲ‘们иҰҒжҠҠе®ғеҲҶи§ЈжҲҗпјҲm*fпјү * пјҲf*nпјүзҡ„дёӨдёӘзҹ©йҳөд№Ӣз§ҜгҖӮпјҲf жҳҜз”өеҪұfeatureзҡ„дёӘж•°пјү第дёҖдёӘеҸ«user matrix, 第дәҢдёӘеҸ«item matrix. йӮЈд№Ҳuser matrix жҜҸдёҖиЎҢд»ЈиЎЁзҡ„жҳҜд»Җд№Ҳе‘ўпјҡжҳҜз”ЁжҲ·еҜ№дәҺжҜҸдёӘfeatureеҲҶеҲ«зҡ„е–ңж¬ўзЁӢеәҰгҖӮжҜ”еҰӮжҲ‘们е®ҡд№үfeaturesдёә<е–ңеү§пјҢжҒҗжҖ–пјҢжӯҰжү“>, йӮЈд№Ҳз”ЁжҲ·uеңЁuser matrixзҡ„йӮЈдёҖиЎҢеҸҜиғҪжҳҜ<1.0, 0.2, -0.2>,иҝҷиҜҙжҳҺдәҶuжңҖе–ңж¬ўе–ңеү§пјҢи®ЁеҺҢжҒҗжҖ–пјҢжӣҙи®ЁеҺҢжӯҰжү“гҖӮйӮЈд№ҲеңЁitem matrixйҮҢпјҢжҜҸдёҖдёӘз”өеҪұеҸҲеҜ№еә”дәҶ他们вҖқжүҖеҗ«вҖңеҗ„дёӘfeatureзҡ„зЁӢеәҰгҖӮжҜ”еҰӮз…ҺйҘјдҫ еҸҜиғҪжҳҜ<1.0, 0, 0.2>, жҹҗдёӘжҒҗжҖ–зүҮеҸҜиғҪжҳҜ<0, 1, 0.5>. йӮЈд№ҲжҲ‘们算иҝҷдёӨдёӘеҗ‘йҮҸзҡ„зӮ№з§Ҝзҡ„иҜқпјҢеҲҶеҲ«еҫ—еҲ°M
е°ұжҳҜз”ЁжҲ·iеҜ№з”өеҪұjзҡ„иҜ„еҲҶгҖӮеҸҜиғҪеӯҳеңЁпјҢд№ҹеҸҜиғҪдёҚеӯҳеңЁпјҲеҰӮжһңiжІЎзңӢиҝҮjзҡ„иҜқпјүгҖӮеҒҮи®ҫжңүmдёӘз”ЁжҲ·пјҢnдёӘз”өеҪұпјҢйӮЈд№ҲиҝҷдёӘзҹ©йҳөе°ұжҳҜm*nзҹ©йҳөгҖӮзҺ°еңЁпјҢжҲ‘们иҰҒжҠҠе®ғеҲҶи§ЈжҲҗпјҲm*fпјү * пјҲf*nпјүзҡ„дёӨдёӘзҹ©йҳөд№Ӣз§ҜгҖӮпјҲf жҳҜз”өеҪұfeatureзҡ„дёӘж•°пјү第дёҖдёӘеҸ«user matrix, 第дәҢдёӘеҸ«item matrix. йӮЈд№Ҳuser matrix жҜҸдёҖиЎҢд»ЈиЎЁзҡ„жҳҜд»Җд№Ҳе‘ўпјҡжҳҜз”ЁжҲ·еҜ№дәҺжҜҸдёӘfeatureеҲҶеҲ«зҡ„е–ңж¬ўзЁӢеәҰгҖӮжҜ”еҰӮжҲ‘们е®ҡд№үfeaturesдёә<е–ңеү§пјҢжҒҗжҖ–пјҢжӯҰжү“>, йӮЈд№Ҳз”ЁжҲ·uеңЁuser matrixзҡ„йӮЈдёҖиЎҢеҸҜиғҪжҳҜ<1.0, 0.2, -0.2>,иҝҷиҜҙжҳҺдәҶuжңҖе–ңж¬ўе–ңеү§пјҢи®ЁеҺҢжҒҗжҖ–пјҢжӣҙи®ЁеҺҢжӯҰжү“гҖӮйӮЈд№ҲеңЁitem matrixйҮҢпјҢжҜҸдёҖдёӘз”өеҪұеҸҲеҜ№еә”дәҶ他们вҖқжүҖеҗ«вҖңеҗ„дёӘfeatureзҡ„зЁӢеәҰгҖӮжҜ”еҰӮз…ҺйҘјдҫ еҸҜиғҪжҳҜ<1.0, 0, 0.2>, жҹҗдёӘжҒҗжҖ–зүҮеҸҜиғҪжҳҜ<0, 1, 0.5>. йӮЈд№ҲжҲ‘们算иҝҷдёӨдёӘеҗ‘йҮҸзҡ„зӮ№з§Ҝзҡ„иҜқпјҢеҲҶеҲ«еҫ—еҲ°M 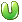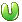 [з…ҺйҘјдҫ ] = 1-0.04 = 0.96 M
[з…ҺйҘјдҫ ] = 1-0.04 = 0.96 M 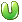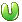 [жҒҗжҖ–зүҮ] = 0.2-0.1=0.1. йӮЈд№Ҳиҝҷж ·uиӮҜе®ҡе°ұдјҡжӣҙе–ңж¬ўз…ҺйҘјдҫ е•ҰпјҒиҝҷдёӘж–№жі•Simon FunkиҝҷдёӘдәәзҡ„з®—жі•жңҖеҝ«гҖӮеҸҜд»ҘжҗңдёҖдёӢгҖӮиҝҳеҸҜд»Ҙз»ҷд»–жң¬дәәеҸ‘йӮ®д»¶гҖӮгҖӮгҖӮиҝҷдёӘж–№жі•жңҖеӨҙз–јзҡ„е°ұжҳҜMйҮҢжңүз”Ёзҡ„еӨӘе°‘пјҢжҜ”еҰӮдёҖдёӘдәәдёҖиҫҲеӯҗе°ұзӮ№иҜ„иҝҮдёҖдёӘз”өеҪұпјҢйӮЈжҖҺд№ҲжҺЁиҚҗеҳӣгҖӮгҖӮгҖӮиҝҷз§Қжғ…еҶөе°ұиҰҒз”ЁжҲ‘们зҡ„content-basedдәҶпјҢеӣ дёәе…¶д»–зҡ„д»»дҪ•з®—жі•йғҪжҳҜе»әз«ӢеңЁжҲ‘们жңүи¶іеӨҹзҡ„user interactionзҡ„еүҚжҸҗдёӢзҡ„гҖӮ
[жҒҗжҖ–зүҮ] = 0.2-0.1=0.1. йӮЈд№Ҳиҝҷж ·uиӮҜе®ҡе°ұдјҡжӣҙе–ңж¬ўз…ҺйҘјдҫ е•ҰпјҒиҝҷдёӘж–№жі•Simon FunkиҝҷдёӘдәәзҡ„з®—жі•жңҖеҝ«гҖӮеҸҜд»ҘжҗңдёҖдёӢгҖӮиҝҳеҸҜд»Ҙз»ҷд»–жң¬дәәеҸ‘йӮ®д»¶гҖӮгҖӮгҖӮиҝҷдёӘж–№жі•жңҖеӨҙз–јзҡ„е°ұжҳҜMйҮҢжңүз”Ёзҡ„еӨӘе°‘пјҢжҜ”еҰӮдёҖдёӘдәәдёҖиҫҲеӯҗе°ұзӮ№иҜ„иҝҮдёҖдёӘз”өеҪұпјҢйӮЈжҖҺд№ҲжҺЁиҚҗеҳӣгҖӮгҖӮгҖӮиҝҷз§Қжғ…еҶөе°ұиҰҒз”ЁжҲ‘们зҡ„content-basedдәҶпјҢеӣ дёәе…¶д»–зҡ„д»»дҪ•з®—жі•йғҪжҳҜе»әз«ӢеңЁжҲ‘们жңүи¶іеӨҹзҡ„user interactionзҡ„еүҚжҸҗдёӢзҡ„гҖӮ
жҺЁиҚҗз®—жі•жңҖдј з»ҹзҡ„жңүдёӨзұ»пјҢcontent-basedе’Ңcollaborative filtering.
1. content based(е°ұз®Җз§°д»–CB)пјҡ
content based, йЎҫеҗҚжҖқд№үпјҢе°ұжҳҜдё»иҰҒиҖғиҷ‘дёҖдёӘе•Ҷе“Ғеӣәжңүзҡ„еҶ…еңЁеұһжҖ§гҖӮеҜ№дәҺжҜҸдёӘе•Ҷе“Ғitem, йңҖиҰҒе»әз«Ӣitemзҡ„profile.еҜ№дәҺжҜҸдёӘз”ЁжҲ·,иҰҒе»әз«Ӣuser profile. дёҫдёӘдҫӢеӯҗпјҢдҪ еңЁзҹҘд№ҺдёҠжҗңзҙўиҝҮзј–зЁӢпјҢжҗңзҙўиҝҮзҫҺйЈҹпјҢйӮЈд№ҲдҪ зҡ„user profileе°ұдјҡжҳҫзӨәдҪ жҳҜеҜ№зј–зЁӢпјҢзҫҺйЈҹж„ҹе…ҙи¶Јзҡ„гҖӮйӮЈд№ҲеҒҮеҰӮжҲ‘们жҠҠitem profileз®ҖеҚ•зҡ„зңӢжҲҗжҜҸдёӘй—®йўҳзҡ„tagsзҡ„иҜқпјҢйӮЈд№Ҳжңүзј–зЁӢпјҢжҲ–иҖ…зҫҺйЈҹзҡ„ж Үзӯҫзҡ„й—®йўҳдҪ еҫҲеҸҜиғҪж„ҹе…ҙи¶ЈгҖӮ
CBеҒҡзҡ„жңҖеҘҪзҡ„жҳҜPandora, 他们жңҖжңүеҗҚзҡ„music genome projectжҳҜдәәе·Ҙж Үи®°дёҖйҰ–жӯҢжӣІзҡ„profile
2. collaborative filtering(cf):
cfзҡ„зІҫй«“жҳҜеңЁдәҺд»–з”ЁвҖңе’Ңз”ЁжҲ·xзӣёдјјзҡ„з”ЁжҲ·зҡ„иҙӯд№°д№ жғҜжҺЁжөӢxжғіиҰҒиҙӯд№°зҡ„дёңиҘҝгҖӮз»ҶеҲҶзҡ„иҜқcfз®—жі•жңүuser-basedе’Ңitem-based. user-basedеҸҜд»Ҙиҝҷж ·и§ЈйҮҠпјҡжғіиҰҒзҹҘйҒ“жҲ‘еҜ№вҖқжңүдёҖеҸҢзҫҺи…ҝжҳҜд»Җд№ҲдҪ“йӘҢвҖңиҝҷдёӘй—®йўҳзҡ„е–ңеҘҪзЁӢеәҰпјҢйҖҡиҝҮеҜ№жҜ”жҲ‘зҡ„е’Ңе…¶д»–дәәзҡ„йҳ…иҜ»и®°еҪ•пјҢеҸ‘зҺ°жҲ‘е’ҢеҸҰеӨ–100дёӘзҹҘд№Һз”ЁжҲ·еҫҲеғҸпјҢйғҪиҜ»дәҶеҫҲеӨҡзј–зЁӢе’ҢзҫҺйЈҹж–№йқўзҡ„й—®йўҳгҖӮиҖҢиҝҷдёӯй—ҙ99дёӘдәәйғҪиҜ»дәҶвҖқжңүдёҖеҸҢзҫҺи…ҝжҳҜд»Җд№ҲдҪ“йӘҢвҖңпјҢиҝҳеңЁдёҠйқўеҒңз•ҷдәҶеҫҲд№…пјҢе°Өе…¶жҳҜжңүеӣҫзҡ„еӣһзӯ”гҖӮгҖӮгҖӮйӮЈд№Ҳеӣ жӯӨеҸҜд»ҘжҺЁж–ӯжҲ‘д№ҹдјҡе–ңж¬ўиҝҷдёӘй—®йўҳгҖӮcfжңҖйҡҫзҡ„й—®йўҳеңЁдәҺжҖҺд№ҲеҜ»жүҫвҖқжңҖзӣёдјјзҡ„з”ЁжҲ·вҖңгҖӮеңЁmachine learningйҮҢиҝҷдёӘе°ұжҳҜk nearest neighbor. жҲ‘е°қиҜ•зҡ„з®—жі•еҸ«locality sensitive hashing with minhashing. дёҚзҹҘйҒ“иҝҳжңүд»Җд№ҲеҲ«зҡ„ж–№жі•гҖӮ
CFзҡ„иҜқжҜ”еҰӮamazon, дҪ дјҡз»ҸеёёзңӢеҲ°user who bought this also bought that…
й—®йўҳпјҡ
еҸҜжҳҜй—®йўҳеҸҲжқҘдәҶпјҢеҰӮжһңд»”з»ҶжғідёҖдёӢе°ұзҹҘйҒ“еҲҡжүҚcfеҒҡзҡ„дәӢжғ…дёҚеӨӘеҜ№гҖӮдёәд»Җд№Ҳе‘ўпјҢеӣ дёәеҮ д№ҺжүҖжңүзҹҘд№Һз”ЁжҲ·йғҪзҲұиҜ»жңүдёҖеҸҢзҫҺи…ҝжҳҜд»Җд№ҲдҪ“йӘҢпјҢзҲұзңӢеӣҫпјҢиҝҷдёӘдёңиҘҝдёҚжҳҜзҲұзҫҺйЈҹзҡ„зЁӢеәҸе‘ҳиҝҷдәӣдәәзү№жңүзҡ„пјҢжүҖд»ҘжҲ‘иҷҪ然еҫҲеҸҜиғҪж„ҹе…ҙи¶ЈпјҢдҪҶжҳҜ并дёҚжҳҜеӣ дёәcfзҡ„еҠҹеҠіпјҢиҖҢжҳҜиҝҷдёӘй—®йўҳжң¬иә«е°ұеҫҲеҸ—ж¬ўиҝҺгҖӮиҝҷеңЁжҺЁиҚҗз®—жі•дёӯеҸ«еҒҡbanana problem.еҺҹеӣ жҳҜеңЁзҫҺеӣҪиҝҷиҫ№зҡ„и¶…еёӮпјҢеҮ д№ҺжүҖжңүдәәйғҪзҲұд№°banana,еӣ дёәжңҖдҫҝе®ңпјҢд№ҹеҘҪеҗғд№ҹеҒҘеә·гҖӮжүҖд»ҘиҝҮеӨҡзҡ„ж•°жҚ®йҮҸеҸҜиғҪдјҡеҜјиҮҙдёҖдёӘи¶…еёӮжҺЁиҚҗз®—жі•з–ҜзӢӮжҺЁиҚҗBananaз»ҷжүҖжңүдәәгҖӮиҝҷжҳҜдёҖдёӘйңҖиҰҒи§ЈеҶізҡ„й—®йўҳпјҢжҜ”еҰӮжҺЁиҚҗеӨ§е®¶йғҪзҲұзңӢзҡ„з»Ҹе…ёз”өеҪұеҸҜиғҪжІЎй”ҷпјҢдҪҶжҳҜжҺЁиҚҗйҰҷи•үз»ҷжқҘи¶…еёӮзҡ„пјҢжҺЁиҚҗеҸЈйҰҷзі–з»ҷдёҖдёӘдёҖе‘Ёд№°дә”ж¬ЎеҸЈйҰҷзі–зҡ„еҸҜиғҪе°ұжІЎд»Җд№Ҳз”ЁгҖӮ
3.matrix factorization
еҮ е№ҙд»ҘеүҚnetflixжңүиҝҮиҝҷж ·дёҖдёӘз«һиөӣпјҢи°Ғзҡ„жҺЁиҚҗз®—жі•жҜ”д»–зҡ„зүӣйҖј10%,е°ұиғҪжӢҝиө°дёҖеӨ§з¬”еҘ–йҮ‘пјҢеҘҪеғҸжҳҜ100wзҫҺйҮ‘гҖӮиҝҷдёӘз«һиөӣдёӯйЈҺйқЎзқҖиҝҷж ·дёҖз§Қзҹ©йҳөеҲҶи§Јзҡ„з®—жі•гҖӮпјҲ2012е№ҙзҡ„ж•°жҚ®пјҢnetflix 75%зҡ„и§ӮзңӢйҮҸжҳҜд»ҺжҺЁиҚҗеј•ж“ҺйҮҢжқҘзҡ„пјҢиҝҷд№ҹе°ұжҳҜдёәд»Җд№Ҳ他们йӮЈд№ҲжіЁйҮҚжҺЁиҚҗз®—жі•пјү
жҲ‘们жғіиұЎиҝҷж ·дёҖдёӘзҹ©йҳөMпјҢжҜҸдёҖиЎҢд»ЈиЎЁдёҖдёӘз”ЁжҲ·пјҢжҜҸдёҖеҲ—д»ЈиЎЁдёҖдёӘз”өеҪұгҖӮйӮЈд№ҲM
ж•°жҚ®пјҡдёҚеҗҢзҡ„ж•°жҚ®йҖӮеә”дёҚеҗҢзҡ„з®—жі•гҖӮдҫӢеҰӮеҸӘжңүз”ЁжҲ·зҡ„иЎҢдёәж•°жҚ®пјҲдҫӢеҰӮиҙӯд№°гҖҒжҹҘзңӢзӯүдәӨдә’ж•°жҚ®пјүпјҢеҲҷеҸӘиғҪйҖүз”Ёз®ҖеҚ•зҡ„з®—жі•пјҲдҫӢеҰӮеҚҸеҗҢиҝҮж»ӨпјҢеҹәдәҺзү©иҙЁжү©ж•Јзҡ„з®—жі•зӯүпјүпјҢеҰӮжһңеҢ…еҗ«з”ЁжҲ·жҲ–зү©е“ҒдҝЎжҒҜпјҢеҸҜд»ҘйҖүз”ЁиҫғдёәеӨҚжқӮзҡ„з®—жі•гҖӮдёҖиҲ¬жқҘиҜҙпјҢдҪҝз”Ёзҡ„дҝЎжҒҜи¶ҠеӨҡпјҢеҫ—еҲ°зҡ„з»“жһңи¶ҠзІҫеҮҶгҖӮ
дә§е“Ғзұ»еһӢпјҡжҜҸдёӘжҺЁиҚҗзі»з»ҹжүҖй’ҲеҜ№зҡ„дә§е“ҒдёҚеҗҢпјҲдҫӢеҰӮд№°е•Ҷе“Ғзҡ„е’ҢжҺЁиҚҗз”өеҪұзҡ„пјүпјҢжүҖйҖүз”Ёзҡ„з®—жі•д№ҹеә”иҜҘжҳҜдёҚе°ҪзӣёеҗҢзҡ„пјҢе°ҪйҮҸеҲ©з”ЁжүҖеңЁдә§е“Ғзі»з»ҹиҮӘиә«зҡ„зү№зӮ№гҖӮ
еҶ·еҗҜеҠЁ пјҡеңЁжҺЁиҚҗз®—жі•еҗҜеҠЁеҲқжңҹзҡ„ж•°жҚ®жҳҜеҗҰеӨҹпјҢеҜ№ж–°з”ЁжҲ·е’Ңж–°дә§е“ҒжҳҜеҗҰд№ҹиғҪиҝӣиЎҢжҺЁиҚҗгҖӮ
жҖ§иғҪпјҡжҳҜеҗҰйңҖиҰҒе®һж—¶жҺЁиҚҗгҖӮйқһе®һж—¶жҺЁиҚҗеҜ№жҖ§иғҪзҡ„иҰҒжұӮжҜ”иҫғдҪҺпјҢеҲҷеҸҜд»ҘйҖүз”ЁиҫғеӨҚжқӮзҡ„з®—жі•гҖӮе®һж—¶жҺЁиҚҗеҲҷеҜ№жҖ§иғҪиҰҒжұӮжҜ”иҫғй«ҳпјҢдёҖиҲ¬йҖүжӢ©еӨҚжқӮеәҰиҫғдҪҺзҡ„з®—жі•гҖӮ
еӨҡж ·жҖ§пјҡзІҫеәҰе’ҢеӨҡж ·жҖ§зҡ„й—®йўҳгҖӮеңЁзІҫеәҰиҫҫеҲ°иҰҒжұӮзҡ„жғ…еҶөдёӢеҸҜд»ҘиҖғиҷ‘жҺЁиҚҗзҡ„еӨҡж ·жҖ§гҖӮ
дёҖдёӘеҘҪзҡ„жҺЁиҚҗзі»з»ҹпјҢе…¶е®һйңҖиҰҒдә§е“Ғе’Ңз®—жі•зҡ„е…ұеҗҢдҪңз”ЁгҖӮ
еҘҪзҡ„еҒҡдәӢзҡ„ж–№жі•и®әеә”иҜҘжҳҜ
1.дә§е“ҒжҸҸиҝ°е’Ңе®ҡд№үзӣ®ж Үз»“жһңйӣҶ
еҫҲеӨҡдёҚжҮӮз®—жі•зҡ„дә§е“ҒдјҡеңЁиҝҷдёҠзҠҜй”ҷпјҢе°ҶжҸҗеҚҮдә§е“Ғж•Ҳжһңе…ЁйғЁжҺЁз»ҷи·қзҰ»дёҡеҠЎзӣёеҜ№иҫғиҝңзҡ„з®—жі•дәәе‘ҳпјҢиҖҢдё”еҸӘдјҡиҰҒжұӮжүҖи°“зІҫеҮҶпјҢиҝҷе…¶е®һжҳҜдёҚжҮӮ+дёҚиҙҹиҙЈд»»зҡ„иЎЁзҺ°
дә§е“ҒйңҖиҰҒж·ұе…ҘзҗҶи§ЈжҹҗдёӘжҺЁиҚҗзі»з»ҹдёӯпјҢз”ЁжҲ·е®һйҷ…зҡ„йңҖжұӮеҶ…е®№жҳҜд»Җд№ҲпјҢд»Җд№Ҳж ·з”ЁжҲ·е–ңж¬ўеҸ‘ж•Јзҡ„пјҢд»Җд№Ҳж ·з”ЁжҲ·е–ңж¬ўйӣҶдёӯзҡ„пјҢд»Җд№Ҳж ·з”ЁжҲ·е–ңж¬ўзғӯй—Ёзҡ„гҖӮиҝҳжҳҜз”ЁжҲ·иЎҢдёәеҹәжң¬ж— е·®ејӮпјҹеҰӮжһңдҪ жҳҜз®ҖеҚ•зҡ„жҺЁиҚҗitemи®©з”ЁжҲ·еҺ»зӮ№еҮ»пјҢйӮЈд№ҲеҪұе“ҚзӮ№еҮ»зҡ„иҝҷдәӣitemзҡ„зү№еҫҒеҲ°еә•жҳҜд»Җд№ҲпјҢжјӮдә®зҡ„еӣҫж Үпјҹе…·жңүзү№ж®ҠйЈҺж јзҡ„summaryд»Ӣз»Қж–ҮжЎҲпјҹеҗ»еҗҲз”ЁжҲ·дёӘжҖ§еҢ–зҡ„иҝҮеҫҖзҡ„дҪҝз”Ёи®°еҪ•пјҹжҳҜз”ЁжҲ·зҡ„еҘҪеҸӢдҪҝз”ЁиҝҮзҡ„并иҜ„д»·иүҜеҘҪзҡ„пјҹиҝҳжҳҜйҡҸдҫҝд»Җд№ҲеҶ…е®№ж”ҫдёҠеҺ»е°ұжңүзӮ№еҮ»пјҢжҺЁиҚҗзі»з»ҹеңЁжӯӨз”ЁдёҚдёҠпјҹ
еҰӮжһңPMеҜ№з”ЁжҲ·йңҖжұӮе’Ңitemзү№иҙЁе»әз«ӢдёҚдәҶзі»з»ҹеҢ–з»“жһ„еҢ–зҡ„жЁЎеһӢпјҢеҜ№з”ЁжҲ·дҪҝз”ЁиЎҢдёәзҡ„иғҢеҗҺеҠЁжңәжІЎжңүж·ұе…Ҙзҡ„жҖқиҖғпјҢеҹәжң¬дёҠжҳҜеҒҡдёҚеҮәеҘҪзҡ„жҺЁиҚҗзі»з»ҹзҡ„пјҢиө·и·‘зәҝдёҠе°ұиҫ“дәҶгҖӮ
е…үдјҡйҖјйҖјеҸЁ зІҫеҮҶ е•ҠпјҢ еҘҪ е•Ҡиҝҷз§ҚжЁЎзіҠдё”иҝ‘дјјеәҹиҜқзҡ„еҪўе®№иҜҚд№ҹжІЎд»Җд№Ҳз”ЁгҖӮ
2.е…ұеҗҢзҗҶи§ЈжҺЁиҚҗзі»з»ҹзҡ„е®һзҺ°ж–№ејҸ
е…үжңү第дёҖжқЎиҝҳдёҚи¶ід»ҘиҗҪең°пјҢ第дёҖжқЎжӣҙеӨҡзҡ„ж—¶еҖҷжҳҜе®ҡжҖ§зҡ„жҸҸиҝ°пјҢжҲ–зІ—жө…зҡ„е®ҡйҮҸпјҲжҜ”еҰӮд»Җд№ҲеӨ§дәҺд»Җд№ҲпјүпјҢзҰ»е®һйҷ…иҗҪең°зҡ„ж•ҲжһңиҝҳеҫҲжңүи·қзҰ»гҖӮиҝҷж—¶еҖҷжҮӮз®—жі•зҡ„е·ҘзЁӢеёҲйңҖиҰҒеҮә马гҖӮ
жҲ‘и§үеҫ—з®—жі•еҸҜд»ҘжӢҶжҲҗдёӨз§ҚпјҢдёҖз§ҚжҳҜ规еҲҷжҲ–зӯ–з•ҘпјҢдёҖз§ҚжҳҜжңәеҷЁеӯҰд№ зҡ„еӨҚжқӮз®—жі•
еҜ№дәҺеӨҙдёҖз§ҚпјҢйңҖиҰҒдә§е“Ғе’Ңз®—жі•еҜ№и§„еҲҷзҡ„е…ұеҗҢзҗҶи§ЈгҖӮжҜ”еҰӮжҲ‘жғіиҰҒдёҖдёӘжҖ»иөһжҲҗзҘЁе’ҢеҸҚеҜ№зҘЁзҡ„е…ізі»пјҢйӮЈд№ҲжҳҜиөһжҲҗзҘЁ-еҸҚеҜ№зҘЁеҘҪпјҢиҝҳжҳҜиөһжҲҗзҘЁ/еҸҚеҜ№зҘЁеҘҪпјҢиҝҳжҳҜlog(иөһжҲҗзҘЁ/еҸҚеҜ№зҘЁ)еҘҪпјҢиҝҳжҳҜиөһжҲҗзҘЁ/пјҲеҸҚеҜ№зҘЁ+cпјүеҘҪпјҢиҝҷйҮҢйқўе…¶е®һе·®ејӮиҝҳжҳҜдёҚе°Ҹзҡ„пјҢз®—жі•е·ҘзЁӢеёҲеҸҜд»Ҙеё®дә§е“ҒеӨҡиҖғиҷ‘жһҒз«Ҝзҡ„ж•°еҖјжғ…еҶөпјҢе°ҶжЁЎзіҠзҡ„规еҲҷжҸҸиҝ°дёәзІҫзЎ®зҡ„еҸҜи®Ўз®—зҡ„ж•°еӯҰжЁЎеһӢгҖӮеҘҪзҡ„жЁЎеһӢеә”иҜҘе…је…·ж•Ҳжһңе’Ңи§ЈйҮҠжҖ§пјҢе·ҘдёҡзҺҜеўғдёӢжңүдёӘеҫҲйҮҚиҰҒйңҖжұӮе°ұжҳҜиҖҒжқҝ们еҸ‘зҺ°дёҖдёӘcaseпјҢдҪ иҮіе°‘иғҪи§ЈйҮҠзҡ„йҖҡжҳҜжЁЎеһӢй—®йўҳиҝҳжҳҜж•°жҚ®й—®йўҳеҗ§
еҜ№дәҺ第дәҢз§ҚпјҢз”ұдәҺе®һйҷ…иҝҗиЎҢиө·жқҘи§ЈйҮҠжҖ§еҫҲе·®пјҢдёӘдәәе»әи®®з”ЁжқҘеҒҡжңҖдҪҺеұӮжңҖйҖҡз”Ёзҡ„дёҖдәӣеӨ„зҗҶе°ұеҘҪпјҢ然еҗҺйҖҡиҝҮеӨ§йҮҸзҡ„caseиҜ„жөӢжқҘеҜ№ж•ҲжһңиҝӣиЎҢиҜ„дј°гҖӮжҜ”еҰӮжҠҠSVMжһ„йҖ жҲҗж–Үжң¬еҲҶзұ»еҷЁд№Ӣзұ»гҖӮ
жҖ»д№Ӣе°ұжҳҜжңәеҷЁеӯҰд№ з®—жі•дҪңдёәеә•еұӮе’ҢйҖҡз”Ёзҡ„жЁЎеқ—еҗ‘дёӢжІүйҷҚпјҢдёҠж–№з”ЁеӨ§е®¶йғҪеҸҜзҗҶи§Јзҡ„з®ҖеҚ•и§„еҲҷж №жҚ®еңәжҷҜдёҚеҗҢзҒөжҙ»и°ғй…ҚгҖӮ
3.е®һйҷ…зәҝдёҠжҺЁиҚҗж•Ҳжһңзҡ„жЈҖйӘҢ
дёҖеҲҮдәӢеүҚзҡ„йӘҢиҜҒйғҪдёҚеҰӮдәӢеҗҺйӘҢиҜҒжқҘзҡ„йқ и°ұгҖӮ
еҜ№дәҺзҹӯжңҹе’Ңз«ӢеҚіи§Ғж•Ҳзҡ„caseпјҢи®°еҫ—жөҒйҮҸиҰҒеҲҮзҡ„еқҮеҢҖпјҢдё”дҝқжҢҒеҚ•дёҖеҸҳйҮҸпјҲж”№еҠЁпјүеҺҹеҲҷ
еҜ№дәҺй•ҝжңҹжүҚиғҪи§Ғж•Ҳзҡ„case…иҜҙжңҚиҖҒжқҝз»ҷи¶іеӨҹеӨҡзҡ„ж—¶й—ҙжқҘзӯү
еҜ№дәҺж•°жҚ®еҸҳеҢ–дёҚжҳҺжҳҫзҡ„caseпјҢиҰҒд№ҲдҪңдёәдёҖдёӘдҪ“йӘҢж”№иҝӣпјҢеҪ“еҒҡиүҜеҝғжҙ»еҒҡпјҢиҰҒд№Ҳе°ұйҖҡиҝҮbad caseзҺҮжқҘз»ҷж•ҲжһңеҒҡжЈҖжөӢгҖӮ
4.еҜ№е®һйҷ…иҝҗиЎҢз»“жһңзҡ„и§ЈиҜ»еҸҠд»ҺдёӯжүҫеҲ°ж”№иҝӣзӮ№
иҝҷдёӘеӨӘcase by caseдәҶгҖӮдёҚиҝҮжҲ‘жҜ”иҫғи®ӨеҸҜзҡ„зҗҶеҝөжҳҜпјҡиҝҗиЎҢз»“жһңд»ЈиЎЁеҜ№дёҠдёҖж¬ЎжӢҚи„‘иўӢиЎҢдёәзҡ„иӮҜе®ҡжҲ–жү“и„ёпјҢйҖҡиҝҮиҝҗиЎҢз»“жһңдҪ жІЎжі•зӣҙжҺҘеҫ—еҲ°дёҖе®ҡиғҪжңүж•Ҳжһңзҡ„ж”№иҝӣгҖӮж”№иҝӣд»Қ然жҳҜдёҖз§Қзұ»дјјж„ҹжҖ§зҡ„жӢҚи„‘иўӢзҡ„й©ұеҠЁж–№ејҸпјҢжҲ‘们е°ұжҳҜдёҚж–ӯзҡ„жӢҚи„‘иўӢпјҢ然еҗҺдёҚж–ӯзҡ„жЈҖжөӢжӢҚи„‘иўӢзҡ„жҲҗжһңгҖӮеҘҪзҡ„еҶізӯ–жҳҜз”Ёж•°жҚ®жІЎжі•е…ҲйӘҢеҫ—еҮәзҡ„гҖӮ
5.и·іеҮәжҖқз»ҙеұҖйҷҗпјҢжүҫеҲ°еӨ§еҲӣж–°
д»ҘдёҠ4дёӘжҳҜжҲ‘и®ӨдёәеҘҪзҡ„е·ҘдҪңжөҒзЁӢгҖӮдҪҶжҳҜжҳҜеҜ№дёҖиҲ¬зі»з»ҹзҡ„ж”№иҝӣжқҘиҜҙзҡ„пјҢеҫҲеӨҡж—¶еҖҷжҲ‘们иҰҒи§Јж”ҫжҺЁиҚҗгҖӮжҜ”еҰӮпјҢж”ҫзӣёе…іжӯҢжӣІжҳҜжҺЁиҚҗпјҢиұҶз“Јз”өеҸ°д№ҹжҳҜжҺЁиҚҗпјҢжҠҠжүҖжңүжӯҢжүӢи·‘жҲҗдёҖеј ең°еӣҫи®©з”ЁжҲ·жЁЎзіҠзҡ„еҺ»йҖүжӢ©д№ҹеҸҜд»ҘжҳҜдёҖз§ҚжҺЁиҚҗпјҢз®—жі•зҡ„еҠӣйҮҸпјҢд№ҹи®ёжҚўдёҖз§Қдә§е“ҒеҪўжҖҒпјҢе°ұдјҡжңүйЈһи·ғзҡ„ж”№иҝӣгҖӮиҝҷжҳҜдҪ еҫ®и°ғеӨ§еҚҠеӨ©д№ҹдёҚдёҖе®ҡжҗһеҫ—еҮәжқҘзҡ„гҖӮ
PS.зҹҘд№Һзҡ„жҺ’еәҸ规еҲҷжңүдәӣең°ж–№дёҚеӨҹеҘҪпјҢжҲ‘зҢңзҹҘд№ҺеҸҜиғҪжІЎжңүеҜ№з”ЁжҲ·еңЁжҹҗдёҖйўҶеҹҹзҡ„жқғеЁҒеәҰиҝӣиЎҢе»әжЁЎгҖӮжүҖд»ҘеңЁд№ӢеүҚи®Ёи®әвҖқдё“дёҡе’ҢдёҡдҪҷвҖңзҡ„й—®йўҳж—¶пјҢжңүдәәиҜҙзӯ”дёҖдёӘиҮӘе·ұдёҡдҪҷзҡ„й—®йўҳеҫ—зҘЁжҜ”иҮӘе·ұдё“дёҡй—®йўҳиҝҳзҒ«зҡ„жғ…еҶөгҖӮиҖҢдё”зӣ®еүҚи¶Ҡж—©еӣһзӯ”зҡ„й—®йўҳеҫ—зҘЁи¶ҠжңүдјҳеҠҝгҖӮиҝҷдәӣйғҪжҳҜй—®йўҳпјҢйғҪйңҖиҰҒж”№
е…¶е®һжңүдёҖж®өж—¶й—ҙеҶҚеҒҡиҪҜ件зҡ„жҺЁиҚҗж–№жі•пјҢеҒҡзҡ„ж—¶еҖҷжңҖзә з»“зҡ„е°ұжҳҜжҜҸдёӘдәәзӮ№ејҖдёҖдёӘappзҡ„ж—¶еҖҷд»–зҡ„йңҖжұӮзӮ№йғҪжҳҜдёҚеҗҢзҡ„пјҢжүҖд»ҘдјҡжңүеҫҲеӨҡжӯ§д№үпјҢзҺ°еңЁи§үеҫ—иҝҳжҳҜжІЎжңүеҒҡеҫ—еҫҲи®©дәәж»Ўж„ҸпјҢдёҚиҝҮе…¶дёӯжңүеҮ дёӘзӮ№еҸҜд»ҘеҲҶдә«дёҖдёӢпјҡ
1 жҖҺд№ҲдёәжҜҸдёӘеә”з”ЁзЎ®е®ҡж ҮзӨәз¬ҰпјҢд»ҘеҸҠдёәжҜҸдёӘеә”з”ЁиҙҙдёҠж ҮзӨәз¬Ұзҡ„ж—¶еҖҷйЎәеәҸжҳҜеҗҰйҮҚиҰҒпјҢеҗҺйқўиҝҷдёӘй—®йўҳе…¶е®һд№ҹе°ұж¶үеҸҠеҲ°дҪ еҗҺйқўзҡ„з®—жі•жҳҜеҗҰиҰҒжҠҠж ҮиҜҶз¬Ұзҡ„йЎәеәҸиҖғиҷ‘иҝӣеҺ»дәҶпјҢеӣ дёәжҜҸдёӘдәәзӮ№ејҖappж—¶иў«еҗёеј•зҡ„зӮ№йғҪдёҚдёҖж ·пјҢжңүзҡ„дәәжҳҜеӣ дёәappзҡ„зҺ©жі•пјҢжңүзҡ„дәәжҳҜеӣ дёәappзҡ„дё»и§’пјҢжңүзҡ„дәәжҳҜе–ңж¬ўappзҡ„йЈҺж јпјҢжүҖд»ҘжңҖеҗҺзЎ®е®ҡзҡ„жҳҜеҰӮжһңappжҳҜжёёжҲҸзҡ„иҜқе°ұж №жҚ®пјҡзҺ©жі•пјҢзү№иүІгҖҗжҜ”еҰӮжҳҜ3Dзҡ„пјҹе®һжҷҜзҡ„пјҹгҖ‘пјҢдё»и§’зҡ„йЎәеәҸжқҘдёәз»ҷдёӘappжү“дёҠж ҮзӨәз¬Ұ
2 ж №жҚ®иҮӘе·ұз”ЁжҲ·зҡ„зү№зӮ№пјҢжҠҠжҸЎеӨ§зҡ„ж–№еҗ‘пјҢеӣ дёәapp storeзҡ„еә”з”Ёеҗ„з§Қеҗ„ж ·еҘҮејӮеҠҹиғҪзҡ„йғҪжңүпјҢиҖҢдё”зұ»еһӢд№ҹдјҡи¶ҠжқҘи¶ҠеӨҡпјҢжүҖд»ҘжҢҒз»ӯзҡ„з»ҙжҠӨжӣҙж–°ж ҮиҜҶз¬ҰжҳҜдёҖдёӘдёҖзӣҙиҰҒеҒҡзҡ„е·ҘдҪңпјҢдҪҶжҳҜзЎ®е®ҡ第дёҖжү№зҡ„ж—¶еҖҷеҸҜд»ҘзҺ°жҠ“еӨ§зҡ„пјҢжҜ”еҰӮжёёжҲҸзҡ„иҜқпјҡз©әжҲҳпјҢй…·и·‘пјҢиөӣиҪҰпјҢе°„еҮ»пјҢеЎ”йҳІзӯүеҮ дёӘеӨ§зұ»еҹәжң¬дёҠеҸҜд»Ҙж¶өзӣ–дәҶжёёжҲҸзҡ„80%д»ҘдёҠпјҢжүҖд»ҘеӨ§зҡ„зұ»еҲ«дёҖе®ҡиҰҒдҝқиҜҒе…ЁйғЁиҰҶзӣ–пјҢе°Ҹзҡ„еҸҜд»Ҙж…ўж…ўиЎҘе……
3 иҖғиҷ‘дёҚеҗҢж ҮиҜҶз¬Ұзҡ„дјҳе…Ҳзә§д»ҘеҸҠеңЁз»“жһңдёӯжүҖеҚ зҡ„жҜ”дҫӢпјҢжҜ”еҰӮдҪ дёәдёҖдёӘеә”з”ЁиҙҙдёҠдәҶ4дёӘж ҮзӨәз¬ҰпјҢ他们д№Ӣй—ҙзҡ„дјҳе…Ҳзә§жҳҜжҖҺд№Ҳж ·зҡ„пјҹжҳҜжҢүз…§йЎәеәҸдёҖдёӘдёҖдёӘзҡ„еҢ№й…ҚпјҢиҝҳжҳҜйғҪе…ЁйғЁеҢ№й…ҚдҪҶжҳҜдёҚеҗҢзҡ„ж ҮзӨәз¬ҰеңЁз»“жһңжүҖеҚ зҡ„жҜ”дҫӢдёҚеҗҢ
4 е…¶д»–з»ҙеәҰзҡ„иҖғиҷ‘пјҢдё»иҰҒиҝҳжҳҜж №жҚ®дҪ зҡ„дә§е“Ғзү№жҖ§жқҘе®ҡпјҢеҜ№дәҺappзҡ„иҜқпјҢжҜ”еҰӮж №жҚ®дҪ еүҚжңҹзҡ„еҢ№й…Қе·Із»Ҹдёәз”ЁжҲ·жҢ‘еҮәдәҶдёҖжү№зӣёеә”зҡ„еә”з”ЁпјҢжҳҜзӣҙжҺҘе°ұеұ•зӨәз»ҷз”ЁжҲ·дәҶиҝҳжҳҜеҶҚиҝӣиЎҢдёӢдёҖжӯҘзҡ„еӨ„зҗҶпјҢиҰҒдёҚиҰҒеҠ е…Ҙж—¶й—ҙзҡ„иҖғиҷ‘пјҢеҸӘжҺЁиҚҗиҝ‘жңҹзғӯй—Ёзҡ„пјҢиҰҒдёҚиҰҒеҠ е…Ҙд»·ж јзҡ„иҖғиҷ‘пјҢжҺЁиҚҗеҮәзҡ„еә”з”ЁйҮҢйқўжҳҜдёҚжҳҜеә”иҜҘжҠҠ收иҙ№зҡ„жҺ§еҲ¶еңЁдёҖе®ҡзҡ„жҜ”дҫӢзӯүзӯү
5 иҝҳжңүе°ұжҳҜеҖҷиЎҘзҡ„ж–№жі•пјҢеҪ“жңүдёҖдёӘеә”з”Ёзҡ„ж ҮиҜҶз¬ҰжІЎжңүи¶іеӨҹзҡ„еә”з”Ёи·ҹд»–зӣёеҢ№й…Қзҡ„ж—¶еҖҷжҖҺд№ҲеҠһпјҹжҳҜж №жҚ®еҗҚеӯ—зҡ„йҮҚеҗҲеәҰжҺЁиҚҗпјҹиҝҳжҳҜеҸ–и·ҹд»–еҗҢеҲҶзұ»зҡ„зғӯй—Ёеә”з”Ё
зҺ°еңЁзҡ„жңәеҷЁдәәиҝҗеҠЁжҺ§еҲ¶пјҢеҹәжң¬дёҠйғҪжҳҜй’ҲеҜ№жҹҗдёҖдёӘжҲ–жҹҗдёҖзұ»еҠЁдҪңиҝӣиЎҢи®ҫи®ЎпјҢд»Ҙд»ҝдәәжңәеҷЁдәәдёәдҫӢпјҢдёҖдёӘиёўзҗғеҠЁдҪңе°ұжңүдёҠзҷҫдёҠеҚғзҜҮеӯҰжңҜи®әж–ҮеңЁз ”究гҖӮ
иҖҢдәәе·ҘжҷәиғҪжңәеҷЁеӯҰд№ иҝҷдәӣпјҢеңЁе®һйҷ…жңәеҷЁдәәиҝҗеҠЁжҺ§еҲ¶гҖҒ规еҲ’дёӯзҡ„дҪҝз”Ёиҝҳеҹәжң¬дёҠеұҖйҷҗдәҺеӯҰд№ дёӘжЁЎеһӢеҸӮж•°зЁӢеәҰзҡ„ж°ҙе№ігҖӮ
з”Ёз®—жі•ж №жҚ®зҺҜеўғе’ҢжңәеҷЁдәәзҠ¶жҖҒиҮӘеҠЁз”ҹжҲҗеҠЁдҪңпјҹдјјд№ҺиҝҳеҫҲйҒҘиҝңгҖӮ
зӣҙеҲ°жҲ‘зңӢеҲ°иҝҷдёӘз ”з©¶пјҡ
CONTACT-INVARIANT TRAJECTORY OPTIMIZATION
дёҖеҸҘиҜқпјҢеҜ№дәҺд»»ж„Ҹз»“жһ„зҡ„жңәеҷЁдәәпјҢд»»ж„ҸеҲқе§Ӣе§ҝжҖҒдҪҚзҪ®пјҢеҸӘиҰҒжҢҮе®ҡдәҶжң«зҠ¶жҖҒпјҢз®—жі•еҸҜд»ҘиҮӘеҠЁз”ҹжҲҗз¬ҰеҗҲзү©зҗҶ规еҫӢзҡ„пјҢжңәеҷЁдәәе…Ёиә«еҠЁдҪңгҖӮ
дёҚеҸӘжҳҜиө°дёӨжӯҘпјҢз«ҷиө·жқҘиҝҷд№Ҳз®ҖеҚ•пјҢз”ҡиҮіжңүзҲ¬жҘјжўҜгҖҒеҖ’з«ӢгҖҒдёӨдәәй…ҚеҗҲж”Җзҷ»зӯүзӯүгҖӮгҖӮ
иҝҷдёӘж•ҷжҺҲзҡ„дё»йЎөEmo Todorov дҝқеҠ еҲ©дәҡдәәпјҢй«ҳдёӯжҳҜж•°еӯҰе’ҢдҝЎжҒҜзҡ„еҸҢж–ҷеӣҪйҷ…йҮ‘зүҢгҖӮгҖӮгҖӮ
жғіеҗ¬еҺҹзҗҶзҡ„иҜқпјҢз®ҖеҚ•иҜҙжқҘпјҢз”ЁиҪЁиҝ№дјҳеҢ–пјҢзү№ж®Ҡд№ӢеӨ„жҳҜз”ЁеҠ йҷ„еҠ еҸҳйҮҸзҡ„ж–№ејҸжҠҠеҗ„дёӘжҺҘи§Ұйқўзҡ„жҺҘи§Ұжғ…еҶөд№ҹзј–з Ғиҝӣж•ҙдёӘжЁЎеһӢзҡ„вҖңзҠ¶жҖҒвҖқйҮҢпјҢ并дҪҝз”ЁвҖңиҪҜеҢ–вҖқ зҡ„жҺҘи§ҰеҠЁеҠӣеӯҰжЁЎеһӢпјҢжҠҠиҝҗеҠЁи§„еҲ’иҝҷдёӘжң¬жқҘеҢ…еҗ«еҫҲеӨҡдёҚиҝһз»ӯеӨ„пјҲжҜ”еҰӮж’һеҮ»пјҢе…¶е®һд»»дҪ•жҺҘи§Ұйқўзҡ„еҸҳеҢ–йғҪж„Ҹе‘ізқҖзі»з»ҹеҠЁеҠӣеӯҰзү№жҖ§зҡ„зӘҒеҸҳпјүзҡ„й—®йўҳиЎЁиҝ°жҲҗдёҖдёӘиҝһз»ӯгҖҒж— зәҰжқҹзҡ„еҮёдјҳеҢ–й—®йўҳгҖӮиҜҰжғ…еҺ»зңӢи®әж–ҮгҖӮ
иҷҪ然дёҘж јиҜҙжқҘз®—жі•еҜ№е®һйҷ…зҺҜеўғеҒҡдәҶдёҚе°‘еҒҮи®ҫе’Ңз®ҖеҢ–пјҢдҪҶе®ғи§ЈеҶізҡ„й—®йўҳиҝҳжҳҜйқһеёёжңүд»·еҖјпјҢз»ҷдәәд»ҘеҗҜеҸ‘зҡ„гҖӮ
1. ж„ҹи°ўи®ёеӨҡзҹҘеҸӢзҡ„жҸҗйҶ’пјҢиҝҷдёӘе…¶е®һдёҚз®—жҺ§еҲ¶з®—жі•пјҢеұһдәҺиҝҗеҠЁи§„еҲ’з®—жі•гҖӮз®—жі•еҫ—еҲ°зҡ„иҪЁиҝ№еҫҖжңәеҷЁдәәиә«дёҠз”Ёзҡ„ж—¶еҖҷпјҢйңҖиҰҒзҡ„жҳҜжҺ§еҲ¶з®—жі•жқҘиҒӘжҳҺең°еҲ©з”ЁеҸҚйҰҲдҝЎжҒҜпјҢж—ўе®һзҺ°еҠЁдҪңеҸҲз»ҙжҢҒжңәеҷЁдәәе№іиЎЎзӯүиҰҒжұӮгҖӮ
2. иҜҘе®һйӘҢе®ӨеңЁжӯӨйЎ№зӣ®дёҠжӯЈеңЁеҒҡзҡ„е°ұжҳҜеҒҡе®һж—¶жҺ§еҲ¶еҷЁгҖӮе·Із»ҸеҸ‘иЎЁзҡ„жҲҗжһңжҳҜйҖҡиҝҮеҗҢж—¶еҜ№еӨҡдёӘдёҚеҗҢзҡ„жЁЎеһӢиҝӣиЎҢиҪЁиҝ№дјҳеҢ–пјҢжҸҗй«ҳиҪЁиҝ№зҡ„йІҒжЈ’жҖ§пјҲжғіжі•жҳҜпјҢеҰӮжһңдёҖжқЎиҪЁиҝ№еңЁд»ҝзңҹдёӯеҜ№10дёӘиҙЁйҮҸеҲҶеёғз•ҘдёҚеҗҢзҡ„жңәеҷЁдәәйғҪиғҪзЁіе®ҡпјҢйӮЈе®һйҷ…зҡ„жңәеҷЁдәәеә”еҪ“еӨ„дәҺиҝҷ10дёӘжғ…еҶөдёӯй—ҙзҡ„жҹҗеӨ„пјҢд№ҹзЁіе®ҡпјүпјҢеңЁзәҝи·‘ж—¶з”ЁдёҖдёӘз®ҖеҚ•зҡ„зәҝжҖ§еҸҚйҰҲжҺ§еҲ¶еҷЁгҖӮе®һзҺ°дәҶDARwInдёҠе№…еәҰеҫҲеӨ§зҡ„еҠЁдҪңпјҢжҜ”еҰӮдёҖжӯҘиҪ¬иә«90еәҰд№Ӣзұ»гҖӮи®әж–ҮиҝһжҺҘпјҡ
3. жҲ‘еҫ®дҝЎеңЁеҶҷжңәеҷЁдәәж–°й—»пјҢжүӢеҠЁзҝ»иҜ‘еӣҪеӨ–жңҖж–°ж¶ҲжҒҜ
жң¬дәәеӨ§еӯҰе’Ңз ”з©¶з”ҹеӯҰзҡ„жҺ§еҲ¶пјҢеӨ§еӯҰеҒҡзҡ„йЈһжҖқеҚЎе°”жҷәиғҪиҪҰпјҢжҜ•дёҡеҗҺеҒҡзҡ„йЈҺз”өдёҠзҡ„еҸҳйў‘еҷЁжҺ§еҲ¶пјҢзҺ°еңЁеңЁи®Ўз®—жңәзі»еҪ“иҖҒеёҲгҖӮ
е…Ҳеӣһзӯ”й—®йўҳпјҢжҲ‘жүҖзңӢеҲ°зҡ„пјҢжңҖжғҠиүізҡ„жҺ§еҲ¶з®—жі•е°ұжҳҜPIжҺ§еҲ¶еҷЁпјҢжІЎжңүд№ӢдёҖпјҢз®ҖзәҰжһҒиҮҙд№ӢзҫҺгҖӮ
дёӢйқўж…ўж…ўеұ•ејҖпјҡ
жҚ®жҲ‘жүҖзңӢеҲ°зҡ„пјҢе·ҘдёҡдёҠеӨ§и§„жЁЎеә”з”Ёзҡ„пјҢдёҚз®ЎжҳҜиҝҗеҠЁжҺ§еҲ¶иҝҳжҳҜиҝҮзЁӢжҺ§еҲ¶пјҢеҮ д№ҺйғҪжҳҜPIDжҺ§еҲ¶еҷЁпјҢе…¶дёӯеӨ§еӨҡж•°еҸҲжҳҜPIжҺ§еҲ¶еҷЁпјҢдёәе•ҘдёҚеҠ еҫ®еҲҶDпјҢеӣ дёәдјҡеёҰжқҘдёҚзЁіе®ҡпјҢе•ҘеҸ«дёҚзЁіе®ҡпјҢе°ұиҰҒи®ІеҸҚйҰҲиҝҷдёӘдёңиҘҝдәҶгҖӮ
1.е…ҲйҡҸдҫҝиҒҠдёҖдәӣе…«еҚҰ
и°ҲеҲ°жҺ§еҲ¶з®—жі•пјҢжңүдәәиҜҙи·Ҝеҫ„规еҲ’пјҢжңүдәәиҜҙжңәеҷЁдәәиҝҗеҠЁеӯҰпјҢиҝҳжңүдәәиҜҙеҚЎе°”жӣјж»ӨжіўеҷЁпјҢзҘһз»ҸзҪ‘з»ңпјҢиҡҒзҫӨз®—жі•пјҢжҲ–иҖ…зІ’еӯҗзҫӨдјҳеҢ–з®—жі•гҖӮжҲ‘ж“ҰпјҢиҝҷе“ӘжҳҜжҺ§еҲ¶з®—жі•пјҢе®Ңе…ЁдёҚжҳҜдёҖдёӘеұӮйқўзҡ„дёңиҘҝпјҢиҮіе°‘дёҚеұһдәҺзӢӯд№үдёҠзҡ„жҺ§еҲ¶з®—жі•гҖӮ
йӮЈдёҠйқўйӮЈдәӣдёңиҘҝеұһдәҺе•ҘпјҢжҗһжҺ§еҲ¶зҡ„е–ңж¬ўеҜ№зі»з»ҹеҲҶеұӮпјҢдёҖиҲ¬еҲҶдёәеҶізӯ–дјҳеҢ–еұӮе’ҢжҺ§еҲ¶еұӮгҖӮ
и·Ҝеҫ„规еҲ’пјҢжңәеҷЁдәәиҝҗеҠЁеӯҰйғҪеұһдәҺеҶізӯ–дјҳеҢ–еұӮзҡ„дёңиҘҝпјҢеңЁиҝҷдёҖеұӮиҝӣиЎҢе…ЁеұҖзҡ„规еҲ’е’ҢдјҳеҢ–пјҢжңҖеҗҺз”ҹжҲҗжҺ§еҲ¶жҢҮд»ӨпјҢдј з»ҷжҺ§еҲ¶еұӮпјҢжҺ§еҲ¶еұӮйҖҡиҝҮй—ӯзҺҜеҸҚйҰҲе®һзҺ°еҜ№жҢҮд»Өзҡ„и·ҹиёӘгҖӮ
еҚЎе°”жӣјж»ӨжіўеҷЁжҳҜж»ӨжіўеҷЁпјҢдёҚжҳҜжҺ§еҲ¶еҷЁпјҢж»ӨжіўеҷЁиҜҙеҲ°еә•жҳҜжҠҠе№Іжү°ж»ӨйҷӨпјҢеҚЎе°”жӣјж»ӨжіўеҷЁзҡ„дёҚеҗҢжҳҜе®ғжһ„е»әдәҶзі»з»ҹзҡ„дёҖдёӘеҠЁжҖҒи·ҹиёӘеӯҰд№ жЁЎеһӢпјҢеҸҜд»Ҙж— ж—¶е»¶ең°еҫ—еҲ°иў«жөӢйҮҸзҡ„дҝЎеҸ·пјҢдёҖиҲ¬еҜ№ж—¶й—ҙжҖ§иҰҒжұӮйқһеёёй«ҳзҡ„е®һж—¶жҺ§еҲ¶зі»з»ҹдјҡз”ЁпјҢе…¶д»–дёҖиҲ¬з”ЁFIRжҲ–иҖ…IIRж»ӨжіўеҷЁе°ұиғҪеӨҹжҗһе®ҡдәҶгҖӮ
зҘһз»ҸзҪ‘з»ңжҳҜжһ„е»әйқһзәҝжҖ§жЁЎеһӢзҡ„ж–№жі•пјҢеҸҜд»Ҙз”ЁжқҘи®ҫи®ЎжҺ§еҲ¶еҷЁпјҢдҪҶжӣҙеӨҡзҡ„жҳҜеҒҡжЁЎејҸиҜҶеҲ«пјҢжЁЎејҸеҲҶзұ»пјҢж•°жҚ®еҲҶжһҗд№Ӣзұ»зҡ„е·ҘдҪңпјҢеңЁжҺ§еҲ¶дёҠпјҢдё»иҰҒжҳҜеӯҰжңҜзҒҢж°ҙжқҘз”ЁпјҢе·ҘдёҡдёҠеҮ д№Һд»ҺжңӘзңӢеҲ°иҝҮпјҢеӣ дёәеҘ¶еҘ¶зҡ„пјҢеӨӘеӨҚжқӮгҖӮ
иҡҒзҫӨз®—жі•пјҢзІ’еӯҗзҫӨз®—жі•пјҢиҝӣеҢ–з®—жі•пјҢеҫ®еҲҶиҝӣеҢ–з®—жі•пјҢйұјзҫӨз®—жі•пјҢ*****еҗ„з§ҚXXжҷәиғҪдјҳеҢ–з®—жі•пјҢиҝҷдёӘдёңиҘҝиҜҙеҲ°еә•е°ұжҳҜжһ„е»әдәҶдёҖдёӘиҝӯд»ЈдјҳеҢ–еӯҰд№ жЁЎеһӢпјҢе®ғзҡ„зӣ®зҡ„жҳҜдјҳеҢ–пјҢдёҚжҳҜе»әжЁЎпјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙз”Ёе®ғжқҘдјҳеҢ–жҲ‘们жҺ§еҲ¶еҷЁеҸӮж•°пјҢжҲ–иҖ…дјҳеҢ–зҘһз»ҸзҪ‘з»ңеҸӮж•°пјҢжҲ–иҖ…е…¶д»–дёҖеҲҮеҸӮж•°пјҢдҪҶжҳҜдёҚиғҪз”Ёе®ғжқҘжһ„е»әжЁЎеһӢпјҢжүҖд»Ҙж №жң¬дёҚжҳҜжҺ§еҲ¶з®—жі•гҖӮ
2.еҲҮе…ҘжӯЈйўҳ
иҜҙдәҶйӮЈд№ҲеӨҡеәҹиҜқпјҢйӮЈе•ҘзҺ©ж„ҸжҳҜзңҹжӯЈзҡ„жҺ§еҲ¶з®—жі•е‘ўпјҹпјҒ
йҰ–е…ҲиҰҒд»ҺдҝЎеҸ·е’Ңзі»з»ҹпјҢд»ҘеҸҠеҸҚйҰҲжҖқжғіејҖе§Ӣи®Іиө·пјҢе…¶е®һпјҢжҺ§еҲ¶пјҢйҖҡдҝЎе’Ңи®Ўз®—жңәжң¬е°ұжҳҜдёҖ家пјҢеӣҪеҶ…йқһиҰҒеҲҶдёәдёүдёӘеӯҰйҷўпјҢеҘ¶еҘ¶зҡ„пјҢзңҹеӨҹеқ‘зҲ№зҡ„гҖӮ
жҺ§еҲ¶з®—жі•пјҢжҺ§еҲ¶зҡ„жҳҜдҝЎеҸ·пјҢдҝЎеҸ·жҳҜиҝһз»ӯйҮҸпјҢжҜ”еҰӮз”өеҺӢпјҢз”өжөҒпјҢиҪ¬йҖҹпјҢеҠҹзҺҮпјҢжё©еәҰпјҢзӯүзӯүпјҢиҜҙеҲ°еә•дҝЎеҸ·е°ұжҳҜдёҖдёӘзү©зҗҶйҮҸеңЁдёҖдёӘеҹҹпјҲж—¶й—ҙжҲ–иҖ…з©әй—ҙпјүдёҠеұ•ејҖгҖӮзі»з»ҹжҳҜе•ҘпјҢзі»з»ҹе°ұжҳҜдҝЎеҸ·еҲ°дҝЎеҸ·зҡ„еҸҳжҚўпјҢжҜ”еҰӮжңҖжҷ®йҖҡзҡ„зӣҙжөҒз”өжңәпјҢжҲ‘еҠ дёҖдёӘз”өеҺӢдҝЎеҸ·з»ҷз”өжңәпјҢ然еҗҺз”өжңәзҡ„иҪ¬йҖҹдҝЎеҸ·ж…ўж…ўеҚҮеҲ°дёҖдёӘеӣәе®ҡеҖјпјҢиҝҷйҮҢз”өжңәе°ұжҳҜдёҖдёӘзі»з»ҹпјҢе®ғе®һзҺ°дәҶз”өеҺӢдҝЎеҸ·еҲ°иҪ¬йҖҹдҝЎеҸ·зҡ„еҸҳжҚўпјҢж”№еҸҳз”өеҺӢпјҢиҪ¬йҖҹдҝЎеҸ·д№ҹдјҡйҡҸзқҖж”№еҸҳгҖӮ
йӮЈеҸҚйҰҲжҳҜе•ҘдёңиҘҝе‘ўпјҹпјҒ
иҝҳжҳҜжӢҝз”өжңәдҪңдёәдҫӢеӯҗпјҢжҜ”еҰӮз©әиҪ¬ж—¶пјҢжҲ‘еҠ 5Vз”өеҺӢпјҢз”өжңәиҪ¬йҖҹ1000rpmпјҢиҝҷж—¶еҖҷжҲ‘дёҖз»ҷз”өжңәеҠ иҪҪпјҢиҪ¬йҖҹе°ұдёӢйҷҚдәҶпјҢе®ҢиӣӢе•ҰпјҢиҖҒеӯҗе°ұжғіиҰҒ1000rpmпјҢдёәе•ҘеҸҳдёәдәҶ800пјҢжңүзҡ„дәәиҜҙпјҢйӮЈдҪ жҠҠз”өеҺӢжҸҗй«ҳеҲ°6VдёҚе°ұжҗһе®ҡе•ҰпјҢеҪ“дҪ жҸҗй«ҳеҲ°6Vж—¶еҖҷпјҢеҰҲзҡ„пјҢиҙҹиҪҪеҸҲеҸҳеӣһеҺҹжқҘзҡ„е•ҰпјҢиҪ¬йҖҹйЈҷеҲ°дәҶ1200rpmпјҢдәҺжҳҜдҪ дёҚеҫ—дёҚеҸҲжҠҠз”өеҺӢи°ғеӣһ5VпјҢе…¶е®һиҝҷйҮҢйқўиҝҷдёӘдәәе°ұеңЁеҒҡеҸҚйҰҲпјҢиҪ¬йҖҹдҪҺдәҶпјҢеҠ з”өеҺӢпјҢиҪ¬йҖҹй«ҳдәҶпјҢйҷҚз”өеҺӢпјҢиҜҙеҲ°еә•е°ұжҳҜеҹәдәҺеҒҸе·®зҡ„жҺ§еҲ¶гҖӮ
еҸҚйҰҲжңҖж—©еә”з”ЁеңЁж”ҫеӨ§з”өи·Ҝзҡ„и®ҫи®ЎдёӯпјҢеҗҺжқҘиў«з»ҙзәіжҸҗеҚҮеҲ°жҺ§еҲ¶и®әеұӮйқўпјҢжіӣеҚҺеҲ°дёҖеҲҮеҠЁжҖҒзі»з»ҹдёӯпјҢеҢ…жӢ¬иҝҗеҠЁжҺ§еҲ¶еӯҰпјҢзӨҫдјҡеӯҰпјҢз»ҸжөҺеӯҰзӯүзӯүгҖӮе…·дҪ“еҸҜд»ҘзңӢз»ҙзәізҡ„гҖҠжҺ§еҲ¶и®әгҖӢпјҢзңӢдёҚжҮӮзҡ„пјҢеҸҜд»ҘзңӢйҮ‘и§Ӯж¶ӣзҡ„гҖҠжҺ§еҲ¶и®әдёҺ科еӯҰж–№жі•и®әгҖӢгҖӮ
дҝЎеҸ·пјҢзі»з»ҹпјҢеҸҚйҰҲе°ұжһ„жҲҗжҺ§еҲ¶зҡ„еҹәжң¬жҰӮеҝөпјҢжҺ§еҲ¶з®—жі•зҡ„жңҖз»Ҳе°ұжҳҜи®ҫи®ЎдёҖдёӘжҺ§еҲ¶зі»з»ҹгҖӮ
иҜҙеҲ°жҖҺд№Ҳж ·и®ҫи®ЎжҺ§еҲ¶зі»з»ҹпјҢеҝ…йЎ»жҺҘзқҖд»ҺдҝЎеҸ·ејҖе§Ӣи®Іиө·пјҢиҝҷйҮҢж•°еӯҰеҲҶжһҗиҢғз•ҙпјҢдҪҶжҳҜе·ҘзЁӢеёҲдёҚжҳҜж•°еӯҰ家пјҢ他们дёҚз«ҷеңЁж—¶й—ҙиҪҙдёҠеҺ»еҲҶжһҗдҝЎеҸ·пјҢиҖҢжҳҜз«ҷеңЁйў‘зҺҮиҪҙдёҠеҲҶжһҗдҝЎеҸ·пјҢдёәе•Ҙиҝҷж ·еҒҡпјҢеәҹиҜқпјҢеҪ“然жҳҜдёәдәҶдҝ©еӯ—пјҢвҖңз®ҖеҢ–вҖқпјҢдҪҶжҳҜиҝҷдёӘз®ҖеҢ–жңүдёӨдёӘеүҚжҸҗгҖӮ
第дёҖдёӘеүҚжҸҗжҳҜеӮ…йҮҢеҸ¶иҖҒзҲ·зҲ·з»ҷеј„еҮәжқҘзҡ„пјҢд»»дҪ•еӨҚжқӮзҡ„е‘ЁжңҹжҖ§дҝЎеҸ·йғҪеҸҜд»ҘеҲҶи§ЈдёәжӯЈејҰдҝЎеҸ·зҡ„ж— з©·зҙҜеҠ е’ҢпјҢжӯЈжҳҜжңүдәҶиҝҷдёӘдёңиҘҝпјҢжҲ‘们е·ҘзЁӢеёҲжүҚжңүеӢҮж°”з«ҷеңЁйў‘зҺҮиҪҙдёҠеҺ»зңӢиҝҷдёӘдё–з•ҢдёҠзҡ„еҪўеҪўиүІиүІзҡ„дҝЎеҸ·пјҢиҝҷд№ҹжҳҜжҲ‘们еӨ§еӯҰж•°еӯҰеҫ®з§ҜеҲҶзҡ„зІҫй«“пјҢдҪҶжҳҜеҘ¶еҘ¶зҡ„пјҢйӮЈдәӣй«ҳж•°иҖҒеёҲжҺЁдәҶдёӨе№ҙе…¬ејҸпјҢд№ҹжІЎжңүи·ҹдҪ иҜҙиҝҮиҝҷж ·дёҖеҸҘиҜқпјҢз®Җзӣҙеәҹжҹҙе‘ҖгҖӮ
иҝҳжңүдёҖдёӘеүҚжҸҗпјҢе°ұжҳҜзі»з»ҹеҝ…йЎ»жҳҜзәҝжҖ§ж—¶дёҚеҸҳзі»з»ҹгҖӮдёәе•ҘиҰҒеҠ иҝҷдёӘеүҚжҸҗпјҢзәҝжҖ§еҜ№еә”еҸ еҠ е®ҡзҗҶпјҢж—¶дёҚеҸҳеҜ№еә”еҚ·з§Ҝе®ҡзҗҶ
е•ҘзҺ©ж„ҸеҸ«еҸ еҠ е®ҡзҗҶпјҢе•ҘзҺ©ж„ҸеҸҲеҸ«еҚ·з§Ҝе®ҡзҗҶпјҢеӨ§е®¶еҸҜд»ҘзңӢгҖҠе®һз”Ёж•°еӯ—дҝЎеҸ·еӨ„зҗҶгҖӢиҝҷжң¬д№ҰпјҢжҲ–иҖ…еҘҘжң¬жө·й»ҳзҡ„гҖҠдҝЎеҸ·дёҺзі»з»ҹгҖӢгҖӮ
з»ҸиҝҮдёҠйқўиҝҷж ·дёҖиҜҙпјҢдј°и®ЎжңүдәәзіҠж¶ӮдәҶпјҢиҝҷе“ӘйҮҢжҳҜиҰҒи®ҫи®ЎжҺ§еҲ¶еҷЁпјҢз®ҖзӣҙжҳҜеңЁзғ§и„‘еӯҗгҖӮ
дҪ зҗҶи§ЈдәҶйў‘зҺҮпјҢе°ұиҰҒиҝӣе…Ҙйў‘еҹҹдё–з•ҢдәҶпјҢд№ҹжҲҗдёәдәҶдёҖеҗҚе…Ҙй—ЁжҺ§еҲ¶е·ҘзЁӢеёҲдәҶгҖӮ
зҺ°еңЁејҖе§Ӣ继з»ӯж·ұе…ҘпјҢеҰӮжһңжҲ‘们еҸҜд»ҘжҠҠеӨҚжқӮдҝЎеҸ·зңӢжҲҗеҗ„з§Қйў‘зҺҮдҝЎеҸ·зҡ„еҸ еҠ пјҢйӮЈд№ҲжҲ‘们е°ұеҸҜд»Ҙи®ҫи®ЎжӢҶи§ЈиҝҷдәӣдҝЎеҸ·зҡ„дёңдёңе•ҰпјҢиҝҷе°ұжҳҜж»ӨжіўеҷЁпјҢдҪҺйҖҡж»ӨжіўеҷЁеҸҜд»Ҙж»ӨйҷӨй«ҳйў‘дҝЎеҸ·пјҢе…¶д»–зҡ„д№ҹеҸҜд»Ҙзұ»жҺЁгҖӮж»ӨжіўеҷЁеңЁжҺ§еҲ¶еҷЁйҮҢжҳҜеҝ…йЎ»еҠ зҡ„пјҢеӣ дёәеҸҚйҰҲйҖҡйҒ“дёҠпјҢжңүй«ҳйў‘е№Іжү°пјҢеҝ…йЎ»йҖҡиҝҮж»ӨжіўеҷЁжҠҠиҝҷдәӣй«ҳйў‘е№Іжү°ж»ӨйҷӨпјҢиҝҷйҮҢиҝҳиҰҒзңӢеҸҚйҰҲйҖҡйҒ“дёҠзҡ„дҝЎеҸ·жҳҜжЁЎжӢҹдҝЎеҸ·иҝҳжҳҜж•°еӯ—дҝЎеҸ·пјҢжЁЎжӢҹдҝЎеҸ·иҝӣADCд№ӢеүҚеҝ…йЎ»еҠ жҠ—ж··еҸ ж»ӨжіўеҷЁпјҢеҗҰеҲҷдјҡеҫҲжғЁзҡ„гҖӮ
3.жҺ§еҲ¶еҷЁи®ҫи®Ўж–№жі•пјҲжҺ§еҲ¶з®—жі•пјү
дёӢйқўзңӢжҺ§еҲ¶еҷЁзҡ„е…·дҪ“и®ҫи®Ў
з»Ҹе…ёжҺ§еҲ¶и®ҫи®Ўж–№жі•пјҢйғҪжҳҜй’ҲеҜ№еҚ•иҫ“е…ҘеҚ•иҫ“еҮәзі»з»ҹзҡ„йў‘еҹҹи®ҫи®Ўж–№жі•
з®ҖеҚ•зҡ„зі»з»ҹпјҢз”Ёж №иҪЁиҝ№жі•пјҢеҲҶжһҗжҺ§еҲ¶еҸӮж•°еҸҳеҢ–еҜ№зі»з»ҹжҖ§иғҪзҡ„еҪұе“ҚгҖӮ
еӨҚжқӮзҡ„зі»з»ҹпјҢз”Ёжіўзү№еӣҫжі•пјҢеҺ»зңӢзӣёйў‘иЈ•еәҰе’Ңе№…йў‘иЈ•еәҰзҡ„еӨ§е°ҸпјҢд»ҘеҸҠеёҰе®ҪгҖӮ
зҺ°д»ЈжҺ§еҲ¶зі»з»ҹи®ҫи®Ўж–№жі•пјҢжҳҜй’ҲеҜ№еӨҡиҫ“е…ҘеӨҡиҫ“еҮәзҡ„зі»з»ҹ
е»әз«ӢеңЁзҠ¶жҖҒж–№зЁӢд№ӢдёҠзҡ„пјҢиҝҷж–№йқўз ”究зҡ„дёҚеӨҡпјҢдёҚж•ўеҰ„еҠ иҜ„и®әгҖӮ
з”ұдәҺPIDеә”з”Ёзҡ„еӨӘе№ҝпјҢжүҖд»ҘеҪўжҲҗдәҶиҮӘе·ұзӢ¬зү№зҡ„ж•ҙе®ҡж–№жі•
PIDе°ұжҳҜй’ҲеҜ№еҚ•иҫ“е…ҘеҚ•иҫ“еҮәзі»з»ҹзҡ„пјҢз«ҷеңЁйў‘еҹҹи§’еәҰеҺ»и®ҫи®Ўзҡ„пјҢжңүдёҖдәӣз»Ҹе…ёзҡ„еҸӮж•°ж•ҙе®ҡж–№жі•пјҢжҜ”еҰӮZNзӯүпјҢиҝҳжңүеҘҪеӨҡеҘҪеӨҡпјҢ
дёәе•Ҙеә”з”Ёиҝҷд№Ҳе№ҝпјҢеӣ дёәз®ҖеҚ•е®һз”ЁгҖӮ
з Ғзҡ„жңүдәӣд№ұпјҢеӨ§е®¶е°Ҷе°ұеҗ§пјҢжҜ•з«ҹиҮӘе·ұе…ҘиЎҢд№ҹдёҚж·ұгҖӮеҗҺйқўеҶҚж·ұе…Ҙж•ҙзҗҶгҖӮзҗҶжғізҡ„з®—жі•дҪ“зі»пјӣ
жңҖзҗҶжғізҡ„з®—жі•пјҢжҳҜдёҖеҘ—йҖҡз”Ёз®—жі•пјӣ
иҜҘз®—жі•иғҪеӨҹйҖҡиҝҮдёҖзі»еҲ—зҡ„иҜ•йӘҢпјҢз”ҹжҲҗжүҖйңҖиҰҒзҡ„дёҖеҲҮз®—жі•пјӣ
иҝҷе°ұжҳҜж·ұеәҰеӯҰд№ гҖӮ
жҚўеҸҘиҜқиҜҙпјҡеӯҳеңЁдёҖдёӘз®—жі•пјҢе®ғеҸҜд»Ҙз»Ҳз»“дёҖеҲҮз®—жі•пјӣ
е®ғе°ұжҳҜз”ҹжҲҗз®—жі•зҡ„з®—жі•гҖӮ
ејәдәәе·ҘжҷәиғҪжһ„жҲҗзҡ„ж №жң¬еӣ зҙ жҳҜ2пјӣ
е®ғдёҚжҳҜз®ҖеҚ•2дёӘпјҢжҳҜдәҢзә§гҖӮ
жҜ”еҰӮеҜ№иЎҢдёәд»ҘеҸҠз»“жһңеҸҚйҰҲзҡ„жҖқиҖғжҖ»з»“пјҢ然еҗҺеҜ№еүҚиҖ…зҡ„еҸҚжҖқгҖӮ
жҜ”еҰӮдёҖеҘ—дёҠзҪ‘ејәдәәе·ҘжҷәиғҪзі»з»ҹпјҢе®ғйңҖиҰҒдёҖеҸ°иғҪдёҠзҪ‘зҡ„з”өи„‘пјҢ然еҗҺйңҖиҰҒдёҖеҸ°иғҪзӣ‘зқЈе’ҢжҺ§еҲ¶еүҚиҖ…зҡ„зі»з»ҹгҖӮ
еҸӘжӢҘжңүдёҖеҘ—жңәжў°иҮӮжҲ–иҖ…иЎҢиө°зі»з»ҹпјҢи°ҲдёҚдёҠзңҹжӯЈзҡ„жҖқиҖғжҷәиғҪгҖӮ
зңҹжӯЈзҡ„жҷәиғҪжҳҜеҜ№еүҚиҖ…зҡ„з ”з©¶е№¶еҪўжҲҗз»“жһңгҖӮ
жңҖејәеӨ§зҡ„з®—жі•д№ҹжҳҜеҰӮжӯӨгҖӮ
жңҖеҘҪзҡ„з®—жі•пјҢе°ұжҳҜиғҪз”ҹжҲҗжүҖйңҖзҡ„з®—жі•гҖӮ
иҝҷйҮҢзҡ„knownдёҺunknownпјҢи§Ҷе…·дҪ“жғ…еҪўпјҢеҸҜд»ҘзҗҶи§ЈжҲҗпјҢcertainдёҺuncertainпјҢpredictableдёҺunpredictableпјҢзӯүзӯүгҖӮеҰӮжҳҜдҫҝеҸҜеҲҶдёәпјҢcertain certainпјҢcertain uncertainпјҢuncertain certainпјҢuncertain uncertainпјӣpredictable predictableпјҢpredictable unpredictableпјҢunpredictable predictableпјҢunpredictable unpredictableгҖӮзңӢдјјиҜҙзҡ„еәҹиҜқпјҢжҺ’еҲ—з»„еҗҲпјҢдҪҶеҰӮжһңзңҹзҡ„жңүдёӘе®һйҷ…й—®йўҳпјҢеҰӮжӯӨеҸҜд»ҘзңӢеҫ—жҜ”иҫғжё…жҘҡгҖӮиҖҢдё”еҸҜд»ҘеңЁдёҚеҗҢзҡ„еұӮйқўзңӢгҖӮ
жҜ”еҰӮдёҖдёӘдҝЎеҸ·пјҢиҝ‘дјјзӯүдәҺдёӘй«ҳж–ҜзҷҪеҷӘеЈ°пјҢз”ЁиҝҮеҺ»ж•°жҚ®пјҢдј°з®—еҮәеқҮеҖјдёҺж–№е·®пјҢжҳҜknown knownгҖӮдҪҶиӮҜе®ҡдёҚеҮҶзҡ„пјҢеӣ дёәзҺ°е®һдёӯе°ұдёҚеӯҳеңЁж ҮеҮҶзҡ„й«ҳж–ҜзҷҪеҷӘеЈ°пјҢдәҺжҳҜеҒҡеҮәдёҖдёӘиҜҜе·®еҢәй—ҙпјҢжңүеҗ„з§ҚеҒҡжі•пјҢз®—жҳҜknown unknownгҖӮдҪҶknown knownи·ҹknown unknownеҠ иө·жқҘпјҢд№ҹиҝҳжҳҜдёҺе®һйҷ…жңүе·®и·қпјҢжҳҜunknown unknownпјҢжҳҜthere is nothing you can do about itзҡ„дәҶгҖӮдҪҶеёёиў«еҝҪи§Ҷзҡ„жҳҜunknown knownпјҢжҜ”еҰӮиҝҷдёӘдҝЎеҸ·йҮҢйқўпјҢеҸҜд»ҘеҲҶзҰ»еҮәдёҖдёӘе‘ЁжңҹдҝЎеҸ·пјҲдёҚдёҖе®ҡжҳҜжӯЈејҰпјүпјҢжҳҜдёҖдёӘе№Іжү°гҖӮзҹҘйҒ“д№ӢеҗҺпјҢunknown knownеҸҳжҲҗknown knownгҖӮеҰӮжӯӨзӯүзӯүгҖӮ
еүҚйқўиҜҙдәҶпјҢеҸҜд»Ҙд»ҺдёҚеҗҢеұӮйқўиҖғиҷ‘пјҢжҜ”еҰӮдҝЎеҸ·еҲҶжҲҗзЎ®е®ҡйғЁеҲҶе’ҢйҡҸжңәйғЁеҲҶпјҢзЎ®е®ҡйғЁеҲҶжҳҜknown knownгҖӮдҪҶзЎ®е®ҡйғЁеҲҶдёҺе®һйҷ…зҡ„зЎ®е®ҡйғЁеҲҶжңүе·®еҲ«пјҢжҳҜunknown knownгҖӮйҡҸжңәйғЁеҲҶпјҢзҹҘйҒ“еҲҶеёғзҡ„иҜқпјҢжҳҜknown unknownгҖӮйҡҸжңәйғЁеҲҶд№ҹдёҺе®һйҷ…зҡ„йҡҸжңәйғЁеҲҶжңүе·®еҲ«пјҢжҳҜunknown unknownгҖӮеҰӮжҳҜеҰӮжҳҜпјҢдёҚдёҖиҖҢи¶ігҖӮд»ҺиҝҷдёӘеұӮйқўеҲҶжһҗпјҢдёҚеҰӮдёҠдёҖж®өдёӯзҡ„еҲҶжһҗеҜ№е®һйҷ…жңүжҢҮеҜјж„Ҹд№үгҖӮ
еҪ“然иҝҳжңүзі»з»ҹгҖӮжҜ”еҰӮдёҖдёӘзі»з»ҹпјҢжңүиҫ“е…Ҙиҫ“еҮәж•°жҚ®пјҢе»әжЁЎгҖҒиҫЁиҜҶеҮәдёҖдёӘLTIжЁЎеһӢпјҢжңүеҸӮж•°пјҢжҳҜknown knownгҖӮдҪҶиҝҷдёӘжЁЎеһӢиӮҜе®ҡдёҚжҳҜе®Ңе…Ёеҗ»еҗҲж•°жҚ®пјҢжүҖд»ҘиҰҒз»ҷдёҖе®ҡзҡ„дёҚзЎ®е®ҡжҖ§пјҢжҜ”еҰӮеңЁеҸӮж•°дёҠпјҢеҸҜиғҪжңүдёӘеҢәй—ҙпјҢжҳҜknown unknownгҖӮеҚідҪҝеҠ дёҠиҝҷдёӘеҢәй—ҙпјҢд№ҹиҝҳжҳҜдёҺе®һйҷ…жңүе·®еҲ«пјҢжҳҜи°“unknown unknownгҖӮдҪҶеҰӮжһңдёҖеҲҶжһҗпјҢеҸ‘зҺ°иҝҷдёӘжЁЎеһӢе…¶е®һеҸҜд»ҘеҲҶзҰ»жҲҗдёҖдёӘLTIжЁЎеһӢпјҢеҠ дёҠдёҖдёӘжҜ”еҰӮWienerжЁЎеһӢпјҢе°ұжҳҜunknown knownиў«еҸ‘зҺ°дәҶгҖӮ
еҪ“然д№ҹеҸҜд»ҘеңЁдёҚеҗҢзҡ„еұӮйқўеҲҶжһҗгҖӮ
е…¶е®һжҜҸдёҖдёӘз®—жі•йғҪжңүе…¶жғҠиүід№ӢеӨ„пјҢжҜҸеҪ“жҲ‘жҗһжҮӮдёҖдёӘз®—жі•ж—¶пјҢеңЁж„ҹеҸ№з®—жі•зІҫеҰҷд№ӢдҪҷпјҢйғҪдјҡеҜ№з®—жі•и®ҫи®ЎиҖ…иҮҙд»Ҙз”ұиЎ·зҡ„дҪ©жңҚгҖӮжғҠиүіжҲ‘зҡ„з®—жі•еҫҲеӨҡпјҢе…¶дёӯд№ӢдёҖе°ұжҳҜзІ’еӯҗзҫӨз®—жі•гҖӮиҷҪ然关дәҺиҝҷдёӘз®—жі•зҡ„еҗҺз»ӯж”№иҝӣеҫҲеӨҡпјҢд№ҹе°ұжҳҜиҜҙеӯҳеңЁеҫҲеӨҡзҡ„дёҚи¶ід№ӢеӨ„пјҢдҪҶз®—жі•жң¬иә«жүҖи•ҙеҗ«зҡ„йҒ“зҗҶеҖјеҫ—жҲ‘们иҝҗз”ЁеңЁз”ҹжҙ»еҪ“дёӯгҖӮ
дҪңдёәдёҖз§ҚеҗҜеҸ‘ејҸдјҳеҢ–з®—жі•пјҢзІ’еӯҗзҫӨз®—жі•жҳҜеҹәдәҺйҖҹеәҰ-дҪҚ移模еһӢпјҢйҖҡиҝҮдёҚж–ӯиҝӯд»Јжӣҙж–°еҜ»жұӮй—®йўҳзҡ„жңҖдјҳи§ЈгҖӮе…¶йҖҹеәҰжӣҙж–°е…¬ејҸдёәпјҡV(t+1)=wвҖўV(t)+eta1вҖўrand()вҖў(p_best-X(t)+eta2вҖўrand()вҖў(g_best-X(t))гҖӮжӣҙ新规еҲҷжңүдёүйғЁеҲҶжһ„жҲҗпјҡеҺҹжқҘзҡ„йҖҹеәҰпјҲжғҜжҖ§йғЁеҲҶпјүгҖҒдёҺе…ЁеұҖжңҖдјҳеҖјзҡ„еҒҸе·®гҖҒдёҺиҮӘиә«еҺҶеҸІжңҖдјҳеҖјзҡ„еҒҸе·®гҖӮйҖҡиҝҮеҮ дёӘйғЁеҲҶзҡ„еҠ жқғиҝӣиЎҢйҖҹеәҰжӣҙж–°гҖӮ
з®—жі•зҡ„жӣҙ新规еҲҷдёӯпјҢзІ’еӯҗд№Ӣй—ҙзҡ„дәӨдә’дё»иҰҒдҪ“зҺ°еңЁдёӨзӮ№пјҡдёҖжҳҜиҮӘиә«дёҺиҮӘиә«еҺҶеҸІи®°еҪ•пјҲеҺҶеҸІжңҖдјҳдҝЎжҒҜпјүзҡ„дәӨдә’пјҢжҜҸдёӘдёӘдҪ“йғҪеҲ©з”ЁиҮӘиә«зҡ„и®ӨзҹҘпјҢж №жҚ®иҮӘиә«жүҖз»ҸеҺҶзҡ„жңҖдјҳдҪҚзҪ®и°ғж•ҙиҮӘе·ұпјҢе…·жңүвҖңиҮӘжҲ‘вҖқеӯҰд№ жҸҗй«ҳиғҪеҠӣпјӣдәҢжҳҜе…ЁеұҖи®°еҪ•пјҲе…ЁеұҖжңҖдјҳдҝЎжҒҜпјүдёҺиҮӘиә«зҡ„дәӨдә’пјҢж №жҚ®ж•ҙдёӘз§ҚзҫӨжүҖйҒҚеҺҶзҡ„жңҖеҘҪдҪҚзҪ®зҡ„е·®и·қжқҘжӣҙж–°иҮӘе·ұзҡ„дҝЎжҒҜпјҢе…·жңүеҗ‘вҖңд»–дәәвҖқеӯҰд№ зҡ„дјҳзӮ№гҖӮ
иҝҷз§ҚжүҫеҮәиҮӘиә«дёҺиҮӘиә«еҺҶеҸІзҡ„е·®и·қпјҢд»ҘеҸҠеҗ‘дјҳз§ҖдёӘдҪ“еӯҰд№ зҡ„иЎҢдёәпјҢжҳҜдҝғиҝӣжҲ‘们дёҚж–ӯвҖңдјҳеҢ–иҮӘе·ұвҖқзҡ„еҠЁеҠӣпјҢд№ҹжҳҜз”ҹзү©иҝӣеҢ–зҡ„дёҖз§Қжң¬иғҪпјҢжҲ‘и®ӨдёәиҝҷжҳҜиҝҷдёӘз®—жі•жңҖеҖјеҫ—жҲ‘们еҖҹйүҙзҡ„ең°ж–№пјҢжӯЈжҳҜиҝҷз§ҚвҖңеӯҰд№ вҖқзҡ„жҖқжғіпјҢжғҠиүідәҶжҲ‘гҖӮ
пјҢеҸҜжҳҜиҰҒзҗҶи§ЈзҺ°еңЁзҡ„科жҠҖпјҢе…үзҹҘйҒ“и®Ўз®—жңәз»“жһ„пјҢдј ж„ҹеҷЁеҺҹзҗҶжҳҜиҝңиҝңдёҚеӨҹзҡ„пјҢжҲ‘们дёҚиғҪеӣһйҒҝиҝҷдёӘйқһеёёдёҚеғҸ科жҠҖзҡ„иҜқйўҳгҖӮеӣ дёәпјҢеҪ“жҲ‘们зҶҹжӮүдәҶеҗ„з§Қдј ж„ҹеҷЁз”өеҠЁжңәзӯүзӯүе…ғ件пјҲcomponentsпјүпјҢжҲ‘们жңҖе…іжіЁзҡ„й—®йўҳе°ұжҳҜпјҢжҖҺд№ҲдҪҝз”Ёе®ғ们пјҢеҰӮдҪ•жңүеәҸең°з»„еҗҲз”өж°”жҲ–жҳҜжңәжў°жҲ–жҳҜзӨҫдјҡеӯҰз”ҡиҮіжҳҜз”ҹжҖҒзі»з»ҹдёӯзҡ„е…ғ件пјҢд»ҺиҖҢдҪҝж•ҙдёӘзі»з»ҹжҢүз…§жҲ‘们зҡ„иҰҒжұӮиҝҗиЎҢдёӢеҺ»пјҹ
иҜҙиҝҷд№ҲеӨҡйўҳеӨ–иҜқпјҢж— йқһжғіиҰҒејәи°ғжҺ§еҲ¶жҖқжғізҡ„йҮҚиҰҒжҖ§гҖӮзҺ°еңЁеӣһеҲ°PIDжҺ§еҲ¶еҷЁдёҠжқҘпјҢ PIDжҳҜжңҖеёёи§Ғзҡ„жҺ§еҲ¶еҷЁпјҢе№ҝжіӣеә”з”ЁдёҺжңәжў°е’Ңз”өж°”зі»з»ҹгҖӮе®ғзҡ„ж ёеҝғпјҢеңЁдәҺдёҖдёӘеҸҚйҰҲдёҠгҖӮд»Җд№ҲжҳҜеҸҚйҰҲпјҢеҸҚйҰҲе°ұжҳҜи®©зі»з»ҹзҡ„е®һж—¶иҫ“еҮәеҠ е…ҘеҲ°иҫ“е…ҘдёӯпјҢд»ҺиҖҢе®һзҺ°иҮӘеҠЁи°ғиҠӮгҖӮжңҖеёёи§Ғзҡ„жҳҜиҙҹеҸҚйҰҲгҖӮPIDжҺ§еҲ¶еҷЁе°ұжҳҜдёҖж¬ҫйқһеёёе…ёеһӢзҡ„иҙҹеҸҚйҰҲжҺ§еҲ¶еҷЁгҖӮ
PиЎЁзӨәжҜ”дҫӢпјҢз”ЁжқҘзһ¬ж—¶еӨ§е№…еәҰи°ғжҺ§пјҢжҜ”еҰӮиҜҙдҪ зҡ„иҫ“е…ҘжҳҜ5vпјҢдҪҶжҳҜдҪ зҡ„зҗҶжғіиҫ“еҮәжҳҜ10vпјҢйӮЈд№ҲжӯӨж—¶зҡ„иҜҜе·®жҳҜ5’V. з”ЁжҜ”дҫӢжҺ§еҲ¶ж—¶пјҢж №жҚ®дҪ йҖүжӢ©зҡ„жҜ”дҫӢзі»ж•°пјҢеҒҮи®ҫжҳҜ1пјҢйӮЈд№ҲдёӢдёҖжӯҘзҡ„иҫ“еҮәе°ұжҳҜ5+5пјқ10VгҖӮдҪҶжҳҜдәӢе®һзңҹжҳҜеҰӮжӯӨиҪ»жқҫж„үеҝ«еҗ—пјҹеҪ“дҪ еҠ е…ҘдёҖдёӘжҜ”дҫӢ2ж—¶пјҢжңүдёҖдәӣйқһеёёеҸҜжҒ¶зҡ„дёңиҘҝйҳ»зўҚдҪ иҫҫеҲ°зЁіе®ҡзҡ„10vпјҢжҜ”еҰӮиҜҙзі»з»ҹдёҖдёӢеӯҗи·ғеҚҮпјҢеҲ°10vеҲ№дёҚдҪҸиҪҰпјҢдә§з”ҹдәҶи¶…и°ғйҮҸпјҢдёҖдёӢеӯҗеҘ”еҲ°20vдәҶпјҢзЁіжҖҒиҜҜе·®йқһеёёеӨ§иҖҢдё”дёҚеҸҜжҺ§пјҢйӮЈдј°и®ЎжңәеҷЁе·Із»Ҹзғ§дәҶпјҢжҲ–иҖ…е‘ЁеӣҙдёҖдёӢз»Ҷе°Ҹзҡ„жү°еҠЁиҝӣжқҘпјҢз»ҸиҝҮжҜ”дҫӢж”ҫеӨ§пјҢеҸҳжҲҗдәҶзӣёеҜ№иҫғеӨ§зҡ„жү°еҠЁпјҢзі»з»ҹжүӣдёҚдҪҸдәҶгҖӮжҖҺд№ҲеҠһпјҹжҲ‘们引е…ҘIпјҢз§ҜеҲҶжҺ§еҲ¶гҖӮеҪ“жҲ‘们жҠҠиҫ“еҮәеҸҚйҰҲеӣһжқҘе’ҢеӨ–йғЁиҫ“е…ҘдёҖжҜ”иҫғпјҢжҲ‘们еҫ—еҲ°дёҖдёӘиҜҜе·®пјҢ然еҗҺжҲ‘们жҠҠиҜҜе·®дҪңдёәиҫ“е…ҘпјҢеҜ№иҜҜе·®иҝӣиЎҢз§ҜеҲҶпјҢеҶҚеҸҚйҰҲеӣһжқҘгҖӮд»Җд№Ҳж—¶еҖҷиҫҫеҲ°зЁіе®ҡе‘ўпјҹеҪ“иҜҜе·®дёә0дәҶпјҢеҸҚйҰҲеӣһжқҘзҡ„еҖје°ұжҳҜдёҖдёӘеёёж•°пјҲжғідёӢз§ҜеҲҶиҝҮзЁӢпјүпјҢжӯӨж—¶иҫ“еҮәе°ұзЁіе®ҡдәҶгҖӮ并且з”ұдәҺжӯӨж—¶иҜҜе·®дёә0пјҢйӮЈд№ҲзЁіе®ҡзӮ№е°ұжӯЈеҘҪжҳҜеӨ–з•ҢеҸӮиҖғиҫ“е…ҘгҖӮз»“еҗҲжҜ”дҫӢжҺ§еҲ¶пјҢе°ұиғҪе®һзҺ°еҜ№жҠ—е№Іжү°е’Ңж¶ҲйҷӨзЁіжҖҒиҜҜе·®гҖӮжңҖеҗҺпјҢйӮЈDеҫ®еҲҶжҺ§еҲ¶жҳҜжӢҝжқҘе№Іеҳӣзҡ„е‘ўпјҹи®ҫжғідёҖдёӘеңәжҷҜпјҢеӨ–йғЁиҫ“е…ҘжҳҜдёҖдёӘж–ңеқЎдҝЎеҸ·пјҢз”өеҺӢжҲ–иҖ…еҠӣзҹ©йҡҸзқҖж—¶й—ҙеңЁеўһй•ҝжҲ–еҮҸе°‘пјҢйӮЈд№Ҳе…үз”ЁжҜ”дҫӢе’Ңз§ҜеҲҶйғҪж— жі•дҪҝзі»з»ҹиҫ“еҮәиҝҪдёҠиҫ“е…Ҙзҡ„еҸҳеҢ–и„ҡжӯҘгҖӮиҝҷж—¶еҖҷпјҢжҲ‘们дҪҝз”Ёеҫ®еҲҶжҺ§еҲ¶пјҢи®©жҲ‘们иҫ“е…Ҙзҡ„еҸҳеҢ–зҺҮзӯүдәҺиҫ“еҮәзҡ„еҸҳеҢ–зҺҮгҖӮйӮЈд№ҲпјҢжҲ‘们е°ұиғҪиҝҪиёӘеҸҳеҢ–дҝЎеҸ·дәҶгҖӮ
PIDжҺ§еҲ¶еҷЁзҡ„дјҳзӮ№йқһеёёжҳҺжҳҫпјҢжҲ‘е…¶е®һдёҚйңҖиҰҒзі»з»ҹзҡ„зІҫзЎ®жЁЎеһӢ! жҲ‘дёҚз®ЎжЁЎеһӢжҖҺд№Ҳж ·пјҢжҠҠзі»з»ҹиҫ“еҮәжҺҘеҮәжқҘе’ҢдёҖдёӘеҸӮиҖғдҝЎеҸ·дёҖжҜ”пјҢиҜҜе·®дёҖиҫ“е…Ҙ’PIDжҺ§еҲ¶еҷЁпјҢиҜҜе·®е°ұиғҪиў«ж¶ҲйҷӨгҖӮ
дҪҶжҳҜпјҢзңҹзҡ„жңүиҝҷд№ҲиҖҒе°‘зҡҶе®ңе№іжҳ“иҝ‘дәәзҡ„жҺ§еҲ¶еҷЁеҗ—! PIDзңҹзҡ„иҝҷд№Ҳе…ЁиғҪеҗ—пјҹ
йӮЈиҝҳжңүйӮЈд№ҲеӨҡдәәз ”з©¶жҺ§еҲ¶зҗҶи®әе№Ід»Җд№Ҳ! пјҲжү“еҲ°иҮӘе·ұи„ёдәҶпјү
еҫҲйҮҚиҰҒзҡ„дёҖзӮ№, е°ұжҳҜпјҢеҸҳеҢ–дҝЎеҸ·зҡ„еҸҳеҢ–зҺҮеҸӘиғҪжҳҜеёёж•°пјҢе°ұеғҸжҲ‘们жүҖиҜҙзҡ„ж–ңеқЎдҝЎеҸ·пјҢеҪ“еҸҳеҢ–зҺҮд№ҹжҳҜж—¶й—ҙзҡ„еҮҪж•°ж—¶пјҢжҲ‘们зҡ„PIDе°ұж— жі•еӨ„зҗҶдәҶгҖӮеӣ дёәжҲ‘们зҡ„жҺ§еҲ¶еҷЁйҮҢеҸӘжңүдёҖдёӘдёҖйҳ¶еҫ®еҲҶпјҢеҜ№дәҺжұӮеҜјеҗҺиҝҳжҳҜеҸҳеҢ–зҡ„дҝЎеҸ·жқҹжүӢж— зӯ–гҖӮеҸҰдёҖдёӘй—®йўҳе°ұжҳҜпјҢе®ғжҳҜдёҖз§ҚзәҝжҖ§жҺ§еҲ¶еҷЁпјҢдҪҶжҳҜжҲ‘们зҡ„зҺ°е®һзі»з»ҹйғҪжңүйқһзәҝжҖ§зү№еҫҒпјҢжүҖд»ҘеҸӘиғҪеҜ№жҹҗдёӘе№іиЎЎзӮ№еҸҠе…¶йӮ»еҹҹдҪҝз”ЁпјҢжҚўиЁҖд№ӢпјҢеҫҲжңүеҸҜиғҪйӮ»еҹҹеҫҲе°ҸпјҢдёҖж—Ұи¶…еҮәпјҢзі»з»ҹе°ұеҙ©жәғдәҶгҖӮ
жҖ»иҖҢиЁҖд№ӢпјҢPIDжҺ§еҲ¶еҷЁеҜ№дәҺзәҝжҖ§жҖ§еҘҪпјҢиҫ“е…ҘдёҚи¶…иҝҮж–ңеқЎзҡ„зі»з»ҹжҳҜйқһеёёз®ҖеҚ•е®һз”Ёзҡ„пјҢдҪҶжҳҜеҜ№еӨҚжқӮйқһзәҝжҖ§зі»з»ҹе’ҢеӨҚжқӮдҝЎеҸ·иҝҪиёӘпјҢйқһеёёжңүеұҖйҷҗжҖ§гҖӮ
PIDеҚҡиҖҢдёҚдё“пјҢеӣ дёәзү©зҗҶж„Ҹд№үиҝҳз®—жҳҺзЎ®пјҢеҜ№еҫҲеӨҡзі»з»ҹйғҪиғҪдёҠеҺ»и°ғеҮ дёӢеӯҗпјҢдёҚи®әжңүжІЎжңүжЁЎеһӢпјҢжңүжІЎжңүиҫ“е…Ҙиҫ“еҮәж•°жҚ®гҖӮ
иҖҢдёҖж—ҰжңүдәҶжЁЎеһӢпјҢд№ғиҮіжңүдәҶиҫ“е…Ҙиҫ“еҮәж•°жҚ®пјҢйҷӨдәҶдёүйҳ¶пјҲеҢ…жӢ¬пјүд»ҘдёӢзҡ„LTIзі»з»ҹпјҢеҜ№еӨ§еӨҡж•°зі»з»ҹжқҘиҜҙпјҢPIDж•ҲжһңеҸӘиғҪз®—еҸҜд»ҘжҺҘеҸ—гҖӮдёҖиҲ¬йғҪиғҪжүҫеҲ°дё“й—ЁйҖӮеә”дәҺжҹҗдёҖе°Ҹзұ»зі»з»ҹзҡ„жҺ§еҲ¶з®—жі•пјҢжҜ”PIDж•ҲжһңеҘҪпјӣдҪҶиҝҷдәӣз®—жі•еҫҖеҫҖдё“иҖҢдёҚеҚҡпјҢжҚўеҲ°еҸҰеӨ–дёҖдёӘзі»з»ҹдёҠеҸҜиғҪдјҡеҮәеӨ§й—®йўҳгҖӮ
е…¶е®һеҫҲеӨҡж—¶еҖҷпјҢPIDеҸӘжҳҜеә•еұӮпјҢжҲ–жӣ°еҶ…зҺҜпјҢе…ҲжҠҠжҹҗдёӘзі»з»ҹзЁіе®ҡдҪҸпјҢжҲ–жҳҜж”№еҸҳдёӢе…¶еҠЁжҖҒгҖӮ然еҗҺдёӯеұӮгҖҒдёҠеұӮеҶҚеј•е…Ҙе…¶е®ғжҺ§еҲ¶з®—жі•гҖӮеҪ“然пјҢеҘҪеҮ еұӮйғҪжҳҜPIDзҡ„д№ҹжҢәеёёи§Ғзҡ„гҖӮ
еҸҰеӨ–пјҢPIDеҒҡдәӣе°Ҹж”№еҠЁпјҢеңЁе®һйҷ…дёӯз”Ёзҡ„д№ҹдёҚе°‘гҖӮе…¶е®һжңҖз®ҖеҚ•зҡ„PIDд№ҹжҳҜиҰҒиҖғиҷ‘йҘұе’Ңзҡ„гҖӮдҪҶеҗҢж—¶пјҢеҫҲеӨҡжҺ§еҲ¶зі»з»ҹпјҢжҜ”еҰӮз”өеҠӣзҡ„пјҢд№ғиҮізІ’еӯҗеҠ йҖҹеҷЁзҡ„пјҢзӯүзӯүпјҢз”Ёзҡ„йғҪжҳҜеҫҲеҘҮжҖӘзҡ„жҺ§еҲ¶з®—жі•пјҢеҪ“然дёҚжҳҜPIDжҲ–ж”№иҝӣPIDпјҢж•Ҳжһңд№ҹйғҪеҫҲеҘҪгҖӮжҚ®жҲ‘жүҖзҹҘпјҢиҝҷеҫҲеӨҡе®һйҷ…дёӯеңЁз”Ёзҡ„пјҢжІЎдәәд№ҹеҫҲйҡҫеҲҶжһҗе…¶жҖ§иғҪпјҲзЁіе®ҡжҖ§е•Ҙзҡ„пјүпјҢдҪҶе®һйҷ…дёӯз”ЁзқҖиҝҳдёҚй”ҷгҖӮ
иҝҷйҮҢжңүдёӘеҫҲеҘҮжҖӘзҺ°иұЎпјҢеҫҲеӨҡйўҶеҹҹйғҪжңүпјҡзҺ°е®һдёӯеңЁз”Ёзҡ„пјҢеҫҖеҫҖеҫҲйҡҫеҲҶжһҗдёәд»Җд№Ҳж•ҲжһңеҘҪпјӣи®әж–ҮдёӯеңЁеҶҷзҡ„пјҢеҫҖеҫҖеҫҲйҡҫз”ЁеңЁе®һйҷ…дёӯгҖӮжҲ‘зҹҘйҒ“зҡ„дёҖдёӘпјҢе°ұдёҚе…·дҪ“иҜҙдәҶпјҢжҹҗжҺ§еҲ¶з®—жі•пјҢжҳҜжі•еӣҪдәәеңЁе·ҘеҺӮйҮҢжҗһеҮәжқҘзҡ„пјҢеҗҺжқҘе…Ёдё–з•ҢеҮәеҗҚпјҢеңЁеҫҲеӨҡ500ејәзҡ„е…¬еҸёеңЁз”ЁпјҢжІЎеҮәиҝҮй—®йўҳпјҲзҲҶзӮёд»Җд№Ҳзҡ„пјүпјҢдҪҶе°ұжҳҜжІЎжі•иҜҒжҳҺе…¶зЁіе®ҡжҖ§гҖӮеҗҺжқҘжңүдәәз«ҹ然дёәдәҶиҜҒжҳҺзЁіе®ҡжҖ§пјҢжҠҠиҝҷдёӘз®—жі•ж”№дәҶдёҖдёӢгҖӮгҖӮгҖӮиҝҷдёҚе°ұжҳҜдёҖдёӘдәәй’ҘеҢҷеңЁеҲ«еӨ„дёўдәҶпјҢеҸҜеҒҸеҒҸи·‘еҲ°и·ҜзҒҜдёӢжқҘжүҫпјҢд»…д»…еӣ дёәи·ҜзҒҜдёӢйқўжңүдә®д№ҲгҖӮгҖӮгҖӮ
зӣёеҪ“дёҖйғЁеҲҶеӯҰжңҜеңҲзҡ„дәәпјҢе…Ёдё–з•Ңеҗ„еӣҪзҡ„пјҢйқ еңЁиҝҷдёӘж–№еҗ‘еҸ‘и®әж–ҮжқҘзіҠеҸЈпјҢиҮід»Ҡд»ҚжҳҜдёҖдёӘйқһеёёhotзҡ„ж–№еҗ‘пјҲеҪ“然еңЁе·ҘзЁӢдёӯзЎ®е®һж•ҲжһңеҫҲеҘҪпјүгҖӮиҜҙдәҶд№ӢеҗҺпјҢеІӮдёҚжҳҜеҫ—зҪӘиҝҷд№ҲеӨҡдәәгҖӮ
е…¶е®һеҰӮжһңд»”з»ҶжғіжғіпјҢжҺ§еҲ¶еҷЁзҡ„жң¬иҙЁжҳҜиў«жҺ§еҜ№иұЎиҫ“еҮәпјҲд№ҹе°ұжҳҜжҺ§еҲ¶еҷЁеҮәе…Ҙпјүи·ҹжҺ§еҲ¶иҫ“еҮәзҡ„еҮҪж•°жҳ е°„е…ізі»гҖӮе…¶е®һд»ҺиҝҷдёӘи§’еәҰжқҘзңӢпјҢж—¶еҸҳйқһзәҝжҖ§зҡ„жҺ§еҲ¶еҷЁе…¶е®һеҸӮж•°з©әй—ҙжңҖеӨ§пјҢзәҝжҖ§ж—¶дёҚеҸҳзҡ„з®—жҳҜеҫҲеҸ—йҷҗеҲ¶зҡ„дәҶпјҢиҖҢPIDжҳҜеҲҷеңЁзәҝжҖ§ж—¶дёҚеҸҳзҡ„еҹәзЎҖдёҠйҷҗеҲ¶еҲ°дёүдёӘиҮӘз”ұеәҰгҖӮи§Ҷе…·дҪ“зі»з»ҹпјҢжңүзҡ„е°ұеӨҹдәҶпјҢжңүзҡ„з”ҡиҮіеҸӘиҰҒдёӨдёӘиҮӘз”ұеәҰпјҲPDжҲ–PIпјүпјҢжңүзҡ„дёҖдёӘе°ұиЎҢпјҲPпјүгҖӮ
еҪ“然пјҢе®һйҷ…дёӯпјҢPIDе…¶е®һиҰҒеҠ еҫҲеӨҡtrickгҖӮжҜ”еҰӮиҖғиҷ‘еҲ°жү§иЎҢзҺҜиҠӮзҡ„еҠЁжҖҒпјҢйҳІжӯўиҝҮйҘұе’ҢпјҢиҖғиҷ‘дј ж„ҹеҷЁзҡ„еҠЁжҖҒзӯүзӯүпјҢе…¶е®һе°ұдёҚеҶҚжҳҜйҷҗеҲ¶еҲ°дёүдёӘиҮӘз”ұеәҰдәҶпјҢд№ғиҮіе·Із»ҸжҳҜж—¶еҸҳйқһзәҝжҖ§зҡ„дәҶгҖӮиҖҢдё”жңҖз®ҖеҚ•зҡ„пјҢдёІзә§PIDпјҢе…¶е®һз»јеҗҲиө·жқҘзҡ„иҜқпјҢе·Із»ҸдёҚеҸӘжҳҜдёүдёӘиҮӘз”ұеәҰдәҶгҖӮеҸҰдёҖдёӘж–№йқўпјҢжңүзҡ„й«ҳйҳ¶зі»з»ҹж— жі•еҲҶзҰ»пјҢд№ҹе°ұж— жі•з”ЁдёІзә§зҡ„иҜқпјҢйӮЈPIDе°ұеҫҲйҡҫи°ғеҲ°еҫҲеҘҪзҡ„ж•ҲжһңдәҶгҖӮ
PIDзҡ„йҷҗеҲ¶еӨҡдәҶеҺ»дәҶгҖӮжҜ”еҰӮ时延гҖӮдёӘдәәйў„жөӢпјҢ时延жҳҜжңӘжқҘжҺ§еҲ¶зі»з»ҹзҡ„дёҖдёӘеӨ§й—®йўҳпјҢеӣ дёәжҳҜзү©зҗҶдёҠж— жі•е…ӢжңҚзҡ„пјҢиҖҢе…ЁзҗғгҖҒдёҮзү©дә’иҒ”еҸҲжҳҜеӨ§и¶ӢеҠҝгҖӮжңүдәәз”Ёйў„дј°еҷЁзӯүпјҢеҪ“然д№ҹе°ұдёҚжҳҜеҺҹжқҘзҡ„PIDдәҶгҖӮдҪҶйў„дј°еҷЁд№ҹиҰҒзҹҘйҒ“时延зҡ„еӨ§е°ҸжҲ–иҢғеӣҙеҗ§гҖӮзҺ°е®һдёӯеңЁз”Ёзҡ„дёҖдёӘпјҢжҳҜж”№еҸҳдәҶзі»з»ҹзҡ„жӢ“жү‘з»“жһ„пјҲеҰӮжһңеҸӘжңүжҺ§еҲ¶еҷЁи·ҹзі»з»ҹпјҢеҲҷжІЎжңүжӢ“жү‘з»“жһ„еҸҜиЁҖпјӣжңүдәҶзҪ‘з»ңд№ӢеҗҺпјҢжҜ”еҰӮеңЁйҒҘж“ҚдҪңж—¶пјҢеҲҷеӯҳеңЁжӢ“жү‘з»“жһ„дәҶпјүпјҢеҸҜд»ҘеҒҡеҲ°еҜ№ж—¶е»¶йқһеёёйІҒжЈ’гҖӮдҪ иҜҙжҳҜPIDеҗ§пјҢе·Із»Ҹйқўзӣ®е…ЁйқһдәҶпјҢиҖҢдё”еҺҹеҲқзҡ„PIDеҶҚи°ғд№ҹи°ғдёҚеҲ°иҝҷдёӘж•ҲжһңпјӣдҪ иҜҙдёҚжҳҜеҗ§пјҢPIDд№ҹиҝҳжҳҜе…¶дёӯдёҖдёӘзҺҜиҠӮгҖӮ
PIDд№ҹеҸҜд»Ҙз”ЁйІҒжЈ’жҺ§еҲ¶йӮЈдёҖеҘ—жқҘеҲҶжһҗе’Ңи®ҫи®Ўе•ҠпјҢдҪ иҜҙжҳҜйІҒжЈ’е‘ўиҝҳжҳҜPIDе‘ўгҖӮд№ҹеҸҜд»Ҙз”ЁдјҳеҢ–йӮЈдёҖеҘ—жқҘи°ғеҸӮе•ҠгҖӮд№ҹеҸҜд»ҘеҒҡеҲ°еҲҶе·ҘеҶөпјҲжЁЎзіҠзӯүпјүе•ҠпјҢиҮӘйҖӮеә”е•ҠпјҢзӯүзӯүгҖӮе°ұжҳҜеҗ„дёӘжЁЎеқ—еҮ‘еңЁдёҖиө·гҖӮиҝҷеңЁе·ҘзЁӢдёӯжҳҜжҷ®йҒҚзҡ„пјҢд№ҹж— еҸҜеҺҡйқһгҖӮзӣҙеҲ°еҮәзҺ°дёҖдёӘжӣҙе®Ҫе№ҝзҡ„зҗҶи®әпјҢеҸҜд»Ҙжӣҙз®ҖжҙҒиҖҢе…·жңүеҢ…е®№жҖ§гҖӮдҪҶеҪ“然пјҢеңЁжІЎжңүжӣҙеҘҪзҡ„жЎҶжһ¶д№ӢеүҚпјҢPIDеҠ дёҠеҗ„з§ҚtrickпјҢдёҚеӨұдёәеҘҪзҡ„е·ҘзЁӢж–№жЎҲгҖӮдҪҶдҪ дёҚиғҪиҜҙиҝҷе°ұеҲ°еӨҙдәҶпјҢи°ҒзҹҘйҒ“жңӘжқҘдјҡдёҚдјҡеҮәзҺ°жҺ§еҲ¶з•Ңзҡ„еҚЎе°”жӣје‘ўпјҹ
иҝҷйҮҢжҸ’дёҖеҸҘпјҢз”өжўҜзҡ„жӣІзәҝпјҢеҫҲеӨҡж„ҹи§үдёҚиҲ’жңҚпјҢжңүзҡ„и¶…и°ғгҖҒжҢҜиҚЎйқһеёёжҳҺжҳҫпјҢиҝҳжңүзҡ„еҠ йҖҹжІЎдјҳеҢ–пјҢе…¶е®һе°ұжҳҜжІЎи°ғеҘҪгҖӮPIDеҘҪеҘҪи°ғпјҢеҠ дёҠе°ҸtrickпјҢи¶іеӨҹдәҶгҖӮиҝҳжңүдёҖзӮ№пјҢе°ұжҳҜжңҖеҘҪеҠ дёҠдёӘзӣ‘жөӢжҳҜдёҚжҳҜжңүдәәиў«еҚЎдҪҸзҡ„зҺҜиҠӮгҖӮ
иҜқиҜҙеӣһжқҘпјҢеҲ°еә•д»Җд№Ҳж ·зҡ„жӣІзәҝз®—еҘҪе‘ўпјҹе…¶е®һдёҚеӯҳеңЁжңҖдјҳзҡ„пјҢжҜ”еҰӮжңүзҡ„еҜ№йҖҹеәҰгҖҒеҠ йҖҹеәҰжңүйҷҗеҲ¶пјҢжңүзҡ„еҲҷеҜ№иғҪиҖ—жҜ”иҫғдҫ§йҮҚпјҢжңүзҡ„дёҖе®ҡдёҚиғҪжңүи¶…и°ғзӯүзӯүпјҢжңүзҡ„еҲҷжҳҜе“Қеә”и¶Ҡеҝ«и¶ҠеҘҪгҖӮеҪ“然пјҢжүҖжңүзҡ„иҝҷдәӣйғҪжҳҜеңЁеҠҹзҺҮйҷҗеҲ¶д№ӢдёӢгҖӮдёәд»Җд№ҲиҜҙиҝҷдёӘе‘ўпјҹеӣ дёәеҶҚи°ғиҜ•ж—¶пјҢжңүз”ЁжңәеҷЁеӯҰд№ жҲ–дјҳеҢ–з®—жі•и°ғеҸӮзҡ„пјҢйңҖиҰҒжңүйҮҸеҢ–дјҳеҢ–жҢҮж ҮжҲ–жҳҜжҜ”иҫғжӣІзәҝдјҳеҠЈпјҢдҪҶиҝҷдёӘжҢҮж ҮжҲ–иҜ„д»·ж ҮеҮҶеҚҙеҫҲйҡҫзЎ®е®ҡпјҢдҪҶеҗҢж—¶еҚҙеҸҲйқһеёёйҮҚиҰҒгҖӮеҫҲеӨҡжҢҮж ҮпјҢдәҢж¬ЎеһӢпјҢз»қеҜ№еҖјпјҢзӯүзӯүгҖӮдҪҶйҖүеҸ–е“ӘдёӘпјҹеҰӮдҪ•иҜ„еҲӨжҢҮж ҮпјҹжңүжІЎжңүжҢҮж Үзҡ„жҢҮж Үпјҹй—®йўҳеӨҡзқҖе‘ўгҖӮгҖӮгҖӮ
зү©зҗҶеӯҰдёӯпјҢжңүдёӨз§Қжғ…еҶөйңҖиҰҒйҮҚи§ҶпјҢдёҖжҳҜе®һйӘҢдёӯжңүеҮәд№Һж„Ҹж–ҷзҺ°иұЎпјҢдҪҶжүҫдёҚеҲ°зҗҶи®әи§ЈйҮҠпјӣдёҖжҳҜзҗҶи®әжңүеҮәд№Һж„Ҹж–ҷзҡ„йў„жөӢпјҢдҪҶе®һйӘҢдёӯе°ҡжңӘи§ӮеҜҹеҲ°гҖӮиҝҷдёӨз§Қжғ…еҶөпјҢйғҪеҸҜиғҪеёҰжқҘзү©зҗҶеӯҰзҡ„еӨ§еҸҳйқ©гҖӮеҪ“然пјҢжңүеҫҲеӨҡеҮәд№Һж„Ҹж–ҷзҡ„зҺ°иұЎпјҢжҳҜеҸҜд»Ҙз”Ёе·ІеӯҳеңЁзҡ„зҗҶи®әи§ЈйҮҠзҡ„пјҢеҸӘжҳҜдәә们没и®ӨиҜҶеҲ°пјӣеҗҢж—¶пјҢеҫҲеӨҡзҗҶи®әзҡ„йў„жөӢжҳҜй”ҷзҡ„гҖӮ
еҜ№еә”ең°иҜҙпјҢжңүж—¶еҖҷе·ҘзЁӢдёӯпјҢеңЁPIDдёҠдҝ®дҝ®иЎҘиЎҘпјҢжҲ–жҳҜеҮ дёӘзҺ°жңүж–№жі•зҡ„з»„еҗҲпјҢж•ҲжһңеҫҲеҘҪгҖӮиҝҷж—¶еҖҷеҸҜиғҪиғҢеҗҺжңүжӣҙз®ҖеҚ•зҡ„зҗҶи®әпјҢеҸҜд»ҘдҪңдёәжӣҙз®ҖжҙҒзҡ„жЎҶжһ¶гҖӮжҜ”еҰӮеҚЎе°”жӣјд№ӢеүҚпјҢеҫҲеӨҡдәәеңЁзҺ°жңүзҡ„ж»ӨжіўеҹәзЎҖдёҠеўһеўһеҮҸеҮҸпјҢж•Ҳжһңд№ҹдёҚй”ҷпјҢзӣҙеҲ°еҚЎе°”жӣјж»ӨжіўеҮәзҺ°гҖӮдёҚжҒ°еҪ“зҡ„жҜ”е–»пјҢиҝҷе°ұеғҸең°еҝғиҜҙж—¶пјҢжңүзҡ„и§ӮеҜҹеҫҲйҡҫи§ЈйҮҠпјҢз”Ёең°еҝғиҜҙеҠ дёҠдҝ®дҝ®иЎҘиЎҘд№ҹиғҪи§ЈйҮҠпјҢдҪҶеҫҲеӨҚжқӮпјӣдёҖж”№жҲҗж—ҘеҝғиҜҙпјҢе°ұз®ҖеҚ•ең°еӨҡдәҶгҖӮ
иҖҢе°ұзҗҶи®әиҖҢиЁҖпјҢеҫҲеӨҡж–°зҗҶи®әпјҢеЈ°з§°иҮӘе·ұж•ҲжһңеҘҪпјҢдҪҶеӨ§йғЁеҲҶе…¶е®һдёҚеҰӮе·Іжңүзҡ„гҖӮеҸҜеҸҰеӨ–дёҖж–№йқўпјҢдәәзұ»зҡ„жҺ§еҲ¶зҗҶи®әпјҢдёҚеӨ§еҸҜиғҪеҲ°д»ҠеӨ©е°ұдёәжӯўдәҶеҗ§пјҹPIDд№ҹжүҚжңүдёҚеҲ°дёҖзҷҫе№ҙзҡ„еҺҶеҸІгҖӮиҝҷдәӣж–°зҗҶи®әдёӯпјҢеҸӘжңүжһҒе°‘зҡ„пјҢеҸҜд»ҘзңҹжӯЈеёҰжқҘеҸҳйқ©гҖӮзҺ°еңЁи§үеҫ—дёҖдёӘжңүеҸҜиғҪпјҢдёҚиғҪзЎ®е®ҡгҖӮеҸӘиғҪжӢӯзӣ®д»Ҙеҫ…гҖӮ
иҜҰз»Ҷзҡ„е…¬ејҸд»Җд№Ҳзҡ„пјҢзҪ‘з»ңдёҠжҗңзҙўkernel function, kernel methods жңүеҫҲеӨҡпјҢжҲ‘е°ұдёҚд»”з»ҶиҜҙдәҶпјҢз®ҖеҚ•ең°иҜҙиҜҙиғҢеҗҺзҡ„intuitionгҖӮintuitionд№ҹеҫҲз®ҖеҚ•пјҢжҜ”еҰӮжҲ‘们жңүдёҖдёӘдёҖз»ҙзҡ„ж•°жҚ®еҲҶеёғжҳҜеҰӮдёӢеӣҫзҡ„ж ·еӯҗпјҢдҪ жғіжҠҠе®ғз”ЁдёҖдёӘзӣҙзәҝжқҘеҲҶејҖпјҢдҪ еҸ‘зҺ°жҳҜдёҚеҸҜиғҪзҡ„пјҢеӣ дёә他们жҳҜй—ҙйҡ”зҡ„гҖӮжүҖд»ҘдёҚи®әдҪ з”»еңЁе“ӘпјҢжҜ”еҰӮз»ҝиүІз«–зәҝпјҢйғҪдёҚеҸҜиғҪжҠҠдёӨдёӘзұ»еҲҶејҖгҖӮ
дҪҶжҳҜжҲ‘们дҪҝз”ЁдёҖдёӘз®ҖеҚ•зҡ„еҚҮз»ҙзҡ„ж–№жі•пјҢжҠҠеҺҹжқҘдёҖз»ҙзҡ„з©әй—ҙжҠ•е°„еҲ°дәҢз»ҙдёӯпјҢx->(x, x^2)гҖӮжҜ”еҰӮ:
0->(0,0)
1->(1,1)
2->(2,4)
иҝҷж—¶еҖҷе°ұзәҝжҖ§еҸҜеҲҶдәҶ
еҶҚдёҫдёӘдҫӢеӯҗпјҢеңЁдёҖдёӘдәҢз»ҙе№ійқўйҮҢйқўпјҢиҝҷж ·зҡ„жғ…еҶөжҳҜдёҚеҸҜиғҪеҸӘз”ЁдёҖдёӘе№ійқўжқҘеҲҶзұ»зҡ„пјҢдҪҶжҳҜеҸӘиҰҒжҠҠе®ғжҠ•е°„еҲ°дёүз»ҙзҡ„зҗғдҪ“дёҠпјҢе°ұеҸҜиғҪеҫҲиҪ»жҳ“ең°еҲҶзұ»гҖӮ
зҗҶи®әдёҠпјҢз”ұдәҺtrain setжҳҜжңүйҷҗзҡ„пјҢеҪ“дҪ жҠҠdataжҠ•е°„еҲ°ж— йҷҗз»ҙеәҰзҡ„з©әй—ҙдёҠжҳҜдёҖе®ҡеҸҜд»ҘеңЁtrain setдёҠе®ҢзҫҺеҲҶзұ»зҡ„пјҢиҮідәҺеңЁtest setдёҠеҪ“然е°ұе‘өе‘өдәҶгҖӮ
и®°еҫ—иҰҒйҖүеҸ–еҗҲйҖӮпјҲиҜ•иҜ•еҗ„з§Қпјүkernel functionжқҘвҖңйҒҝе…ҚиҝҮжӢҹеҗҲвҖқгҖӮ
е…¶е®һеҗ§пјҢж ёеҮҪж•°жҸҗдҫӣдәҶж•°жҚ®зӮ№й—ҙдёӨдёӨзҡ„зӣёдјјдҝЎжҒҜпјҲ并дёҚдёҘж јпјүгҖӮеҰӮжһңжҠҠ欧ејҸз©әй—ҙдёҠдёӨзӮ№д№Ӣй—ҙзҡ„еҶ…з§ҜдҪңдёә他们жҳҜеҗҰзӣёдјјзҡ„иҜ„еҲӨж ҮеҮҶзҡ„иҜқпјҢж ёеҮҪж•°е°ұжҳҜе…¶зӣҙжҺҘжӢ“еұ•гҖӮжіЁж„ҸпјҢиҝҷйҮҢжүҖи°“зҡ„зӣёдјје№¶дёҚжҳҜдёҘж јж„Ҹд№үдёӢзҡ„пјҢеҸӘжҳҜдёҖз§ҚеҫҲзІ—зіҷзҡ„и§ЈиҜ»гҖӮ
иҖҢеҫҲеӨҡжңәеҷЁеӯҰд№ зҡ„з®—жі•пјҢжҜ”еҰӮпјҲdualпјүsvm,е…¶е®һеҸӘз”ЁеҲ°дәҶж•°жҚ®й—ҙзҡ„зӣёдјјдҝЎжҒҜпјҲlinear SVMеҸӘз”ЁеҲ°еҶ…з§ҜпјүпјҢжүҖд»Ҙиҝҷе°ұжҸҗдҫӣдәҶдёҖз§Қзі»з»ҹжҖ§зҡ„жү©еұ•ж–№ејҸпјҡжҠҠеҶ…з§ҜжҚўжҲҗе…¶д»–зҡ„ж ёеҮҪж•°пјҒ
еҪ“然дәҶпјҢжғід»ҺзҗҶи®әзҡ„и§’еәҰеҫҲеҘҪзҡ„зҗҶи§Јж ёеҮҪж•°йңҖиҰҒе°Ҷе…¶зҗҶи§ЈжҲҗдёҖдёӘдёӨжӯҘзҡ„ж–№жі•пјҢ1пјүе°ҶеҺҹж•°жҚ®жҳ е°„еҲ°еҸҰдёҖдёӘпјҲдҪҺз»ҙй«ҳз»ҙж— з©·з»ҙпјүз©әй—ҙпјӣ2пјүеңЁйӮЈдёӘз©әй—ҙдёҠеҒҡеҶ…з§ҜгҖӮиҝҷеҜ№ж ёеҮҪж•°зҡ„йҖүжӢ©йҖ жҲҗдәҶйҷҗеҲ¶пјҢдҪҶжҳҜе®һйҷ…дёӯпјҢдёӢиӣӢзҡ„жҜҚйёЎжүҚжҳҜеҘҪжҜҚйёЎпјҢдҪ еҸҜд»Ҙд»»ж„ҸйҖүжӢ©ж•ҲжһңеҘҪзҡ„ж ёеҮҪж•°пјҒ
еҜ№дәҺ @йҷҲ然 зҡ„дҫӢеӯҗпјҢжҳ е°„жҳҜ x -> (x,x^2), йӮЈд№Ҳзӯүд»·зҡ„ж ёеҮҪж•°е°ұжҳҜ k(x,y) = x*y+x^2*y^2. иҖҢеҫҲеӨҡж—¶еҖҷпјҢжҲ‘们еҸӘйңҖиҰҒж ёеҮҪж•°пјҢиҖҢдёҚйңҖиҰҒйӮЈдёӘжҳ е°„пјҢд№ҹж— жі•жҳҫејҸзҡ„еҶҷеҮәйӮЈдёӘжҳ е°„пјҲеҪ“然пјҢеҰӮжһңдҪ жғіеҲҶжһҗи§ЈйҮҠеӯҰеҲ°зҡ„еҲҶзұ»еҷЁзҡ„иҜқпјҢиҝҷе°ұдјҡз»ҷдҪ йҖ жҲҗйә»зғҰпјү
жіЁпјҡ并йқһKernel Method Researcher, зҗҶи§Јйҡҫе…ҚжңүеҒҸйўҮпјҢи§Ғи°…гҖӮ
е…ідәҺиҝҷзӮ№зҡ„иҜҜи§Је®һеңЁеӨӘеӨҡгҖӮ
ж ёеҮҪж•°е’Ңжҳ е°„жІЎжңүе…ізі»гҖӮж ёеҮҪж•°еҸӘжҳҜз”ЁжқҘи®Ўз®—жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙд№ӢеҗҺзҡ„еҶ…з§Ҝзҡ„дёҖз§Қз®Җдҫҝж–№жі•гҖӮ
дёҖиҲ¬иӢұж–Үж–ҮзҢ®еҜ№KernelжңүдёӨз§ҚжҸҗжі•пјҢдёҖжҳҜKernel FunctionпјҢдәҢжҳҜKernel TrickгҖӮд»ҺTrickдёҖиҜҚдёӯе°ұеҸҜд»ҘзңӢеҮәпјҢиҝҷеҸӘжҳҜдёҖз§Қиҝҗз®—жҠҖе·§иҖҢе·ІпјҢдёҚж¶үеҸҠд»Җд№Ҳй«ҳж·ұиҺ«жөӢзҡ„дёңиҘҝгҖӮ
е…·дҪ“е·§еңЁе“ӘйҮҢе‘ўпјҹжҲ‘们еҰӮжһңжғіиҝӣиЎҢеҺҹжң¬е°ұзәҝжҖ§дёҚеҸҜеҲҶзҡ„ж•°жҚ®йӣҶиҝӣиЎҢеҲҶеүІпјҢйӮЈд№ҲйҖүйЎ№дёҖжҳҜе®№еҝҚй”ҷиҜҜеҲҶзұ»пјҢеҚіеј•е…ҘSoft MarginпјӣйҖүйЎ№дәҢжҳҜжҲ‘们еҸҜд»ҘеҜ№Input SpaceеҒҡFeature ExpansionпјҢжҠҠж•°жҚ®йӣҶжҳ е°„еҲ°й«ҳз»ҙдёӯеҺ»пјҢеҪўжҲҗдәҶFeature SpaceгҖӮжҲ‘们еҮ д№ҺеҸҜд»Ҙи®ӨдёәпјҲеј•з”ЁCaltechзҡ„иҜҫе Ӯз”ЁиҜӯвҖңWe are safe but not certainвҖқпјүеҺҹжң¬еңЁдҪҺз»ҙдёӯзәҝжҖ§дёҚеҸҜеҲҶзҡ„ж•°жҚ®йӣҶеңЁи¶іеӨҹй«ҳзҡ„з»ҙеәҰдёӯеӯҳеңЁзәҝжҖ§еҸҜеҲҶзҡ„и¶…е№ійқўгҖӮ
еӣҙз»•йҖүйЎ№дәҢпјҢйӮЈд№ҲжҲ‘们жүҖеҒҡзҡ„е°ұжҳҜиҰҒеңЁFeature SpaceеҘ—з”ЁеҺҹжң¬еңЁзәҝжҖ§еҸҜеҲҶжғ…еҶөдёӢзҡ„Input SpaceдёӯдҪҝз”ЁиҝҮзҡ„дјҳеҢ–ж–№жі•пјҢжқҘжүҫеҲ°йӮЈдёӘMaximaizing Marginзҡ„и¶…е№ійқўгҖӮеҺҹзҗҶжңәеҲ¶дёҖжЁЎдёҖж ·пјҢжҳҜдәҢ次规еҲ’пјҢе”ҜдёҖдёҚеҗҢжҳҜд»Је…Ҙж•°жҚ®зҡ„дёҚеҗҢпјҢжҲ‘们йңҖиҰҒд»Је…ҘиҖҢдёҚжҳҜгҖӮиҝҷж—¶пјҲеңЁеҒҮи®ҫжҲ‘们已зҹҘдәҶеҰӮдҪ•йҖүеҸ–mappingд№ӢеҗҺпјүжүҚжңүдәҶж ёеҮҪж•°зҡ„жҰӮеҝөгҖӮ
е…·дҪ“Trickзҡ„ж„Ҹд№үпјҢе°ұжҳҜз®ҖеҢ–и®Ўз®—дәҢ次规еҲ’дёӯй—ҙзҡ„дёҖжӯҘеҶ…з§Ҝи®Ўз®—гҖӮд№ҹеҚідёӯй—ҙжӯҘйӘӨжңүдёҖжӯҘеҝ…йЎ»жұӮеҫ—пјҢиҖҢжҲ‘们еҸҜд»Ҙе®ҡд№үж ёеҮҪж•°пјҢдҪҝеҫ—жҲ‘们еңЁдёҚйңҖиҰҒжҳҫејҸи®Ўз®—жҜҸдёҖдёӘгҖҒз”ҡиҮідёҚйңҖиҰҒзҹҘйҒ“й•ҝд»Җд№Ҳж ·зҡ„жғ…еҶөдёӢпјҢзӣҙжҺҘжұӮеҮәзҡ„еҖјжқҘгҖӮ
д№ҹе°ұжҳҜиҜҙпјҢж ёеҮҪж•°гҖҒеҶ…з§ҜгҖҒзӣёдјјеәҰиҝҷдёүдёӘиҜҚжҳҜзӯүд»·зҡ„гҖӮеӣ дёәinner productе…¶е®һе°ұжҳҜдёҖз§Қsimilarityзҡ„еәҰйҮҸгҖӮж ёеҮҪж•°е’Ңжҳ е°„жҳҜж— е…ізҡ„гҖӮ
дҪҶдёәд»Җд№Ҳиҝҷд№ҲеӨҡзҡ„и®ӨзҹҘдёӯж ёеҮҪж•°жҳҜдёҖз§Қжҳ е°„е‘ўгҖӮдёҖжқҘиҝҷдёӨ件дәӢдёҖиҲ¬е…ҲеҗҺиҝӣиЎҢпјҢжүҖд»Ҙеёёеёёиў«ж··дёәдёҖи°ҲгҖӮдәҢжқҘе°ұеғҸеүҚйқўжүҖиҝ°пјҢж ёеҮҪж•°и®©дәә们дёҚйңҖиҰҒзҹҘйҒ“й•ҝд»Җд№Ҳж ·пјҢдёҚйңҖиҰҒзҹҘйҒ“жҖҺд№ҲйҖүеҸ–жҳ е°„пјҢе°ұиғҪеӨҹз®—еҮәеҶ…з§ҜгҖӮеӣ жӯӨиҝҷеёёеёёиў«и®ӨдҪңжҳҜдёҖз§Қimplicit mappingгҖӮиҝҷжҳҜз”ұMercer TheoremдҝқиҜҒзҡ„пјҢеҚіеҸӘиҰҒж ёеҮҪж•°ж»Ўи¶ідёҖе®ҡжқЎд»¶пјҢйӮЈд№Ҳжҳ е°„з©әй—ҙдёҖе®ҡеӯҳеңЁгҖӮ
ж•…дәӢеә”иҜҘд»ҺдёҖдёӘз®ҖеҚ•зҡ„дәҢз»ҙдё–з•Ңи®Іиө·гҖӮд»ҺеүҚжңүдёҖдёӘдё–з•ҢXпјҢXйҮҢйқўжңүеҫҲеӨҡеҫҲеӨҡзҡ„ж•°жҚ®зӮ№пјҢиҝҷдәӣж•°жҚ®зӮ№еұһдәҺдёӨдёӘеё®жҙҫпјҢжӯЈзұ»е’Ңиҙҹзұ»гҖӮжӯЈзұ»зӮ№еұ…дҪҸеңЁyиҪҙеҸіиҫ№пјҢиҙҹзұ»зӮ№еұ…дҪҸеңЁyиҪҙе·Ұиҫ№пјҢ他们д»ҘyиҪҙдёәеҲҶз•ҢзәҝпјҢжіҫжёӯеҲҶжҳҺпјҢдә’дёҚдҫөзҠҜгҖӮ
зӘҒ然жңүдёҖеӨ©пјҢдёҚзҹҘйҒ“жҳҜXзәӘе№ҙзҡ„еҮ е№ҙеҮ жңҲеҮ ж—ҘпјҢиҙҹзұ»ејҖе§ӢеӨ§дёҫиҝӣж”»жӯЈзұ»йўҶең°зҡ„第еӣӣиұЎйҷҗгҖӮжӯЈзұ»еҫҲеҝ«еӨұеҺ»дәҶеҫҲеӨҡйўҶең°пјҢеҸҲиў«иҝ«зӯҫи®ўдәҶе’Ңе№іжқЎзәҰпјҢд»ҺжӯӨXдё–з•Ңзҡ„еұ…民们еҸ‘зҺ°дәҶдёҖдёӘй—®йўҳпјҢ他们дёҚиғҪеҶҚз”ЁyиҪҙдҪңдёәеӣҪз•ҢдәҶпјҒ
иҝҳеҘҪпјҢеңЁиҙҹзұ»зӮ№дёӯжңүдёҖдҪҚиҒӘжҳҺзҡ„ж•°еӯҰ家пјҢд»–еҸ‘зҺ°дёӨеӣҪзҡ„ең°зӣҳеҸҜд»Ҙз”ЁдёҖжқЎзӣҙзәҝеҲҶејҖпјҢжҠҠе№ійқўдёҠжҜҸдёҖзӮ№еқҗж Үж”ҫиҝӣзӣҙзәҝж–№зЁӢax+by+cйҮҢпјҢеҰӮжһңеӨ§дәҺйӣ¶пјҢиҝҷе°ұжҳҜжӯЈзұ»зҡ„йўҶең°пјҢе°ҸдәҺйӣ¶жҳҜиҙҹзұ»зҡ„йўҶең°пјҢдёӯй—ҙиҝҷжқЎзәҝеҗҺжқҘиў«е‘ҪеҗҚдёәеҲҶзұ»йқўпјҢдәҺжҳҜXдё–з•ҢйҮҢ第дёҖдёӘзәҝжҖ§еҲҶзұ»еҷЁиҜһз”ҹдәҶгҖӮжңүдәҶж•°еӯҰзҡ„её®еҠ©пјҢXдё–з•ҢеӨӘе№ідәҶеҫҲеӨҡе№ҙгҖӮ
然иҖҢеҘҪжҷҜдёҚй•ҝпјҢиҙӘеҫ—ж— еҺҢзҡ„иҙҹзұ»еҗӣдё»еҶҚдёҖж¬ЎеҸ‘иө·дәҶиҝңеҫҒпјҢиҝҷдёҖ次他们еҚ йўҶдәҶ第дёҖиұЎйҷҗд№ӢеӨ–зҡ„еӨ§йҮҸйўҶеңҹпјҢеҗһ并дәҶж•ҙдёӘ第еӣӣиұЎйҷҗгҖӮ然иҖҢз”ұдәҺиҝӣеҶӣиҝҮдәҺжҝҖиҝӣпјҢеҜјиҮҙжҲҳзәҝиҝҮй•ҝпјҢиҙҹзұ»иҝңеҫҒзҡ„и„ҡжӯҘд№ҹдёҚеҫ—дёҚеҒңж»һдәҺжӯӨпјҢејҖе§Ӣдј‘е…»з”ҹжҒҜгҖӮдҪҶжҳҜеӣҪз•ҢжҖҺд№ҲеҠһе‘ўпјҹ
иҒӘжҳҺзҡ„ж•°еӯҰ家иӢҰжҖқеҶҘжғіпјҢеҸ‘зҺ°иҝҷд№ҲдёҖдёӘдәӢе®һпјҡд№ӢеүҚдёӨеӣҪзҡ„еҲҶзұ»йқўжҳҜзӣҙзәҝж—¶пјҢеҲҶзұ»йқўеҸҜд»Ҙз”ЁеҲҶзұ»йқўдёӨдҫ§зҡ„дёӨдёӘзӮ№пјҲдёӨзӮ№дёӯеһӮзәҝжҳҜеҲҶзұ»йқўпјүиЎЁзӨәгҖӮеҰӮжһңеҸ«иҝҷдёӨдёӘзӮ№(x+,y+),(x-,y-)зҡ„иҜқпјҢйӮЈд№ҲжӯЈзұ»йўҶең°зҡ„жүҖжңүзӮ№е’Ң(x+,y+)зҡ„еҶ…з§ҜйғҪеӨ§дәҺе®ғ们е’Ң(x-,y-)зҡ„еҶ…з§ҜпјӣеҸҚд№ӢеҜ№иҙҹзұ»йўҶең°д№ҹжҲҗз«ӢгҖӮж•°еӯҰ家иҝҳеҸ‘зҺ°пјҢеҜ№дәҺд»»ж„ҸдёҖзҫӨдё–з•ҢXдёӯзҡ„зӮ№пјҢ(x+,y+)е’Ң(x-,y-)йғҪиғҪиЎЁзӨәжҲҗе®ғ们зҡ„зәҝжҖ§з»„еҗҲпјҢеҜ№дәҺдёҖдёӘж–°жқҘзҡ„зӮ№пјҢе®ғе’ҢиҝҷдёӨдёӘзӮ№зҡ„еҶ…з§Ҝе°ұеҸҜд»ҘиЎЁзӨәжҲҗжүҖжңүзӮ№е’ҢжүҖжңүе…¶е®ғзӮ№зҡ„еҶ…з§Ҝзҡ„еҠ жқғе’ҢгҖӮжүҖд»Ҙз»ҷе®ҡдёҖдәӣдёӨдёӘеӣҪ家зҡ„зӮ№д№ӢеҗҺпјҢжҲ‘们еҸҜд»Ҙи®Ўз®—дёӨдёӨзӮ№д№Ӣй—ҙзҡ„еҶ…з§ҜпјҢ并жҠҠеҲҶзұ»йқўиЎЁиҫҫжҲҗиҝҷдәӣеҶ…з§Ҝзҡ„зәҝжҖ§еҠ жқғе’ҢгҖӮеҗҺжқҘдәә们жҠҠиҝҷдәӣзӮ№зҡ„еҶ…з§Ҝж”ҫеңЁдәҶдёҖдёӘзҹ©йҳөйҮҢпјҢ并еҸ«е®ғж ёзҹ©йҳөпјҢж ёзҹ©йҳөе®ҡд№үдәҶдё–з•Ңзҡ„еҲҶзұ»гҖӮеңЁиҝҷдёӘж ёзҹ©йҳөйҮҢпјҢзҹ©йҳөйҮҢжҜҸдёӘзӮ№зҡ„еҖјжҳҜдёӨдёӘXдё–з•ҢзӮ№зҡ„зәҝжҖ§еҶ…з§ҜпјҢе®ғе®ҡд№үзҡ„еҲҶзұ»йқўеңЁеҺҹжқҘзҡ„Xдё–з•ҢйҮҢжҳҜдёҖжқЎзӣҙзәҝпјҢжүҖд»ҘиҝҷдёӘж ёзҹ©йҳөеҗҺжқҘиў«жҲҗдёәзәҝжҖ§ж ёзҹ©йҳөпјҢиҖҢд»ҘдёӨдёӘзӮ№з”ҹжҲҗзҹ©йҳөдёӯжҜҸдёӘзӮ№зҡ„жҳ е°„иў«жҲҗдёәзәҝжҖ§ж ёеҮҪж•°гҖӮ
иҝҷдёӘеҸ‘зҺ°еҸҜдёҚеҫ—дәҶгҖӮзӯүж•°еӯҰ家еҸ‘зҺ°иҝҷдёҖзӮ№д№ӢеҗҺпјҢиҙҹзұ»зҡ„йўҶең°е·Із»ҸиҝӣдёҖжӯҘжү©еј дәҶпјҢзҺ°еңЁжӯЈзұ»зҡ„йўҶең°е·Із»ҸеҸӘеү©дёӢ第дёҖиұЎйҷҗйҮҢдёҖдёӘжҠӣзү©зәҝзҡ„еҶ…йғЁдәҶгҖӮдҪҶжңүдәҶж–°зҡ„ж ёзҗҶи®әпјҢиҝҷдёӘеӣҪз•Ңй—®йўҳйҡҫдёҚеҖ’ж•°еӯҰ家пјҢд»–е®ҡд№үдәҶдёҖдёӘжҳ е°„пјҢжҠҠXдё–з•Ңзҡ„зӮ№жҳ е°„еҲ°
зҡ„еӣӣз»ҙдё–з•ҢпјҢжҠҠиҝҷдёӘдё–з•Ңзҡ„еҶ…з§Ҝе®ҡд№үдёәж–°зҡ„ж ёеҮҪж•°пјҢеңЁдёӨдёӘзұ»зҡ„йўҶең°еҲҶеҲ«еҸ–дәҶеҮ дёӘзӮ№дҪңдёәеҹәзЎҖд№ӢеҗҺпјҢдёҖдёӘжҠӣзү©зәҝзҡ„еҲҶзұ»йқўе°ұиў«е®ҡд№үдәҶеҮәжқҘгҖӮиҝҷжҳҜXдё–з•ҢйҮҢ第дёҖдёӘиў«жҲҗеҠҹжҺЁеҜје№¶еҫ—еҲ°е…¬и®Өзҡ„йқһзәҝжҖ§еҲҶзұ»йқўпјҢиҖҢиҝҷйҮҢз”ЁеҲ°зҡ„ж ёеҮҪж•°жҳҜдёҠиҝ°жҳ е°„зҡ„еҶ…з§ҜпјҢд№ҹе°ұжҳҜзӮ№еқҗж Үзҡ„еӨҡйЎ№ејҸиЎЁзӨәпјҢжүҖд»ҘиҝҷдёӘж ёеҮҪж•°пјҲзҹ©йҳөпјүеҸҲиў«з§°дёәеӨҡйЎ№ејҸж ёеҮҪж•°пјҲзҹ©йҳөпјүгҖӮ
еҺҶеҸІжҖ»жҳҜдёҖйҒҚйҒҚйҮҚжј”пјҢдҪҶиҝҷдёҖж¬ЎжӯЈзұ»е°ҶеҺҶеҸІжҺЁеҠЁеҲ°дәҶеүҚжүҖжңӘжңүзҡ„еўғең°гҖӮXзәӘе№ҙиӢҘе№Іе№ҙеҗҺзҡ„жҹҗдёҖеӨ©пјҢиҙҹзұ»еўғеҶ…зҡ„第дёүиұЎйҷҗзӘҒ然еӣ дёәжӯЈзұ»зӯ–еҸҚеҸ‘з”ҹе“—еҸҳпјҢеҗҢж—¶жӯЈзұ»д№ҹеӨ§дёҫиҝӣ攻第дёҖиұЎйҷҗзҡ„иҙҹзұ»йўҶең°пјҢеёҢжңӣ收еӨҚеӨұең°гҖӮз»ҸиҝҮиӢҘе№Іе№ҙзҡ„жҲҳдәүпјҢжңҖеҗҺдёӨзұ»е°ҶйўҶең°з”Ёз¬¬дёҖгҖҒдёүиұЎйҷҗзҡ„дёӨжқЎеҸҢжӣІзәҝйҡ”ејҖпјҢиҙҹзұ»дҝқжңүеҢ…жӢ¬еҺҹзӮ№еңЁеҶ…зҡ„第дәҢгҖҒеӣӣиұЎйҷҗе’Ңеқҗж ҮиҪҙйҷ„иҝ‘зҡ„еҢәеҹҹпјӣжӯЈзұ»еҲҷеҚ йўҶдәҶ第дёҖгҖҒдёүиұЎйҷҗзҡ„еӨ§йғЁеҲҶгҖӮ
зҺ°еңЁзҡ„й—®йўҳжҳҜпјҢиҝҷд№ҲдёҖжқҘеӣҪз•ҢиҰҒжҖҺд№ҲеҲ’еҲҶе‘ўпјҹ
иҝҷеӣһдёҖдёӘжқҘиҮӘжӯЈзұ»дё–з•Ңзҡ„жҮ’жғ°зҡ„ж•°еӯҰ家жғіеҲ°дәҶдёҖдёӘеҹәдәҺж ёж–№жі•зҡ„и§ЈеҶіж–№жЎҲпјҡжҲ‘们дёҚеҰӮи·іиҝҮжҳ е°„е’ҢеҶ…з§Ҝзҡ„жӯҘйӘӨпјҢзӣҙжҺҘе®ҡд№үдёҖдёӘж ёеҮҪж•°еҗ§пјҒиҝҷз§ҚејӮжғіеӨ©ејҖзҡ„ж–№жі•иў«иҙҹзұ»ж•°еӯҰз•Ңе—Өд№Ӣд»Ҙйј»пјҢдҪҶеңЁжӯЈзұ»еҚҙеӨ§иҺ·жҲҗеҠҹгҖӮеҫҲеҝ«жӯЈзұ»зҡ„ж•°еӯҰ家们еҸ‘зҺ°дёӨзӮ№д№Ӣй—ҙи·қзҰ»зҡ„е№іж–№зҡ„жҢҮж•°зҡ„еҖ’ж•°пјҲе…¶е®һжІЎиҝҷд№ҲеӨҚжқӮпјҢе°ұжҳҜжӯЈжҜ”дәҺдёӨзӮ№и·қзҰ»жүҖе®ҡд№үзҡ„й«ҳж–ҜжҰӮзҺҮпјүжҳҜдёҖдёӘдёҚй”ҷзҡ„ж ёеҮҪж•°пјҢиҝҷж ·еңЁеҲҶзұ»йқўйҷ„иҝ‘дёӨзұ»дёӯеҲҶеҲ«йҖүдёҖдәӣзӮ№пјҢе°ұеҸҜд»Ҙе®ҡд№үд»»ж„Ҹзҡ„йқһзәҝжҖ§еҲҶзұ»йқўдәҶгҖӮдёәдәҶзәӘеҝөиҝҷдёӘдјҹеӨ§зҡ„жӯЈзұ»ж•°еӯҰ家пјҢеҗҺдё–з”ЁиҝҷдҪҚж•°еӯҰ家з”ҹе№іжңҖе–ңж¬ўзҡ„дёүз§ҚйЈҹзү©пјҡжӢүйқўгҖҒзүӣиӮүе’Ңе’Ңи–ҜжқЎе‘ҪеҗҚдәҶиҝҷдёӘж ёеҮҪж•°пјҢз§°д№ӢдёәRBFж ёпјҲиҜҜпјүгҖӮ
иҝҷдёӘеҸ‘зҺ°дёәжҺЁеҠЁеҗҺжқҘдёӨзұ»ж•°еӯҰз•Ңзҡ„з»ҹдёҖеҒҡеҮәдәҶе·ЁеӨ§зҡ„иҙЎзҢ®пјҢиҖҢеҸ‘жҳҺRBFж ёзҡ„ж•°еӯҰ家д№ҹеӣ дёәдёҖеҸҘвҖңж•°еӯҰ家жҳҜжңүеҲҶзұ»зҡ„пјҢдҪҶж•°еӯҰжҳҜж— еҲҶзұ»зҡ„вҖқзҡ„еҗҚиЁҖиҺ·еҫ—дәҶиҸІе°”иҢЁе’Ңе№іеҘ–пјҲиҜҜпјүгҖӮ
иҮідәҺеҶ…з§ҜпјҹеҗҺжқҘжңүиҙҹзұ»зҡ„ж•°еӯҰе®¶з ”з©¶дәҶдёҖдёӢRBFж ёжҳҜеҗҰеҜ№еә”дёҖдёӘеҗ‘йҮҸжҳ е°„пјҢз»“жһңжҳҜеҰӮжһңжғіжҠҠRBFж ёиЎЁиҫҫжҲҗдёҖдёӘеҗ‘йҮҸеҶ…з§ҜпјҢжҲ‘们йңҖиҰҒдёҖдёӘжҳ е°„е°Ҷеҗ‘йҮҸжҳ е°„еҲ°дёҖдёӘж— з©·з»ҙзҡ„зәҝжҖ§з©әй—ҙеҺ»гҖӮеҸ‘зҺ°дәҶиҝҷдёҖзӮ№зҡ„ж•°еӯҰ家еҸҲеҸ‘еұ•дәҶMercerе®ҡзҗҶе’ҢйҮҚе»әж ёеёҢе°”дјҜзү№з©әй—ҙпјҲReproducing Kernel Hilbert SpaceпјүзҗҶи®әпјҢдҪҶиҝҷе°ұжҳҜеҸҰеӨ–дёҖдёӘж•…дәӢдәҶгҖӮ
ж ёеҮҪж•°еҸӘжҳҜж»Ўи¶іжҹҗдәӣеҝ…иҰҒжқЎд»¶зҡ„еҮҪж•°пјҢе…¶дҪңз”ЁиҰҒдёҺе…·дҪ“зҡ„з®—жі•з»“еҗҲжүҚиғҪжҳҫзӨәеҮәжқҘгҖӮ
жҲ‘жқҘз®ҖжҳҺиҜҙдёҖдёӢSVMдёӯж ёжҠҖе·§(kernel trick)зҡ„дҪңз”ЁпјҢдёҖеҸҘиҜқжҰӮжӢ¬зҡ„иҜқпјҢе°ұжҳҜйҷҚдҪҺи®Ўз®—зҡ„еӨҚжқӮеәҰпјҢз”ҡиҮіжҠҠдёҚеҸҜиғҪзҡ„и®Ўз®—еҸҳдёәеҸҜиғҪгҖӮ
ж ёеҮҪж•°жңүеҰӮдёӢдёҖдёӘжҖ§иҙЁпјҡ
е…¶дёӯжҳҜеҜ№еҒҡеҸҳжҚўзҡ„еҮҪж•°пјҢжңүдәӣеҸҳжҚўдјҡе°Ҷж ·жң¬жҳ е°„еҲ°жӣҙй«ҳз»ҙзҡ„з©әй—ҙпјҢеҰӮжһңиҝҷдёӘй«ҳз»ҙз©әй—ҙеҶ…дёҺжҳҜзәҝжҖ§еҸҜеҲҶзҡ„пјҢйӮЈд№ҲжҲ‘们е°ұеҒҡдәҶдёҖж¬ЎжҲҗеҠҹзҡ„еҸҳжҚўгҖӮж ёеҮҪж•°жҳҜдәҢе…ғеҮҪж•°пјҢиҫ“е…ҘжҳҜеҸҳжҚўд№ӢеүҚзҡ„дёӨдёӘеҗ‘йҮҸпјҢе…¶иҫ“еҮәдёҺдёӨдёӘеҗ‘йҮҸеҸҳжҚўд№ӢеҗҺзҡ„еҶ…з§ҜзӣёзӯүпјҲиҝҷдёӘжҖ§иҙЁйқһеёёйҮҚиҰҒпјү
иҖҢжҲ‘们зҹҘйҒ“пјҢжұӮи§ЈSVMж—¶пјҢе…¶еҺҹе§ӢеҪўејҸ(иҝҷйҮҢжҲ‘们еҒҮи®ҫе·Із»ҸеҜ№еҺҹе§Ӣзҡ„иҫ“е…ҘеҒҡдәҶеҸҳжҚўпјҢеҚіиҫ“е…ҘжЁЎеһӢзҡ„ж ·жң¬еҸҳжҲҗдәҶ)
st.
i = 1 , 2… N(Nдёәж ·жң¬дёӘж•°)
иҝҷжҳҜдёӘдәҢ次规еҲ’пјҢеӣ дёәжңӘзҹҘйҮҸзҡ„дёӘж•°жҳҜеҸӮж•°wзҡ„з»ҙеәҰпјҢиҖҢwзҡ„з»ҙеәҰдёҺж ·жң¬зҡ„з»ҙеәҰзӣёзӯүпјҢеҚізӯүдәҺеҸҳжҚўеҗҺзҡ„зҡ„з»ҙеәҰпјҢжүҖд»Ҙе…¶жұӮи§ЈеӨҚжқӮеәҰдёҺж ·жң¬зҡ„з»ҙж•°жӯЈзӣёе…іпјҢиҝҷж„Ҹе‘ізқҖпјҢеҰӮжһңжҲ‘们жҠҠеҺҹе§Ӣж ·жң¬д»ҺеҚҒз»ҙз©әй—ҙеҸҳжҚўеҲ°дёҖдёҮз»ҙзҡ„з©әй—ҙпјҢйӮЈд№ҲжұӮи§ЈиҜҘй—®йўҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҸҗеҚҮдәҶ1000еҖҚжҲ–иҖ…жӣҙеӨҡпјҢжҲ‘们зҹҘйҒ“жңүдәӣеҸҳжҚўеҸҜд»Ҙе°Ҷж ·жң¬жҚўиҫ№еҲ°ж— з©·з»ҙз©әй—ҙпјҢйӮЈд№Ҳиҝҷз§ҚеҸҳеҢ–д№ӢеҗҺзӣҙжҺҘжҳҜдёҚеҸҜжұӮи§Јзҡ„гҖӮ
дёҠйқўзҡ„й—®йўҳеҸҜд»ҘдҪҝз”ЁеҜ№еҒ¶ + ж ёжҠҖе·§зҡ„з»„еҗҲжқҘи§ЈеҶігҖӮ
жҲ‘们д№ҹзҹҘйҒ“пјҢSVMеҺҹе§ӢеҪўејҸзҡ„еҜ№еҒ¶й—®йўҳжҳҜпјҡ
st.
еҫҲжҳҺжҳҫпјҢжңӘзҹҘйҮҸзҡ„дёӘж•°дёҺж ·жң¬зҡ„дёӘж•°жҳҜзӣёзӯүзҡ„пјҢйӮЈд№ҲиҝҷдёӘеҜ№еҒ¶й—®йўҳи®Ўз®—зҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜдёҺи®ӯз»ғж ·жң¬зҡ„дёӘж•°жӯЈзӣёе…ізҡ„(иҝҷд№ҹжҳҜдёәе•Ҙж ·жң¬дёӘж•°еӨӘеӨҡзҡ„ж—¶еҖҷдёҚжҺЁиҚҗдҪҝз”ЁеёҰж ёжҠҖе·§зҡ„SVMзҡ„еҺҹеӣ )гҖӮ
д»…д»…еҒҡеҜ№еҒ¶иҝҳжІЎжңүи§ЈеҶій—®йўҳпјҢеӣ дёәеңЁ дёӯиҝҳиҰҒжұӮпјҢиҝҷе°ұйңҖиҰҒе°Ҷж ·жң¬е…ҲеҸҳжҚўеҲ°й«ҳз»ҙз©әй—ҙпјҢ然еҗҺеҶҚжұӮеңЁй«ҳз»ҙз©әй—ҙеҶ…зҡ„еҶ…з§ҜпјҢиҝҷж ·зҡ„еҸҳжҚўиҝҳжҳҜйңҖиҰҒеҫҲеӨҡи®Ўз®—иө„жәҗгҖӮзӯүзӯүпјҢжҲ‘们иҜҙиҝҮж ёеҮҪж•°зҡ„дҪңз”ЁжҳҜвҖңж ёеҮҪж•°жҳҜдәҢе…ғеҮҪж•°пјҢиҫ“е…ҘжҳҜеҸҳжҚўд№ӢеүҚзҡ„дёӨдёӘеҗ‘йҮҸпјҢе…¶иҫ“еҮәдёҺдёӨдёӘеҗ‘йҮҸеҸҳжҚўд№ӢеҗҺзҡ„еҶ…з§ҜзӣёзӯүвҖқпјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙз”ЁжқҘд»Јжӣҝдёӯзҡ„пјҢйҒҝе…ҚдәҶжҳҫејҸзҡ„зү№еҫҒеҸҳжҚўгҖӮ
дәҺжҳҜпјҢдҪҝз”ЁеҜ№еҒ¶+ж ёжҠҖе·§пјҢжҲ‘们жҲҗеҠҹи§ЈеҶідәҶй—®йўҳгҖӮ
дҪҝз”Ёж ёжҠҖе·§д№ӢеҗҺпјҢеӯҰд№ жҳҜйҡҗејҸең°еңЁзү№еҫҒз©әй—ҙиҝӣиЎҢзҡ„пјҢдёҚйңҖиҰҒжҳҫејҸең°е®ҡд№үзү№еҫҒз©әй—ҙе’Ңжҳ е°„еҮҪж•°(жқҺиҲӘ)
иҝҳжңүдёҖдёӘй—®йўҳпјҢе°ұжҳҜеҜ№ж–°ж ·жң¬йў„жөӢзҡ„ж—¶еҖҷжҖҺд№ҲеҠһпјҹдј—жүҖе‘ЁзҹҘпјҢSVMеӯҰд№ еҮәжқҘзҡ„жқғеҖјжҳҜж”Ҝж’‘еҗ‘йҮҸпјҲжүҖи°“ж”Ҝж’‘еҗ‘йҮҸе°ұжҳҜеҜ№еә”зҡ„дёҚдёә0зҡ„ж ·жң¬пјүзҡ„зәҝжҖ§з»„еҗҲпјҢеҚі,жүҖд»ҘжұӮи§Јд№ҹеҸҜд»ҘдҪҝз”Ёж ёжҠҖе·§пјҢжқҘйҒҝе…ҚжҳҫејҸең°еҸҳжҚўгҖӮеҚі
иҝҷд№ҲзңӢпјҢSVMе’Ңж ёжҠҖе·§з®ҖзӣҙжҳҜеӨ©дҪңд№ӢеҗҲпјҒ
й—®йўҳдёӯзҡ„жҳ е°„:
йҰ–е…ҲпјҢе°Ҷж•°жҚ®жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙжҳҜдёәдәҶи§ЈеҶіж•°жҚ®еңЁдҪҺз»ҙз©әй—ҙзәҝжҖ§дёҚеҸҜеҲҶпјҢеҗҰеҲҷеңЁSVMдёӯеҲҶзұ»и¶…е№ійқўе’ҢжңҖеӨ§й—ҙйҡ”зҡ„жҖқжғід№ҹе°ұж— д»Һи°Ҳиө·гҖӮ
й—®йўҳдёӯзҡ„ж ёеҮҪж•°:
дҪҶжҳҜпјҢеҰӮжһңз»ҙж•°еӨӘй«ҳз”ҡиҮіж— з©·з»ҙпјҢе°ұдјҡеёҰжқҘи®Ўз®—йҮҸзҡ„й—®йўҳпјҢиҝҷж—¶еҖҷе°ұйңҖиҰҒж ёеҮҪж•°гҖӮ
еҲ©з”Ёж ёеҮҪж•°пјҢеҸҜд»ҘзӣҙжҺҘеңЁдҪҺз»ҙз©әй—ҙдёӯе®ҢжҲҗи®Ўз®—пјҢиҖҢдёҚйңҖиҰҒжҳҫејҸең°еҶҷеҮәжҳ е°„еҗҺзҡ„з»“жһңпјҢйҒҝе…ҚдәҶеңЁй«ҳз»ҙзҡ„и®Ўз®—пјҢз»“жһңеҚҙжҳҜзӯүд»·зҡ„пјҒ
й—®йўҳдёӯзҡ„еҫ„еҗ‘еҹәж ё:
еҸҰеӨ–пјҢй—®йўҳжҸҗеҲ°зҡ„еҫ„еҗ‘еҹәж ёеҫҲеёёи§ҒжҳҜеӣ дёәеңЁе®һйҷ…иҝҗз”ЁдёӯзЎ®е®һиғҪеҫ—еҲ°дёҚй”ҷзҡ„ж•ҲжһңпјҢжӯӨеӨ–иҝҳжңүзәҝжҖ§ж ёеӨҡйЎ№ејҸж ёз”ҡиҮіеӯ—з¬ҰдёІж ёзӯүзӯүзӯүгҖӮеҫҲеӨҡж—¶еҖҷйҖүжӢ©иҰҒеҸ–еҶідәҺе…·дҪ“зҡ„й—®йўҳпјҢж ·жң¬йҮҸд»ҘеҸҠзү№еҫҒйҮҸзӯүз»јеҗҲиҖғиҷ‘пјҢеҰӮжһңе°‘ж ·жң¬еӨҡзү№еҫҒеҸҜиғҪзәҝжҖ§ж ёе°ұиЎЁзҺ°дёҚй”ҷдәҶпјҢеҰӮжһңеӨҡж ·жң¬е°‘зү№еҫҒй«ҳж–Ҝж ёзЎ®е®һз»Ҹеёёжңүе–ңдәәзҡ„иЎЁзҺ°пјҢеҰӮжһңж ·жң¬йҮҸе·ЁеӨ§еҸҜиғҪеҸҲиҰҒзңӢзқҖеҠһпјҢжҖ»д№ӢдёҖдёӘеӯ—:еӨҡиҜ•иҜ•
йҰ–е…ҲпјҢжҲ‘и®ӨдёәзӣҙжҺҘиҜҙkernel functionпјҲж ёеҮҪж•°пјүжҳҜinner productпјҲеҶ…з§Ҝпјүзҡ„иҜҙжі•жҳҜдёҚеҮҶзЎ®зҡ„гҖӮдёӢйқўд»Һж ёеҮҪж•°зҡ„е®ҡд№үејҖе§Ӣжһ„йҖ еҮәRKHSпјҲreproducing kernel Hilbert spaceпјүгҖӮдёӢж–Үдёӯд»Ҙ иЎЁзӨәе®һж•°гҖӮ
ж ёеҮҪж•°е®ҡд№үеҰӮдёӢпјҡ
A function is a kernel if 1) k(a,b) = k(b,a) and 2) For any in and all real-valued coefficients ,
иҝҷжҳҫ然дёҚжҳҜдёҖдёӘinner productзҡ„зӣҙжҺҘзҡ„е®ҡд№үгҖӮйӮЈд№ҲиҝҷеҸҲжҳҜжҖҺд№Ҳе’Ңinner productиҒ”зі»иө·жқҘпјҢеҸҲжҖҺд№Ҳжһ„е»әдёҖдёӘHilbert spaceе‘ўпјҹ
дёәдәҶжһ„е»әдёҖдёӘHilbert spaceпјҢзҺ°еҒҡеҰӮдёӢе®ҡд№үпјҡ, еҚіпјҢ иЎЁзӨәе°Ҷжҳ е°„еҲ°зҡ„еҮҪж•°зҡ„йӣҶеҗҲгҖӮ并е®ҡд№үfeature map е°Ҷ жҳ е°„еҲ°. жүҖд»ҘпјҢжҳҜдёҖдёӘеҮҪж•°пјҢдё” .
еңЁжӯӨеҹәзЎҖдёҠе®ҡд№үеҗ‘йҮҸз©әй—ҙ . дәҺжҳҜпјҢжҲ‘们еҫ—еҲ°дәҶдёҖдёӘд»Ҙ дёәbasisпјҲеҹәпјүзҡ„real vector spaceпјҲе®ҡд№үеңЁе®һж•°еҹҹдјӨзҡ„еҗ‘йҮҸз©әй—ҙпјүгҖӮжӯӨеӨ„з•ҘеҺ»еҜ№е…¶з¬ҰеҗҲеҗ‘йҮҸз©әй—ҙзҡ„е®ҡд№үзҡ„йӘҢиҜҒгҖӮ然еҗҺе®ҡд№үinner productпјҡеҜ№дәҺ, , е®ҡд№үгҖӮ
йЎ»ж»Ўи¶іеҰӮдёӢжқЎд»¶жүҚеҸҜдҪңдёәзҡ„еҶ…з§Ҝпјҡ
1. еҜ№дәҺд»»ж„Ҹ еқҮжҲҗз«ӢгҖӮ
2. еҜ№дәҺд»»ж„Ҹ еқҮжҲҗз«Ӣ
3. еҜ№дәҺд»»ж„Ҹ еқҮжҲҗз«Ӣ
4. еҜ№дәҺд»»ж„Ҹ жҲҗз«ӢпјҢ дё”еҪ“дё”д»…еҪ“ж—¶пјҢ .
…..жҡӮж—¶з•ҘиҝҮйӘҢиҜҒжңүз©әеҶҚжқҘиЎҘгҖӮгҖӮгҖӮдёҚиҝҮиҝҷдәӣдёӘйғҪдёҚйҡҫгҖӮ
зҺ°еңЁжҲ‘们жһ„йҖ еҮәдәҶinner product spaceпјҲpre-Hilbert spaceпјү,д№ҹе°ұжҳҜVгҖӮдәҺжҳҜ (completion of V) д№ҹе°ұжҳҜжҲ‘们йңҖиҰҒзҡ„Hilbert spaceгҖӮ
йӮЈд№ҲпјҢдёәд»Җд№ҲиҰҒеҸ«RKHSе‘ўпјҹжҲ‘们зңӢеҰӮдёӢдёӨдёӘејҸеӯҗпјҡ
1.
2.
жӯЈејҸеӣ дёәдёҠйқўдёӨдёӘејҸеӯҗпјҲе°Өе…¶жҳҜ第дәҢдёӘпјүпјҢkжүҚиў«з§°дҪңвҖңreproducingвҖқпјҢеҪ“然kдёәд»Җд№ҲеҸ«kernelиҝҳжңүеҲ«зҡ„еҺҹеӣ е°ұе…ҲдёҚиҜҙдәҶпјҲжҲ‘д№ҹиҜҙдёҚеӨӘжё…жҘҡпјүгҖӮжүҖд»Ҙ (with ) жүҚиў«з§°дҪңRKHSгҖӮ
жҲ‘дёҖзӣҙжҠҠж ёеҮҪж•°зҗҶи§ЈжҲҗеңЁеҒҡзү№еҫҒиҪ¬жҚўпјҢж ёеҮҪж•°еңЁи®Ўз®—дёӨдёӘж ·жң¬жҳ е°„еҲ°жҹҗдёӘй«ҳз»ҙз©әй—ҙд№ӢеҗҺзҡ„еҶ…з§ҜпјҢиҖҢеҶ…з§ҜеҸҜд»ҘдёҖе®ҡзЁӢеәҰеҸҚеә”дёӨдёӘж ·жң¬д№Ӣй—ҙзҡ„зӣёдјјеәҰ(дҪҷејҰзӣёдјјеәҰ)гҖӮжҖ»дҪ“жқҘиҜҙпјҢеңЁжҹҗдёӘй«ҳз»ҙз©әй—ҙдёӯпјҢдҪҝз”ЁжүҖжңүж ·жң¬дёҺиҝҷдёӘж ·жң¬д№Ӣй—ҙзҡ„еҶ…з§ҜпјҢеҺ»йҮҚжһ„иҝҷдёӘж ·жң¬зҡ„зү№еҫҒгҖӮ
RBF network дёӯпјҢе°ұеҸҜд»ҘеҫҲз®ҖеҚ•зҡ„зҗҶи§ЈжҲҗпјҡе…ҲеҒҡдёҖеұӮзү№еҫҒеҸҳеҢ–пјҢ然еҗҺеҶҚеҺ»еӯҰд№ дёҖдёӘзәҝжҖ§жЁЎеһӢгҖӮ(еӣ дёәжҳҜе…ҲеҒҡзү№еҫҒеҸҳжҚўпјҢжүҖд»ҘиҝҷйҮҢзҡ„зәҝжҖ§жЁЎеһӢпјҢеҜ№еҺҹе§Ӣзҡ„ж ·жң¬жқҘиҜҙпјҢе·Із»ҸдёҚжҳҜзәҝжҖ§зҡ„дәҶ)гҖӮ
жҲ‘жүҖйҒҮеҲ°зҡ„жүҖжңүдҪҝз”Ёж ёеҮҪж•°зҡ„ең°ж–№пјҢиҝҷд№ҲзҗҶи§Је…ЁйғЁеҸҜд»ҘиҜҙзҡ„иҝҮеҺ»зҡ„гҖӮ еҸҜиғҪжҳҜжҲ‘жҺҘи§Ұзҡ„иҝҳдёҚжҳҜзү№еҲ«ж·ұгҖӮ
svmдёҺж ёеҮҪж•°зҡ„е…ізі»пјҢеҰӮеҗҢlogisticеӣһеҪ’дәҺlogitеҮҪж•°зҡ„е…ізі»гҖӮ
еҰӮеҗҢзәҝжҖ§еӣһеҪ’зҡ„жңҖе°ҸдәҢд№ҳжі•зЎ®е®ҡдёҖжқЎзӣҙзәҝпјҢSVMзҡ„зӣ®зҡ„еҸӘжҳҜжүҫдёҖдёӘжңҖдјҳи¶…е№ійқўпјҢиҝҷдёӘи¶…е№ійқўе°ҶдёӨз»„ж ·жң¬еҲҶејҖзҡ„еҗҢж—¶жңүжңҖеӨ§зҡ„marginпјҢдәҺжҳҜе°ұжҲҗдәҶжұӮжһҒеҖјзҡ„й—®йўҳгҖӮзЎ®е®ҡзҡ„marginиҫ№з•ҢдёҠзҡ„зӮ№дёҺеҗ„иҮӘдёҖйҒҚд»»дҪ•ж ·жң¬зҡ„з§ҜйғҪжҜ”еҸҰдёҖиҫ№зҡ„еӨ§пјҢдәҺжҳҜеҸӘиҰҒжүҫеҲ°дёӨдёӘиҫ№з•ҢдёҠзҡ„зӮ№е°ұеҸҜд»Ҙз»ҷд»ҘеҗҺеҮәзҺ°зҡ„ж–°ж ·жң¬еҲҶзұ»жҸҗдҫӣдҫқжҚ®гҖӮ
еҜ№йӮЈдәӣдёҚиғҪз”ЁдёҖдёӘи¶…е№ійқўеҲҶејҖзҡ„дёӨз»„ж ·жң¬пјҢеҸҜд»Ҙз”ЁжӣІзәҝжҲ–жӣІйқўеҲҶејҖпјҢдҪҶжӣІзәҝжҲ–жӣІйқўзҡ„еҮҪж•°еҫҲйҡҫиҺ·еҫ—пјҢдәҺжҳҜдәә们е°ұйҖҡиҝҮеҮҪж•°е°Ҷж ·жң¬жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙзӣҙеҲ°иғҪжүҫеҲ°дёҖдёӘи¶…е№ійқўе°Ҷе…¶еҲҶејҖпјҢдҪҶжҳҜиҝҷдёӘжҳ е°„еҮҪж•°еҰӮдҪ•зЎ®е®ҡе‘ўпјҹй«ҳз»ҙз©әй—ҙеҰӮдҪ•зЎ®е®ҡе‘ўпјҹиҝҷйҡҫеәҰдёҚдәҡдәҺжһ„е»әе°ҶдёӨзұ»ж ·жң¬еҲҶејҖзҡ„йқһзәҝжҖ§еҮҪж•°гҖӮ
е№ёеҘҪпјҢдәә们еҸ‘зҺ°еҲӨеҲ«еҲҶзұ»ж—¶еҸӘйңҖиҰҒжҜ”иҫғй«ҳз»ҙз©әй—ҙи¶…е№ійқўиҫ№зјҳзҡ„зӮ№дёҺж–°жқҘж ·жң¬зҡ„д№ҳз§Ҝе·®еҲ«еҚіеҸҜпјҢеҗҢж—¶ж ёеҮҪж•°еҸҜд»ҘйҖҡиҝҮдҪҺз»ҙз©әй—ҙж ·жң¬еҗ‘йҮҸзҡ„еҶ…з§Ҝи®Ўз®—д»Јжӣҝжҳ е°„еҗҺй«ҳз»ҙз©әй—ҙзҡ„ж ·жң¬еҗ‘йҮҸеҶ…з§Ҝзҡ„и®Ўз®—пјҢдәҺжҳҜдәә们жҒҚ然еӨ§жӮҹпјҢжҲ‘们其е®һдёҚйңҖиҰҒзҹҘйҒ“жҳ е°„еҮҪж•°е’Ңжҳ е°„еҗҺзҡ„з©әй—ҙжғ…еҶөпјҢеҸӘйңҖиҰҒеңЁжң¬з©әй—ҙеҶ…з”Ёж ёеҮҪж•°зҡ„и®Ўз®—з»“жһңд»Јжӣҝе°ұеҸҜд»ҘдәҶгҖӮ
ж ·жң¬ йқһзәҝжҖ§еҲҶзұ»й—®йўҳ
дҫӢеҰӮдёӢйқўиҝҷдёӘеӣҫпјҢжҲ‘д»¬ж— жі•з”ЁдёҖжқЎзӣҙзәҝжҠҠе®һеҝғзӮ№е’Ңз©әеҝғзӮ№еҲҶејҖпјҢдҪҶжҳҜеҸҜд»Ҙз”ЁжӣІзәҝжҠҠ他们еҲҶејҖгҖӮдҪҶжҳҜй—®йўҳжқҘдәҶпјҢиҝҷдёӘеӨҚжқӮзҡ„йқһзәҝжҖ§еҮҪж•°йҡҫд»Ҙжһ„йҖ гҖӮ
дҪҶжҳҜпјҢеј•е…Ҙж ёж–№жі•пјҢйҖҡиҝҮеөҢе…ҘдёҖдёӘиҫ“е…Ҙз©әй—ҙеҲ°еҸҰдёҖдёӘзү№еҫҒз©әй—ҙзҡ„йқһзәҝжҖ§жҳ е°„гҖӮд№ҹе°ұжҳҜи®©дёҠйқўзҡ„гҖӮиҝҷж ·зҡ„иҜқпјҢеҺҹжқҘзҡ„е®һеҝғзӮ№е’Ңз©әеҝғзӮ№еҸҲеҸҜд»Ҙз”ЁдёҖжқЎзӣҙзәҝеҲҶејҖдәҶгҖӮO(вҲ©_вҲ©)O~~
иҖҢиҝҷйҮҢзҡ„е°ұжҳҜйӮЈдёӘж ёгҖӮи§ЈеҶіеҲҶзәҝжҖ§й—®йўҳзҡ„еҲ©еҷЁе•ҠгҖӮ
ps:жһ„йҖ ж ёеҮҪж•°зҡ„ж–№жі•жңүеҫҲеӨҡпјҢиҰҒж №жҚ®е®һйҷ…жғ…еҶөйҖүжӢ©гҖӮжңҖйҮҚиҰҒзҡ„жҳҜж ёеҮҪж•°йҖҡеёёйғҪжҳҜжңүеҸӮж•°зҡ„пјҢдҫӢеҰӮйҮҢйқўзҡ„пјҢ并且еҲҶзұ»з»“жһңдёҺеҸӮж•°зҡ„йҖүеҸ–жңүжһҒеӨ§зҡ„е…ізі»гҖӮиҰҒж №жҚ®е®һйҷ…жғ…еҶөйҖүеҸ–гҖӮ
pps:еңЁзҪ‘жҳ“е…¬ејҖиҜҫдёҠжңүжңәеҷЁеӯҰд№ йўҶеҹҹзұ»зҡ„еӨ§зүӣAndrew NGзҡ„иҜҫзЁӢгҖӮжңүе…ҙи¶ЈеҸҜд»Ҙи§ӮзңӢж–ҜеқҰзҰҸеӨ§еӯҰе…¬ејҖиҜҫ пјҡжңәеҷЁеӯҰд№ иҜҫзЁӢ
жҗһз»ҹи®Ўзҡ„дәәе…ҘMLзҡ„иЎҢпјҢи®ёеӨҡйғҪдјҡд»ҺProbably Approximately Correct (PAC) learningејҖе§ӢпјҲд№ҹе°ұжҳҜжҘјдёҠеӨҡдҪҚз«ҘйһӢжҸҗеҲ°зҡ„learning theoryпјүпјҢиҖҢPAC learning еңЁзІ—з•Ҙж„Ҹд№үдёҠзӯүеҗҢдәҺжҺ’еҗҚ第дәҢзӯ”жЎҲиҜҙзҡ„вҖңжҲ‘йў„жөӢжҳҺеӨ© 95% зҡ„еҸҜиғҪжҖ§ дёӢйӣЁзҡ„жҰӮзҺҮиҗҪеңЁ гҖҗ0.7,0.9гҖ‘д№Ӣй—ҙвҖқгҖӮ
з®ҖеҚ•жқҘиҜҙпјҢPAC learningе°ұжҳҜз»ҹи®ЎдёӯFrequentistзҡ„дёңиҘҝпјҲд»ҘйӣҶдёӯдёҚзӯүејҸдёәдё»пјҢе…ёеһӢзҡ„дҫӢеҰӮHoeffding Inequality, McDiarmid Inequality, etcпјүеҠ дёҠдёҖдәӣеӨҚжқӮеәҰзҗҶи®ә гҖӮиҝҷдёңиҘҝжңүboundеҸҜиҜҒпјҢдё”дёәиҜёеҰӮSVMпјҢBoostingзӯүжҸҗдҫӣдәҶејәеҠӣзҡ„зҗҶи®әеҹәзЎҖпјҢжүҖд»ҘеҜ№жңәеҷЁеӯҰд№ зҗҶи®әз•Ңзҡ„еҪұе“ҚзӣёеҪ“еӨ§пјҢжңүеӯҰиҖ…з”ҡиҮіи®Өдёәд»ҘPAC LearningдёәеҲҶз•ҢпјҢжңәеҷЁеӯҰд№ з»ҲдәҺдҪңдёәдёҖй—Ёе…·жңүдёҘж јзҗҶи®әзҡ„科еӯҰпјҢжүҚз®—жҳҜд»ҺвҖңз•Ҙжҳҫ民科вҖқзҡ„дј з»ҹдәәе·ҘжҷәиғҪдёӯеҲҶзҰ»еҮәжқҘгҖӮеҸҜд»ҘиҜҙпјҢиҝҷйғЁеҲҶзҡ„жҖқжғіжҳҜе’Ңжҗһз»ҹи®Ўзҡ„дәәеҚҒеҲҶеҘ‘еҗҲзҡ„пјҢдёӘдәәи®Өдёәиҝҷз®—жҳҜйў‘зҺҮеӯҰжҙҫеңЁжңәеҷЁеӯҰд№ йўҶеҹҹзҡ„дёҖж¬ЎеҸ‘жү¬е…үеӨ§гҖӮ
然иҖҢпјҢеҸӘиҰҒд»”з»ҶжҖқиҖғиҝҷдәӣboundзҡ„жҺЁеҜјиҝҮзЁӢпјҢе°ұдјҡеҸ‘зҺ°е…¶дёӯжңүеҫҲеӨҡзӣёеҪ“зІ—з•Ҙзҡ„дј°и®ЎпјӢдёҚеҒңзҡ„жҸҗй«ҳдёҠз•ҢпјҢдёҠз•ҢпјҢдёҠз•ҢгҖӮиҖҢдё”еңЁжҲ‘дёӘдәәзңӢжқҘпјҢиҝҷдәӣжҺЁеҜјиҝҮзЁӢдёӯдҪҝз”Ёзҡ„еҢ…жӢ¬VC dimension, Rademacher complexity зӯүз”ЁжқҘиЎЎйҮҸдёҖдёӘеҮҪж•°ж—Ҹзҡ„richnessзҡ„жҢҮж ҮиҷҪ然数еӯҰдёҠжҳҜдёҘж јзҡ„пјҢдҪҶе…¶вҖңеҲӨж–ӯдёҖдёӘеӨҚжқӮеҮҪж•°еңЁе…·дҪ“й—®йўҳдёҠзҡ„жіӣеҢ–иғҪеҠӣвҖқзҡ„иғҪеҠӣдҫқж—§жҳҜеҚҒеҲҶиҙ«д№Ҹзҡ„гҖӮдёҖдёӘе…ёеһӢзҡ„дҫӢеӯҗе°ұжҳҜдёҖдёӘзҘһз»ҸзҪ‘з»ңзҡ„VC dimension е®ғеӨ§еҲ°ж №жң¬жІЎжңүж„Ҹд№үпјҢ然иҖҢзЎ®еңЁеҫҲеӨҡе®һйҷ…й—®йўҳдёҠиЎЁзҺ°еҘҪиҝҮSVMгҖӮ
жңҖеҗҺпјҢд№ҹжҳҜжҲ‘и®Өдёәзҡ„жңҖе…ій”®зҡ„дёҖзӮ№пјҢPAC Learning жҳҜ distribution unrelatedзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢдёҚз®ЎinputжңҚд»Һд»Җд№Ҳж ·зҡ„distributionпјҢеҸӘиҰҒжҳҜеҸҜжөӢзҡ„пјҢиҝҷдёӘзҗҶи®әйғҪжҲҗз«ӢпјҢжҚўеҸҘиҜқиҜҙпјҢIt is true for every case, so it is useless for every case. дёҖдёӘе®ҢзҫҺеҲ°и¶ід»Ҙж¶өзӣ–дёҖеҲҮеҸҜиғҪиҫ“е…ҘеҲҶеёғзҡ„еӯҰд№ зҗҶи®әпјҢе®ғд№ҹеҝ…е®ҡе№іеҮЎеҲ°ж— жі•зӣҙжҺҘеӨ„зҗҶзЁҚеҫ®жңүй’ҲеҜ№жҖ§зҡ„й—®йўҳгҖӮ
жңәеҷЁеӯҰд№ иҰҒеҒҡзҡ„еҘҪпјҢйңҖиҰҒdata distribution relatedгҖӮе…·дҪ“зҡ„й—®йўҳйңҖиҰҒе…·дҪ“зҡ„prior/pre-knowledgeгҖӮд»ҘвҖңж·ұеәҰеӯҰд№ вҖқдёәдҫӢпјҲе…¶е®һжҲ‘жҜ”иҫғи®ЁеҺҢвҖңж·ұеәҰеӯҰд№ вҖқиҝҷдёӘиҜҚпјҢйғҪеҝ«еҸ‘еұ•жҲҗITиЎҢдёҡдёүдҝ—дәҶпјүпјҢжҜ”еҰӮеӣҫеғҸеӣ дёәжҳҜзӣёеҜ№з©әй—ҙе№іж»‘зҡ„пјҢжүҖд»Ҙз”ЁCNNе°ұжңүж„Ҹд№үпјҢCNNйҮҢйқўзҡ„weight sharing, pooling, locality,е°ұжҳҜй’ҲеҜ№еӣҫеғҸиҝҷз§Қзү№ж®Ҡзҡ„distributionи®ҫи®Ўзҡ„пјҢиҝҷе°ұжҳҜзӣҙжҺҘжіЁе…ҘеңЁжЁЎеһӢдёӯзҡ„priorгҖӮеҶҚжҜ”еҰӮеҒҡspeechжҲ–иҖ…translationдјҡз”ЁRNNпјҢеӣ дёәRNN еҸҜд»ҘжҚ•жҚүж—¶еәҸе…іиҒ”пјҢиҝҷеҸҲжҳҜзӣҙжҺҘжіЁе…ҘеңЁжЁЎеһӢдёӯзҡ„е…ідәҺdata distributionзҡ„priorгҖӮ
жүҖд»Ҙзӣ®еүҚзңӢжқҘпјҢеҰӮжһңжғіиҰҒеҒҡеҮәиғҪworkзҡ„дёңиҘҝе°ұиҰҒдёҖе®ҡзЁӢеәҰдёҠж”ҫејғеӨ§з»ҹдёҖзҗҶи®әзҡ„жўҰжғігҖӮеӣ дёәжңәеҷЁеӯҰд№ жҳҜжІЎжңүдёҮиғҪй’ҘеҢҷзҡ„пјҢunlike Hinton, we don’t know how the brain works.
е…ұеҗҢзӮ№пјҡз»ҹи®Ўе»әжЁЎжҲ–иҖ…жңәеҷЁе»әжЁЎзҡ„зӣ®зҡ„йғҪжҳҜд»Һж•°жҚ®дёӯжҢ–жҺҳеҲ°ж„ҹе…ҙи¶Јзҡ„дҝЎжҒҜгҖӮдёӢйқўеҸӘи®Ёи®әsupervised learningпјҢ е°ұжҳҜеҜ№дёҖдёӘpair: ( иҮӘеҸҳйҮҸxпјҢеӣ еҸҳйҮҸyпјүиҝӣиЎҢе»әжЁЎгҖӮ д№ҹе°ұжҳҜжүҫеҲ°дёҖдёӘеҮҪж•° y=f(x) пјҢ з”Ёx жқҘеҲ»з”» пјҲи§ЈйҮҠгҖҒйў„жөӢпјүyгҖӮ йҰ–е…ҲжҲ‘们иҰҒдёҖз»„и§ӮеҜҹеҖјпјҲx,yпјүпјҢжқҘ еӣһеҪ’пјҲlearnпјүиҝҷдёӘжңӘзҹҘзҡ„еҮҪж•° f.
еҢәеҲ«пјҡ
з»ҹи®ЎеӯҰ家пјҡ еңЁеҲ»з”» f зҡ„иҝҮзЁӢдёӯпјҢз»ҹи®ЎеӯҰ家用зҡ„ж–№жі•жҳҜпјҡ еҜ№дәҺ f зҡ„еҪўзҠ¶е’Ң y зҡ„random distribution иҝӣиЎҢдёҖдәӣеҒҮи®ҫгҖӮ жҜ”еҰӮиҜҙеҒҮи®ҫ f жҳҜзәҝжҖ§жЁЎеһӢпјҢ жҲ–иҖ…y жҳҜnormal distributionгҖӮ 然еҗҺжқҘжұӮеңЁдёҖе®ҡж ҮеҮҶдёӢжңҖдјҳзҡ„ f. жҜ”еҰӮиҜҙпјҢеңЁBLUE пјҲBest Linear Unbiased Estimatorsпјүзҡ„ж ҮеҮҶдёӢпјҢжңҖе°ҸдәҢд№ҳдј°и®ЎеҮәжқҘзҡ„ f е°ұжҳҜжңҖеҘҪзҡ„дј°и®ЎгҖӮ 然еҗҺж №жҚ®еҜ№ж•°жҚ®зҡ„distributionзҡ„еҒҮи®ҫжҲ–иҖ…жҳҜеӨ§ж•°е®ҡеҫӢпјҢеҸҜд»ҘжұӮеҮә еҸӮж•°дј°и®Ўзҡ„дёҚзЎ®е®ҡжҖ§ жҲ–иҖ…жҳҜ standard errorгҖӮ иҝӣиҖҢжһ„е»әзҪ®дҝЎеҢәй—ҙпјҢжқҘиЎЁиҫҫжҲ‘еҜ№жҲ‘иғҪеҒҡеҮәзҡ„ f зҡ„жңҖеҘҪзҡ„дј°и®Ў зҡ„дҝЎеҝғгҖӮдјҳзӮ№пјҡ еҸҜд»ҘеҜ№дёҚзЎ®е®ҡжҖ§еәҰйҮҸгҖӮ з®ҖеҚ•жЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§ејәгҖӮеҪ“еҒҮи®ҫзҡ„assumptionsж»Ўи¶іж—¶жЁЎеһӢ科еӯҰгҖҒеҮҶзЎ®гҖҒдёҘи°ЁгҖӮ зјәзӮ№пјҡеӨҚжқӮжғ…еҶөдёӢassumptionsйҡҫд»ҘйӘҢиҜҒгҖӮ
жңәеҷЁеӯҰд№ дё“е®¶пјҡдёҚеҜ№ y зҡ„distributionиҝӣиЎҢиҝҮеӨҡзҡ„еҒҮи®ҫпјҢдёҚи®Ўз®—standar errorпјҢдёҚ care biasгҖӮ йҖҡиҝҮ cross validationжқҘеҲӨж–ӯ еҜ№дәҺ f зҡ„дј°и®Ўзҡ„еҘҪеқҸгҖӮ д№ҹе°ұжҳҜиҜҙпјҢеңЁжңәеҷЁеӯҰд№ йўҶеҹҹпјҢж•°жҚ®йҮҸеӨ§пјҢжңәеҷЁеӯҰд№ дё“е®¶жӢҝдёҖйғЁеҲҶжқҘдј°и®ЎпјҲtrainпјҢlearn пјүfпјҢз•ҷдёҖйғЁеҲҶжқҘйӘҢиҜҒйў„жөӢз»“жһңзҡ„еҘҪеқҸгҖӮйў„жөӢз»“жһңеҘҪзҡ„жЁЎеһӢе°ұжҳҜеҘҪжЁЎеһӢпјҢдёҚи®Ўз®—дј°и®ЎеҸӮж•°зҡ„еҒҸе·®гҖӮ зјәзӮ№пјҡ зјәд№Ҹ科еӯҰдёҘи°ЁжҖ§гҖӮ дјҳзӮ№пјҡ з®ҖеҚ•зІ—жҡҙгҖӮ жңүдёҖж¬Ўеҗ¬дёҖдёӘеӨ§зүӣзҡ„seminarеҮ дёӘж•ҷжҺҲзҡ„ж®өеӯҗи®°еҝҶе°Өж–°пјҡ"those machine learning people are making predictions without probability! "гҖӮ
еҜ№дәҺиҝҷеҸҘиҜқпјҡвҖңз»ҹи®ЎеӯҰ家жӣҙе…іеҝғжЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§пјҢиҖҢжңәеҷЁеӯҰд№ дё“е®¶жӣҙе…іеҝғжЁЎеһӢзҡ„йў„жөӢиғҪеҠӣвҖқ пјҡ жҖ»дҪ“жқҘиҜҙпјҢеҸҜи§ЈйҮҠжҖ§ејәзҡ„жЁЎеһӢдјҡжҚҹеӨұйў„жөӢиғҪеҠӣпјҢйў„жөӢиғҪеҠӣејәзҡ„жЁЎеһӢеҫҖеҫҖжҜ”иҫғйҡҫи§ЈйҮҠгҖӮ еёёи§Ғзҡ„жЁЎеһӢдёӯпјҢд»ҺеҸҜи§ЈйҮҠжҖ§ејәеҲ°йў„жөӢејәзҡ„жЁЎеһӢдҫқйЎәеәҸжҺ’еҲ—жҳҜ
1 Lasso+зәҝжҖ§еӣһеҪ’
2 зәҝжҖ§еӣһеҪ’
3 йқһзәҝжҖ§жЁЎеһӢ
4 йқһеҸӮжЁЎеһӢ
5 SVM
жһ„е»әз®ҖеҚ•зҡ„жЁЎеһӢпјҢжҜ”еҰӮзәҝжҖ§жЁЎеһӢпјҢжӣҙе®№жҳ“и§ЈйҮҠеӣ еҸҳйҮҸеҜ№иҮӘеҸҳйҮҸзҡ„еҪұе“ҚгҖӮ йҖӮеҗҲдәҺйӮЈз§Қзӣ®зҡ„жҳҜи§ЈйҮҠдёҖдёӘеҸҳйҮҸеҜ№еҸҰеӨ–дёҖдёӘеҸҳйҮҸзҡ„еҪұе“Қзҡ„й—®йўҳгҖӮд№ҹжҳҜз»Ҹе…ёз»ҹи®ЎдёӯжңҖеёёз”ЁеҲ°зҡ„жЁЎеһӢгҖӮеҸҳеҢ–еҶҚеӨҡдёҖдәӣпјҢйқһзәҝжҖ§жЁЎеһӢпјҢйқһеҸӮжЁЎеһӢпјҢжӣҙзҒөжҙ»пјҢйҖүжӢ©жӣҙеӨҡпјҢжүҖд»ҘеҸҜиғҪиҫҫеҲ°жӣҙеҘҪзҡ„йў„жөӢж•ҲжһңгҖӮдҪҶжҳҜеҫҖеҫҖжҜ”иҫғйҡҫи§ЈйҮҠxеҜ№yзҡ„еҪұе“ҚгҖӮпјҲиҝҷдәӣжЁЎеһӢйғҪжқҘжәҗдәҺз»ҹи®ЎпјҢжҺЁе№ҝдәҺжңәеҷЁеӯҰд№ гҖӮиҝҷдәӣжЁЎеһӢйғҪжҳҜеҮ еҚҒе№ҙеүҚз»ҹи®Ўзҡ„з ”з©¶жҲҗжһңдәҶеҘҪд№ҲпјҒпјҒеӣ дёәжңҖиҝ‘и®Ўз®—жңәйҖҹеәҰжҸҗдёҠжқҘдәҶпјҢеҺҹжқҘжІЎеҗҚж°”пјҢжҳҜеӣ дёәи®Ўз®—йҖҹеәҰеёҰдёҚеҠЁпјҢж•°жҚ®жІЎж”¶йӣҶиҫЈд№ҲеӨҡе•ҠпјҒпјҒпјүпјҒеӣ дёәжңәеҷЁеӯҰд№ йўҶеҹҹзҡ„ж•°жҚ®еӨ§пјҢиҝҗз®—иғҪеҠӣејәпјҢжүҖд»ҘиғҪжҠҠеӨҚжқӮзҡ„йқһеҸӮжҲ–иҖ…йқһзәҝжҖ§жЁЎеһӢз”Ёзҡ„ж•ҲжһңжҜ”иҫғеҘҪгҖӮ
з»Ҹе…ёз»ҹи®Ўе’ҢжңәеҷЁеӯҰд№ еҲҶеҲ«еңЁе“ӘдәӣйўҶеҹҹжңүдјҳеҠҝпјҹ
еңЁдёҖдәӣдј з»ҹйўҶеҹҹпјҢе·ҘзЁӢе®һйӘҢпјҢз”ҹзү©иҜ•йӘҢпјҢзӨҫдјҡи°ғжҹҘпјҢзү©зҗҶе®һйӘҢпјҢжҲ‘们иғҪиҺ·еҫ—зҡ„ж•°жҚ®йҮҸйқһеёёе°ҸпјҢжҲ‘们еҝ…йЎ»е°Ҹеҝғзҝјзҝјзҡ„еҜ№еҫ…жҲ‘们зҡ„жЁЎеһӢпјҢд»Һжңүйҷҗзҡ„ж•°жҚ®дёӯжҸҗеҸ–е°ҪйҮҸеҸҜиғҪеӨҡзҡ„дҝЎжҒҜгҖӮжҠ‘жҲ–жҳҜдёҖдәӣеҜ№еҸӮж•°еҫҲж•Ҹж„ҹзҡ„йў„жөӢпјҢе·®д№ӢжҜ«еҺҳеӨұд№ӢеҚғйҮҢпјҢжҜ”еҰӮжЈҖйӘҢдёҖдёӘиүҫж»Ӣз—…ж–°иҚҜзү©жҳҜеҗҰжңүж•ҲпјҢжқҘеҶіе®ҡиҰҒдёҚиҰҒжҠ•е…ҘfundingеҺ»иҝӣиЎҢз ”еҸ‘пјҢжҲ‘们е°ұиҰҒз”ЁдёҘи°Ёзҡ„жҰӮзҺҮз»ҹи®ЎжЁЎеһӢгҖӮ
дҪҶжҳҜеңЁжҗңзҙўеј•ж“ҺпјҢж·ҳе®қз”ЁжҲ·иҙӯд№°дҝЎжҒҜпјҢдәәи„ёзү№еҫҒиҜҶеҲ«зӯүйўҶеҹҹпјҢжҲ‘们иғҪеӨҹиҺ·еҫ—еҫҲеӨ§йҮҸзҡ„ж•°жҚ®пјҢиҖҢдё”ж•°жҚ®з»ҙеәҰд№ҹйқһеёёй«ҳпјҢз”Ёдј з»ҹж–№ејҸе»әжЁЎпјҢеҫҲжңүеҸҜиғҪз»ҙеәҰй«ҳеҲ°дёҘи°Ёзҡ„functionж №жң¬и§ЈдёҚеҮәжқҘпјҢжңәеҷЁеӯҰд№ зҡ„зҗҶи®әе°ұйқһеёёжңүж•ҲдәҶгҖӮ
дёәд»Җд№Ҳжҗһз»ҹи®ЎеӯҰзҡ„еҘҪеӨҡйғҪеҺ»еҒҡжңәеҷЁеӯҰд№ дәҶпјҹеӯҰжңҜз•ҢеҸҜиғҪдёҚжҳҜиҝҷж ·пјҢдҪҶеҜ№дәҺдёҖиҲ¬дәәжқҘи®ІпјҢзЎ®е®һе·®дёҚеӨҡгҖӮеӨ§йғЁеҲҶзҡ„дёҡз•ҢеҺҹеӣ жҲ‘жҜ”иҫғи®ӨеҸҜе®ӢдёҖжқҫзҡ„иҜҙжі•гҖӮжҲ‘дёҚи®ӨеҸҜиҜҙжңәеҷЁеӯҰд№ жӣҙжіЁйҮҚйў„жөӢпјҢз»ҹи®ЎжӣҙжіЁйҮҚйҳҗйҮҠпјҢдҪ зңӢзңӢжңәеҷЁеӯҰд№ йҮҢеҶіе®ҡж ‘зҡ„йҳҗйҮҠж•Ҳжһңе·®д№ҲпјҢз»ҹи®ЎзңҹдёҚжіЁйҮҚйў„жөӢд№Ҳ(stepwise иҝҷз§ҚзәҜйў„жөӢз»ҹи®ЎеҹәзЎҖе·Ҙе…·иҰҒе“ӯдәҶпјүгҖӮиҜҙжңәеҷЁеӯҰд№ еҫҲйҡҫдҝқиҜҒе®ҢеӨҮжҖ§е’ҢзЁіе®ҡжҖ§зҡ„, йӮЈvalidation еҸҲеҒҡжқҘе№Ід»Җд№ҲпјҢиҖҢдё”abnormal case analysis дёҚеә”иҜҘжҳҜеҚ•зӢ¬зҡ„дёҖй—ЁеӯҰй—®д№ҲпјҢиҮідәҺең°йңҮд»Җд№Ҳзҡ„пјҢйҖҡеёёеҒҡжі•жҳҜд№°дҝқйҷ©еҗ§гҖӮгҖӮгҖӮ
з»ҹи®Ўи·ҹжңәеҷЁеӯҰд№ еңЁеә”з”ЁеұӮйқўдёҠж №жң¬зҡ„е·®еҲ«жҳҜд»Җд№Ҳпјҹ
иҝҳжҳҜйӮЈеҸҘиҖҒиҜқпјҢж— и®әжҳҜдј з»ҹзҡ„з»ҹи®ЎпјҢиҝҳжҳҜиҙқеҸ¶ж–Ҝз»ҹи®ЎпјҢз»ҹи®Ўж°ёиҝңйғҪжҳҜеңЁз”Ёж ·жң¬дј°и®ЎжҖ»дҪ“зү№еҫҒгҖӮиҖҢзӨҫдјҡ科еӯҰз ”з©¶зҡ„дё»иҰҒе°ұжҳҜдәәзұ»иҝҷдёӘеӨ§жҖ»дҪ“гҖӮ
дҪ еҶҚзңӢзңӢжңәеҷЁеӯҰд№ зҡ„еә”з”Ёж–№йқўпјҢ
дә’иҒ”зҪ‘дјҒдёҡжҲ–银иЎҢдёҡжҳҜзӣҙжҺҘжҺҢжҸЎдәҶжҖ»дҪ“зҡ„ж•°жҚ®е•ҠпјҢжҲ–иҖ…иҜҙеҜ№дәҺ他们зҡ„еә”з”ЁжқҘи®ІпјҢдёҚйңҖиҰҒдј°и®ЎдёҖдёӘжӣҙеӨ§зҡ„жҖ»дҪ“дәҶе•ҠпјҢеҸӘиҰҒз ”з©¶д»–д»¬з”ЁжҲ·жң¬иә«е°ұи¶іеӨҹдәҶгҖӮ
жүҖд»ҘдҪ дјҡз”ұжӯӨеҸ‘зҺ°дёӨиҖ…дҪҝз”Ёзҡ„е·®еҲ«жҳҜеҰӮжӯӨзҡ„е·ЁеӨ§гҖӮе°ұжӢҝдёҖдёӘеҹәжң¬зҡ„feature selectionдҪңеҜ№жҜ”дҫӢеӯҗгҖӮ
дј з»ҹз»ҹи®ЎеӯҰж–№жі•пјҡANOVA and ANCOVA, Best subset, LASSO and Ridge, PCA
жңәеҷЁеӯҰд№ ж–№жі•пјҡDecision TreeпјҲеҪ“然иҝҳеҸҜд»Ҙз”ұжӯӨиЎҚз”ҹеҮәrandom forest, gradient boosting, etc.пјү
зңӢзңӢдёҠиҫ№зҡ„пјҢжҳҜдёҚжҳҜжңүзҡ„ж¶үеҸҠжңҖеӨ§дјјз„¶дј°и®ЎпјҢдј°и®Ўзҡ„жҳҜд»Җд№ҲпјҢжҳҜжҖ»дҪ“е•ҠгҖӮжңүзҡ„ж¶үеҸҠеҮҸе°Ҹж–№е·®жҚҹеӨұпјҢдёәд»Җд№ҲпјҢд№ҹжҳҜдёәдәҶжҖ»дҪ“иҖғиҷ‘е•ҠгҖӮ
дҪ еҶҚзңӢзңӢдёӢиҫ№зҡ„пјҢеҸӘиҰҒеҲҶзҡ„жңҖжңүз”Ёе°ұеҘҪгҖӮжҖҺд№Ҳз®—жңүз”ЁпјҢжҜ”еҰӮиҜҙtest case зҡ„mseжңҖе°ҸпјҢжҲ‘дёҚйңҖиҰҒдј°и®Ўtest case зҡ„еҲҶеёғпјҢеӣ дёәжҲ‘д»Һtraing caseйҮҢе®Ңе…ЁзҹҘйҒ“гҖӮиҝҷд№ҹз®—жҳҜеӨ§ж•°жҚ®зҡ„еҠӣйҮҸеҗ§гҖӮ
еңЁжҜ”еҰӮиҜҙеҜ№дәҺunbalanced data setпјҡ
дј з»ҹз»ҹи®ЎеӯҰж–№жі•еңЁglmйҮҢеҗ„з§Қmixed modeling (or hierarchical modelingпјүиҝҳиҰҒйҳІover-dispersionпјҢ 究其еҺҹеӣ иҝҳжҳҜиҰҒдј°и®ЎжҖ»дҪ“гҖӮ
жңәеҷЁеӯҰд№ ж–№жі•жңҖзӣҙжҺҘзҡ„е°ұжҳҜSMOTE, зӣҙжҺҘеҲ¶йҖ жӣҙеӨҡзҡ„minority caseд»ҘеҸҠеҮҸе°‘majority caseпјҢд№ҹжҳҜе®Ңе…ЁдёҚз”Ёз®ЎжҖ»дҪ“еҲҶеёғзҡ„гҖӮ
-informative distribution vs data talks-
еҫҲеӨҡз»ҹи®Ўзҡ„е·ҘдҪңжҳҜеҹәдәҺйқһеёёжңүйҒ“зҗҶзҡ„еҜ№дәҺдё–з•Ңзҡ„зҗҶи§Јзҡ„гҖӮ жҜ”еҰӮиҜҫжң¬дёҠзҡ„еҮ дёӘдҫӢеӯҗпјҡ
йӘ°еӯҗдёӘйқўжҰӮзҺҮеқҮзӯү
nдёӘзӢ¬з«Ӣз”ҹдә§зҡ„жңәеҷЁпјҢеңЁ1е°Ҹж—¶еҶ…жҚҹеқҸnеҸ°зҡ„жҰӮзҺҮжңҚд»ҺдјҜеҠӘеҲ©еҲҶеёғ
з”өеӯҗеҷЁд»¶зҡ„еҜҝе‘ҪжңҚд»ҺжҢҮж•°еҲҶеёғ
ж”ҫе°„жҖ§зү©иҙЁзҡ„иҫҗе°„жңҚд»ҺжіҠжқҫеҲҶеёғ
иҝҷеҮ дёӘдҫӢеӯҗйғҪжҳҜйӮЈз§Қз»Ҷжғіиө·жқҘи§үеҫ—и¶…зә§жңүйҒ“зҗҶзҡ„
еҰӮжһңеҜ№дәҺдёҖдёӘй—®йўҳ жҲ‘们жҠҠж–№ж–№йқўйқўйғҪеҲҶжһҗжё…жҘҡ е»әжЁЎжё…жҘҡ еҗҢж—¶иҝҷдёӘжЁЎеһӢдёҺзҺ°е®һж•°жҚ®еҗ»еҗҲзҡ„еҫҲеҘҪ жҲ‘们еҝғйҮҢдјҡжңүжһҒеӨ§зҡ„ж»Ўи¶і и®ӨдёәиҝҷдёӘжЁЎеһӢеҒҘ壮并且"жӯЈзЎ®"
дҪҶжҳҜ еҰӮguilin liжүҖиҜҙ еҜ№дәҺдәәи„ёиҜҶеҲ«й—®йўҳ жҲ‘们е®һеңЁжҳҜз»ҷдёҚеҮәд»Җд№ҲжңүйҒ“зҗҶзҡ„distributionпјҢжүҖд»Ҙиҝҷз§ҚйқһеёёжңүдҝЎжҒҜйҮҸзҡ„distributionжҲ‘们зҺ©дёҚдёӢеҺ»дәҶ
и®©жҲ‘们жҠҠdistributionзҡ„й—®йўҳжҠӣдёҖиҫ№ еҒҮи®ҫжҲ‘们жңүдёҖдёӘжЁЎеһӢ дёҚз®Ўе®ғжңүжІЎжңүжҰӮзҺҮж„Ҹд№ү еҰӮжһңе®ғеңЁжһҒеӨ§зҡ„д»Һе…ЁдҪ“дёӯйҡҸжңәжҠҪж ·зҡ„ж•°жҚ®йӣҶ з”ҡиҮіе°ұжҳҜжҖ»дҪ“дёҠжңүжһҒеҘҪзҡ„иЎЁзҺ° е“ӘжҖ•иҝҷдёӘжЁЎеһӢжҳҜй»‘зӣ’ жҲ‘们д№ҹдјҡеҜ№иҝҷдёӘжЁЎеһӢжңүдҝЎеҝғ иҷҪ然еҰӮжһңиҝҷдёӘжЁЎеһӢдёҚйӮЈд№ҲжјӮдә® еҸ—иҝҮеӨӘеӨҡж•°еӯҰи®ӯз»ғзҡ„дәәдјҡеҸ‘иҮӘеҝғеә•зҡ„и®ЁеҺҢ дҪҶжҳҜи°ҒйғҪдёҚиғҪеҗҰе®ҡе®ғзҡ„жңүж•ҲжҖ§ иҝҷз§ҚжҖқи·Ҝ жӣҙеғҸжҳҜжңәеҷЁеӯҰд№ зҡ„жҖқи·Ҝ
жҲ‘жғіеҶҚиҜҙдёҖйҒҚ жҲ‘зӣҙеҲ°д»ҠеӨ©йғҪи§үеҫ—иҝҷз§ҚжҖқи·ҜдёҚжјӮдә® дҪҶжҳҜе®ғwork
иҝҷз§ҚжҖқи·Ҝзҡ„дёҖдёӘеӨ§й—®йўҳжҳҜ еҰӮжһңжҲ‘们зҡ„жөӢиҜ•ж•°жҚ®дёҚиғҪд»ЈиЎЁжҖ»дҪ“ жҜ”еҰӮ@йҪҗй№Ҹ зҡ„иӮЎзҘЁйў„жөӢдҫӢеӯҗ жҲ‘们зҡ„жөӢиҜ•ж•°жҚ®дёӯдёҚеҢ…еҗ«и¶іеӨҹзҡ„ж”ҝеәңиЎҢдёә еҗҢж ·д№ҹдёҚеҢ…еҗ«зӣёеә”зҡ„зү№еҫҒ йӮЈд№ҲеӨұж•Ҳд№ҹжҳҜеҝ…然зҡ„ иҝҷдёҚжҳҜжңәеҷЁеӯҰд№ зҡ„й—®йўҳ иҖҢжҳҜйғЁеҲҶеҒҡжңәеҷЁеӯҰд№ зҡ„дәәд№ жғҜдәҶжңүд»Җд№Ҳж•°жҚ®е°ұз”Ёд»Җд№Ҳж•°жҚ® дёҚиӮҜж·ұе…Ҙзҡ„иҖғиҷ‘й—®йўҳ еҗҢж—¶д№ҹж»Ўи¶ідәҺеҪ“дёӢwork
-How to do model selection-
жҲ‘们йғҪиҜҙdata talk дҪҶжҳҜжңәеҷЁеӯҰд№ йўҶеҹҹзЎ®е®һжңүдёҖдёӘдёҚеҘҪзҡ„йЈҺж°” еҫҲеӨҡи®әж–ҮйҮҢйқўжІЎжңүerror barгҖӮжҲ‘еҝ…йЎ»еҗҗж§ҪдёҖдёӢ жҜ”еҰӮmnistж•°жҚ®йӣҶдёҠи®°еҪ•дәҶdeep learningзҡ„жңҖж–°error rate дҪҶжҳҜ mnistиҝҷдёӘж•°жҚ®йӣҶеӨӘе°ҸдәҶ д»ҠеӨ©д»»дҪ•improvementйғҪдёҚеҸҜиғҪжҳҜз»ҹи®Ўжҳҫи‘—зҡ„ з”ЁиҙқеҸ¶ж–Ҝз»ҹи®ЎеӯҰзҡ„жҖқи·ҜеҸҜд»Ҙиҝҷд№ҲиҜҙ еҰӮжһңжҲ‘们еҜ№дәҺж·ұеәҰеӯҰд№ ж–№жі•зҡ„дҝЎеҝғжҳҜ50еҲҶпјҢзңӢеҲ°е®ғеңЁmnistдёҠеҸҲжҸҗеҚҮдәҶ0.1 дёҖдёӘзҗҶжҷәзҡ„дәәзҡ„дҝЎеҝғжҸҗеҚҮд№ҹе°ұжҳҜ0.01иҝҷз§Қж ·еӯҗ еӣ дёәиҝҷдёӘжҸҗеҚҮеӨӘжңүеҸҜиғҪжҳҜе®һйӘҢи®ҫзҪ®еј•е…Ҙзҡ„йҡҸжңәжҖ§дәҶ
еүҚж®өж—¶й—ҙзҹҘд№ҺйҮҢйқўи®Ёи®ә еҝғзҗҶеӯҰйўҶеҹҹйҮҢйқўйғҪејҖе§ӢйҖҗжёҗи§үеҫ—p valueйғҪдёҚйқ и°ұдәҶ еӣ дёәй”ҷиҜҜзҡ„дҪҝз”ЁеҒҮи®ҫжЈҖйӘҢеҜјиҮҙе®һйӘҢдёҚеҸҜйҮҚеӨҚ и®әж–ҮдёӯеЈ°з§°зҡ„зҺ°иұЎеҫҲеҸҜиғҪж №жң¬дёҚеӯҳеңЁ еҸҜжҳҜжңәеҷЁеӯҰд№ йўҶеҹҹйҮҢйқўеҫҲеӨҡд»ҺдёҡиҖ…з”ҡиҮід»ҺжқҘдёҚз”Ёp value е°ұз®—жҳҜз”Ёcross validationпјҢд№ҹдёҚзңӢvarianceпјҢеҸӘзңӢmean иҝҷдёӘйўҶеҹҹиҝҳиғҪиҝӣжӯҘ жҲ‘д№ҹеҫҲд»”з»ҶжҖқиҖғиҝҮ еӢүејәиҜҙжңҚдәҶиҮӘе·ұ дҪҶжҳҜжҲ‘еҫҲйңҮжғҠ
еҜ№дәҺд»»дҪ•дёҖ家公еҸё еҰӮжһңеңЁи§ЈиҜ»ж•°жҚ®зҡ„ж—¶еҖҷжІЎжңүз»ҹи®Ўж„ҸиҜҶ е®ғйқһеёёеҸҜиғҪдёҖдёӘеӣўйҳҹиҫӣиҫӣиӢҰиӢҰе·ҘдҪңдәҶ1е№ҙ жҜҸж¬ЎreleaseйғҪжңүиҝӣжӯҘ дҪҶжҳҜдёҖе№ҙдёӢжқҘеҸ‘зҺ°жҢҮж ҮеҸҲжҷғжҷғжӮ жӮ еӣһеҲ°еҺҹзӮ№ 然еҗҺеӨ§е®¶еҸҲзј–еҮәдёҖдәӣйҒ“зҗҶи§ЈйҮҠдёәд»Җд№ҲиҝҷдёӘжҢҮж ҮжңүиҮӘ然дёӢйҷҚи¶ӢеҠҝ еӨҡдәҸжҲ‘们зҡ„еҠӘеҠӣеңЁи®©е®ғkeepеңЁиҝҷдёӘдҪҚзҪ® жҲ‘зңҹжҳҜеҝҚдёҚдҪҸжғіиҜҙ дҪ 们敢дёҚж•ўжҠҠиҝҷдёҖе№ҙеҒҡзҡ„е·ҘдҪңжҖ»дҪ“жқҘеҒҡдёҖдёӘеҜ№з…§е®һйӘҢ зңӢзңӢеҲ еҺ»е®ғ们зңҹзҡ„жңүжҳҫи‘—зҡ„дёӢйҷҚеҗ—пјҹ жңүзҡ„ж—¶еҖҷзңҹдёәеӨ§е®¶жҚҸдёҖжҠҠжұ— иҝҷд№ҲеӨҡдәәзҡ„йқ’жҳҘ е°ұеӣ дёәдёҚйҮҚи§Ҷз»ҹи®Ў ж•ҙеӨ©иў«йҡҸжңәжҖ§зҺ©еј„
жүҖд»ҘдҪҶеҮЎеӨ§е®¶еңЁиҜ„д»·жЁЎеһӢж—¶ еҝғйҮҢеӯҳжңүз»ҹи®Ўж„ҸиҜҶ е…·дҪ“дҪҝз”Ёдј з»ҹеҒҮи®ҫжЈҖйӘҢиҝҳжҳҜдҪҝз”ЁbicжҲ–иҖ…cross validationпјҢжҲ‘йғҪи§үеҫ—жҳҜе°ҸиҠӮдәҶ жңәеҷЁеӯҰд№ е·Ҙе…·еҢ…йҮҢиҮӘеёҰзҡ„жЁЎеһӢжЈҖйӘҢж–№жі•еңЁеҫҲеӨҡж—¶еҖҷжҳҜдёҚеӨҹзҡ„ еӣ дёәиҝҷдёӘйўҶеҹҹзҡ„йЈҺж°”еҰӮжӯӨ е°ұз®—дёҚжғіеӯҰеӨӘеӨҡдёңиҘҝ иҮіе°‘дёҚиҰҒжҠҠеҢ…йҮҢзҡ„ж–№жі•еҪ“жҲҗй»‘зӣ’ дёҖе®ҡиҰҒи®ӨзңҹзҗҶи§Ј жЁЎеһӢйҖүжӢ©жҜ”е…·дҪ“з®—жі•жӣҙйҮҚиҰҒ
-дёәд»Җд№ҲжңәеҷЁеӯҰд№ жңүйҒ“зҗҶ-
йҮҚж–°зңӢ第дёҖиҠӮ жҲ‘иҜҙеҫҲеӨҡз»ҹи®Ўж–№жі•еҫ—еҲ°жүҫеҲ°дёҖдәӣзү№еҲ«жңүйҒ“зҗҶзҡ„distribution еҫ—еҲ°дёҖдёӘжјӮдә®жЁЎеһӢ иҖҢжңәеҷЁеӯҰд№ ж–№жі•зңӢиө·жқҘдёҚжјӮдә®жІЎйҒ“зҗҶ
е…¶е®һд»ҺжҹҗдёӘи§’еәҰиҜҙд№ҹжҳҜжңүйҒ“зҗҶзҡ„ д»ҠеӨ©дәә们еӨ„зҗҶзҡ„й—®йўҳеӨӘеӨҚжқӮдәҶ зңҹзҡ„еҫҲйҡҫеҫ—еҲ°зү№еҲ«з®ҖжҙҒжјӮдә®зҡ„жЁЎеһӢ дәәзҡ„зӣҙи§үз»ҷдёҚеҮәд»Җд№Ҳжңүж„Ҹд№үзҡ„е…ҲйӘҢд№ҹжӯЈеёё
жүҖд»ҘжңәеҷЁеӯҰд№ еҶҚж¬Ўиө°дәҶdata talkзҡ„и·Ҝ жҜ”еҰӮжңҖеӨ§зҶөжЁЎеһӢ жҲ‘дёҚзҹҘйҒ“зңҹжӯЈзҡ„еҲҶеёғжҳҜд»Җд№Ҳж · жҲ‘жүҫеҲ°дёҖдәӣзү№еҫҒ жҲ‘и§үеҫ—иҝҷдәӣзү№еҫҒзҡ„з»ҹи®ЎдҝЎжҒҜи¶іеӨҹзЁіе®ҡеңЁжңӘжқҘеҸҜд»ҘйҮҚзҺ° йҷӨдәҶиҝҷдәӣзү№еҫҒ жҲ‘еқҰ然жүҝи®ӨиҮӘе·ұзҡ„ж— зҹҘ з”ЁжңҖеӨ§зҶөжқҘе»әжЁЎж— зҹҘ иҝҷе°ұеҫ—еҲ°дәҶlogistic regression иҝҷдәӣзү№еҫҒзҡ„еҸӮж•°е°ұз•ҷз»ҷж•°жҚ®жқҘеҶіе®ҡеҗ§ naive bayesзҡ„жқЎд»¶зӢ¬з«ӢжҖ§зңӢиө·жқҘжҳҜдёҖдёӘеҫҲејәзҡ„еҒҮи®ҫ е…¶е®һд№ҹеҸҜд»Ҙд»ҺжңҖеӨ§зҶөжҺЁеҮәжқҘ жүҖд»Ҙ жқЎд»¶зӢ¬з«ӢжҖ§дёҚжҳҜдёҖдёӘеӨ–еҠ зҡ„ејәеҒҮи®ҫ иҖҢжҳҜж— зҹҘзҡ„з»“жһң ж— зҹҘжҳҜдёҖдёӘжҜ”жғіиұЎдёӯејәеӨ§еҫҲеӨҡзҡ„зҹҘиҜҶ
жңҖеӨ§зҶөж–№жі•еҸҜд»ҘзңӢжҲҗдёҖз§Қnon informative prior bayesianж–№жі•пјҢд№ҹжҳҜдёҖз§Қempirical bayesж–№жі• zhang cosmosиҝҳи°ҲеҲ°еҫҲеӨҡжңәеҷЁеӯҰд№ жЁЎеһӢеҸҜд»ҘзңӢжҲҗжҳҜnon parametric method жҳҜзҡ„ жңәеҷЁеӯҰд№ е°ұжҳҜеңЁдҪҝз”ЁиҝҷдәӣдёҮиғҪзҡ„prior or distribution or method 然еҗҺжҠҠдёҚдёҮиғҪзҡ„дёңиҘҝ жҜ”еҰӮд»Җд№Ҳзү№еҫҒеңЁжңӘжқҘжҳҜеҸҜйҮҚзҺ°зҡ„ жҠҠиҝҷдёӘзҢңжөӢзҡ„жқғеҲ©з•ҷз»ҷе·ҘзЁӢеёҲ е“Ҳе“Ҳ еҸҚжӯЈзҗҶи®әжҳҜеҜ№зҡ„ дҪ иҮӘе·ұзҢңй”ҷдәҶеҲ«жҖӘжҲ‘ жүҖд»ҘжүҚзңӢиө·жқҘж— жүҖдёҚиғҪ(иӨ’д№ү) жүҖд»Ҙе…¶е®һжңәеҷЁеӯҰд№ зҗҶи®әзңҹзҡ„иӣ®зҫҺзҡ„ иҰҒеҗҗж§Ҫд№ҹеҸӘиғҪеҗҗж§ҪжҲ‘们иҝҷдәӣе·ҘзЁӢеёҲж»Ҙз”Ё
жңүдәӣж—¶еҖҷжңәеҷЁеӯҰд№ иғҪиҜҙеҮәйҒ“йҒ“ жңүзҡ„ж—¶еҖҷд№ҹдёҚиЎҢ жҜ”еҰӮзәҝжҖ§еӣһеҪ’ дёҘж јжқҘиҜҙ жҲ‘们用зәҝжҖ§еӣһеҪ’зҡ„ж—¶еҖҷ жҲ‘们йҖҡ常并дёҚзҹҘйҒ“ж•°жҚ®жҳҜдёҚжҳҜзәҝжҖ§зҡ„ з»ҹи®ЎеӯҰ家иҰҒзҫһзӯ”зӯ”зҡ„иҜҙ д»»дҪ•еҮҪж•°йғҪеҸҜд»Ҙз”Ёжі°еӢ’е…¬ејҸеҲҶи§ЈеҮәзәҝжҖ§жҲҗеҲҶ жңәеҷЁеӯҰд№ е·ҘзЁӢеёҲ们其е®һжғізҡ„жҜ”иҫғе°‘ д»»дҪ•дёҖдёӘжңәеҷЁеӯҰд№ з®—жі•йғҪжҳҜдёҖдёӘдҝЎжҒҜжҠҪеҸ–еҷЁ е°ұеҘҪеғҸдё–з•Ңжңүдё°еҜҢзҡ„йўңиүІ дҪҶжҳҜеҒҮи®ҫжңәеҷЁеӯҰд№ е·ҘзЁӢеёҲдёҚзҹҘйҒ“иҝҷдёӘдё–з•ҢжңүйўңиүІиҝҷдёӘжҰӮеҝө 他们д№ҹеёёеёёдёҚзҹҘйҒ“жүӢдёҠжӢҝзҡ„иҝҷдёӘжЁЎеһӢеҸ«еҒҡзәўиүІж»Өй•ң еҸҚжӯЈиҰҒжҳҜз”Ёиө·жқҘwork з»“жһңеҘҪ жҲ‘з®Ўе®ғзәҝжҖ§иҝҳжҳҜзәўиүІ з®Ўе®ғдёәд»Җд№Ҳ жҲ‘е°ұзҹҘйҒ“иҝҷдёӘж»Өй•ңиғҪжҠҪеҸ–дёҖдәӣжңүз”Ёзҡ„дҝЎжҒҜ жҲ‘з®Ўе®ғиҝҮж»ӨжҺүдәҶеӨҡе°‘е…¶д»–жңүз”ЁдҝЎжҒҜ еҶҚиҜҙдёҖж¬Ў еҸӘиҰҒжөӢиҜ•ж•°жҚ®и¶іеӨҹжңүд»ЈиЎЁжҖ§ иҝҷж ·еҒҡжҳҜworkзҡ„ жүҖд»Ҙе’ұ们е·ҘзЁӢеёҲд№ҹдёҚз”ЁиҮӘеҚ‘
еңЁе·Ҙдёҡз•Ңж··д№…дәҶ жҲ‘жңүзҡ„ж—¶еҖҷд№ҹи§үеҫ—иҝҷз§Қзіҷеҝ«зҢӣзҡ„ж–№жі•зҲҪзҡ„еҫҲ
иҝҷз§ҚжҖқи·Ҝд№ҹжҺЁиҝӣдәҶжңәеҷЁеӯҰд№ зҡ„дә§дёҡеҢ– дҪҶжҳҜеғҸи°·жӯҢжөҒж„ҹйў„жөӢжЁЎеһӢеӨұж•Ҳиҝҷж ·зҡ„дҫӢеӯҗ жҲ–иҖ…йҪҗй№ҸиҜҙзҡ„иӮЎзҘЁйў„жөӢзҡ„дҫӢеӯҗ иҝҳжңүзұ»дјјдәҺйҮ‘иһҚиЎҢдёҡзҡ„й»‘еӨ©й№…(дёҠдёҖж¬ЎжҳҜз»ҹи®ЎеӯҰ家зҡ„еӨұиҙҘдёӢдёҖж¬ЎиҜҘиҪ®еҲ°жңәеҷЁеӯҰд№ дё“е®¶дәҶ) жҲ‘и§үеҫ—еҝ…然иҝҳдјҡеҮәзҺ°зҡ„
-жңәеҷЁеӯҰд№ дёҚеҸӘжҳҜз»ҹи®Ў-
еҫҲеӨҡжңӢеҸӢиҜҙдәҶ жңәеҷЁеӯҰд№ еңЁи®Ўз®—еӨҚжқӮеәҰдёҠжңүеҫҲеӨҡзҡ„ж”№иҝӣ жӯӨеӨ– зҺ°еңЁеӨ§е®¶зҺ©зҡ„manifold д№ҹжҳҜеҫҲжңүи¶Јзҡ„жҖқи·Ҝ
-жңәеҷЁеӯҰд№ дёҚе…ЁжҳҜж•°еӯҰ-
е°ұз®—жҳҜsvmжҲ–иҖ…boostingиҝҷдәӣзҗҶи®әе·Із»ҸеҲҶжһҗзҡ„еҫҲйҖҸеҪ»зҡ„дёңиҘҝ жқҘдәҶдёҖдёӘж–°й—®йўҳ жҲ‘们д№ҹеҖҫеҗ‘дәҺеҗ„дёӘжЁЎеһӢйғҪиҜ•иҜ• еӣ дёәдәәзҡ„зӣҙи§үзңҹзҡ„еҫҲжҢ« дәәжІЎжі•д»ҺзҗҶи®әдёҠеҲӨж–ӯе“ӘдёӘжЁЎеһӢжңҖеҘҪзҡ„ sklearnзҪ‘з«ҷдёҠжңүдёҖдёӘdecision treeпјҢе“Ҳе“Ҳ пјҢеӨ§жҰӮиҜҙдәҶиҜҙз»ҸйӘҢд»Җд№Ҳй—®йўҳиҜҘз”Ёд»Җд№ҲжЁЎеһӢгҖӮиҝҷдёӘdecision treeе°ұе’ҢжңәеҷЁеӯҰд№ еӯҰеҮәжқҘзҡ„жЁЎеһӢдёҖж · е°ұжҳҜдёӘз»ҸйӘҢжЁЎеһӢзҪўдәҶ дҪ ж°ёиҝңдёҚзҹҘйҒ“иҝҷдёҖж¬Ўе®ғжҳҜдёҚжҳҜеҜ№зҡ„ еҸӘзҹҘйҒ“е®ғжҖ»дҪ“дёҠжӯЈзЎ®
жңәеҷЁеӯҰд№ йўҶеҹҹж°ёиҝңйғҪдёҚдјҡжҳҜзәҜзІ№зҡ„ж•°еӯҰ з»ҸйӘҢеҫҲйҮҚиҰҒ дәәи„‘жҳҜдёҖдёӘејәеӨ§зҡ„еӯҰд№ еҷЁ еҸҜд»Ҙе……еҲҶеҲ©з”Ёеҗ„з§ҚиғҢжҷҜзҹҘиҜҶжқҘйҒҝе…Қoverfitting д»ҺжңүйҷҗеҮ дёӘдёҚз»ҹи®Ўжҳҫи‘—зҡ„ж ·жң¬дёӯд»Ҙиҫғй«ҳзҡ„жӯЈзЎ®зҺҮеҫ—еҮәз»“и®ә иҝҷеңЁе…¶д»–еӯҰ科дёӯе·Із»Ҹеҫ—еҲ°дәҶиҜҒжҳҺ дјҪеҲ©з•ҘйӮЈеҮ дёӘжҖқжғіе®һйӘҢж №жң¬дёҚиғҪвҖңиҜҒжҳҺвҖқзү©дҪ“жңүжғҜжҖ§ д»–еҪ“ж—¶зҡ„е®һйӘҢзІҫеәҰд№ҹж №жң¬е°ұиҜҒжҳҺдёҚдәҶ дҪҶжҳҜеӨҡдәҸдәҶиҝҷз§ҚеӨ§иғҶзҡ„з»ҸйӘҢзӣҙи§үе’ҢзҢңжөӢ 科еӯҰжүҚиғҪиө°еҲ°д»ҠеӨ©
д»ҺиҝҷдёӘи§’еәҰиҜҙ жҲ‘и§үеҫ—жңәеҷЁеӯҰд№ еңЁз»ҹи®ЎеӨ§йҮҸзјәдҪҚзҡ„жғ…еҶөдёӢиө°еҲ°д»ҠеӨ© жң¬иә«е°ұиҜҒжҳҺдәҶдәәи„‘жҳҜеӨҡд№ҲејәеӨ§ еҸҜд»ҘеңЁдёҚдёҘи°Ёзҡ„жғ…еҶөдёӢйқ sense иҘҝж–№ж–ҮеҢ–дёӯзҡ„ж•°еӯҰдёҖд№Ұдёӯи°ҲеҲ° е“ҘзҷҪе°јзҡ„жЁЎеһӢйҰ–ж¬ЎжҸҗеҮәзҡ„ж—¶еҖҷеңЁзІҫеәҰдёҠе…¶е®һдёҚеҰӮжҲҗзҶҹзҡ„жүҳеӢ’еҜҶжЁЎеһӢ е“ҘзҷҪе°јжң¬иҙЁдёҠжҳҜдёҖдёӘж•°еӯҰ家 д»–зҡ„и§ӮзӮ№жҳҜ иҝҷдёӘжЁЎеһӢжҳҜзҫҺзҡ„ жүҖд»Ҙе®ғжҳҜжӯЈзЎ®зҡ„ иҝҷз§ҚеңЁеҝ…иҰҒзҡ„ж—¶еҖҷеҝҪи§ҶзҺ°е®һ зӣёдҝЎзҗҶеҝө з®ҖзӣҙеӨӘд№ұжқҘдәҶ еҸҜжҳҜд№ҹеӨӘејәеӨ§дәҶ жҲ‘们д»ҠеӨ©з®Ўе“ҘзҷҪе°јзҡ„иЎҢдёәеҸ«еҘҘеҚЎе§ҶеүғеҲҖ еҸҜжҳҜ科еӯҰ家们иҝҳжңүжӣҙеӨҡж— жі•е‘ҪеҗҚзҡ„зӣҙи§ү
иҝҷд№ҹжҳҜжҲ‘иҜҙжңҚиҮӘе·ұзҡ„ж–№жі• еҝҪи§Ҷз»ҹи®Ўз®ҖзӣҙеӨӘд№ұжқҘдәҶ дёҚиҝҮзңӢжқҘзҺ°еңЁиҝҷдёӘйўҶеҹҹзҡ„зӣҙи§үиҝҳиғҪеё®дёҠеҝҷ
дҪҶжҳҜжңәеҷЁеӯҰд№ зҡ„еҮ ж¬ЎеӨ§иҝӣжӯҘ svm bootstrap lassoйғҪжқҘиҮӘз»ҹи®ЎеӯҰ家е’Ңж•°еӯҰ家 д№ҹиҜҙжҳҺдәҶдёҘж јжҖ§жҳҜеӨҡд№ҲйҮҚиҰҒ
и®©жҲ‘们зҘқжңәеҷЁеӯҰд№ еҘҪиҝҗпјҒ
еӣ зјҳйҷ…дјҡйҖҸиҝҮеҫ®дҝЎе…¬дј—еҸ·жӢңиҜ»дҪңиҖ…"жңәеҷЁеӯҰд№ дё“е®¶дёҺз»ҹи®ЎеӯҰ家и§ӮзӮ№дёҠжңүе“ӘдәӣдёҚеҗҢпјҹ"еӨ§дҪңпјҢжҲ‘з«Ӣ马еҲҶдә«з»ҷеҸ°еҢ—з ”еҸ‘дёӯеҝғзҡ„еҗҢдәӢпјҢ并且ccз»ҷз ”еҸ‘ж•ҷжҺҲеӣўдёҖдҪҚйҷҲж•ҷжҺҲпјҢйҷҲиҖҒеёҲжҳҜз•ҷзҫҺз»ҹи®ЎеӯҰеҚҡеЈ«пјҢжң¬иә«д№ҹиғҪж’°еҶҷиҝҗз®—зЁӢеәҸпјҢжҲ‘们公еҸё(API)ејҖеҸ‘зҡ„Smart engineе№іеҸ°пјҢжңүдёҖжЁЎеқ—"еӘ’дҪ“жҠ•иө„жЁЎжӢҹеҷЁ"е°ұжҳҜйҷҲиҖҒеёҲиһҚеҗҲз»ҹи®ЎдёҺи®Ўз®—зЁӢеәҸзҡ„дҪңе“ҒпјҢд»ҘдёӢжҳҜд»–еӣһеӨҚз»ҷжҲ‘зҡ„еҶ…ж–ҮпјҢжҲ‘жғіеә”иҜҘеҲҶдә«з»ҷиҝҷйҮҢзҡ„еҗҢеҘҪпјҢеӨ§е®¶ж•ҷеӯҰзӣёй•ҝпјҢзӣёдә’еӯҰд№ гҖӮ……………………………………………………
Dear James,
еңЁжӮЁжүҖеј•иҝ°зҡ„ж–Үз« дёӯпјҢRyan Adams иҜҙ: "жҲ‘и®Өдёәз»ҹи®ЎеӯҰе’ҢжңәеҷЁеӯҰд№ жңҖжң¬иҙЁзҡ„еҢәеҲ«еңЁдәҺж №жң¬зӣ®ж ҮдёҚеҗҢгҖӮз»ҹи®ЎеӯҰ家жӣҙе…іеҝғжЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§пјҢиҖҢжңәеҷЁеӯҰд№ дё“е®¶жӣҙе…іеҝғжЁЎеһӢзҡ„йў„жөӢиғҪеҠӣгҖӮвҖқ
иә«дёәдёҖдёӘд№ҹеңЁз ”究жңәеҷЁеӯҰд№ зҡ„з»ҹи®ЎеӯҰ家пјҢжҲ‘еҝ…йЎ»иҜҙпјҢд»–зҡ„и§’еәҰжҳҜй”ҷзҡ„пјҢжҲ–иҖ…иҜҙжҳҜеҒҸйўҮзҡ„гҖӮеӣ дёәпјҢз»ҹи®ЎеӯҰ家еҪ“然д№ҹе…іеҝғйў„жөӢиғҪеҠӣгҖӮ
з»ҹи®ЎеӯҰ家и·ҹжңәеҷЁеӯҰд№ дё“е®¶зҡ„е·®ејӮпјҢеңЁдәҺжңәеҷЁеӯҰд№ дё“е®¶еҫҲе°‘жңүжҮӮз»ҹи®Ўзҡ„пјҢдҪҶжҳҜз»ҹи®ЎеӯҰ家跨е…ҘеӯҰжңәеҷЁеӯҰд№ йўҶеҹҹеҚҙжҳҜйқһеёёе®№жҳ“гҖӮ
дәӢе®һдёҠпјҢжңәеҷЁеӯҰд№ жәҗдәҺдҝЎжҒҜ科еӯҰйўҶеҹҹ (Computer Science)пјҢдҪҶдҝЎжҒҜ科еӯҰжң¬иә«е№¶дёҚеғҸз»ҹи®ЎйўҶеҹҹйӮЈд№Ҳйҡҫе…Ҙй—ЁгҖӮдёҫдҫӢжқҘиҜҙпјҢжҲ‘еңЁзҫҺеӣҪз•ҷеӯҰзҡ„ж—¶еҖҷпјҢеҪ“ж—¶е°ұи§ҒеҲ°дёҚе°‘еӨ§йҷҶеҺ»еҝөд№Ұзҡ„еҘіеӯ©еӯҗд»Һдёӯж–Үзі»гҖҒеҺҶеҸІзі»зӯүж–Ү科йўҶеҹҹзӣҙжҺҘи·іеҲ°дҝЎжҒҜи®Ўз®—жңәзӣёе…із ”究жүҖпјҢиҖҢдё”йғҪеҫҲеҝ«е°ұиғҪиҝӣе…ҘзҠ¶еҶөгҖӮеҸҚиҝҮжқҘиҜҙпјҢиҰҒжҺҢжҸЎз»ҹи®Ўзӣёе…ідё“дёҡеҚҙдёҚжҳҜйӮЈд№Ҳе®№жҳ“гҖӮ
жҲ‘иҝҷеҚҒеҮ е№ҙжҢҮеҜјз»ҹи®Ўз ”з©¶з”ҹзҡ„еҝғеҫ—жҳҜпјҢ他们йҖҡеёёйғҪиғҪеңЁеҫҲеҝ«зҡ„ж—¶й—ҙеҶ…(дҫӢеҰӮеҚҠе№ҙ)жҗһе®ҡжңәеҷЁеӯҰд№ и·ҹзЁӢеәҸиҜӯиЁҖ(programming languages)зӣёе…ізҡ„дё“дёҡпјҢдҪҶжҲ‘们еҚҙж— жі•жңҹеҫ…дҝЎжҒҜи®Ўз®—жңә专家们еңЁдёӨдёүе№ҙеҶ…зҹҘйҒ“з»ҹи®ЎйўҶеҹҹзҡ„дё“дёҡзҹҘиҜҶгҖӮ
дёҚз®ЎжҳҜз»ҹ计专家жҲ–жңәеҷЁеӯҰд№ дё“е®¶пјҢз”ҡиҮіжҳҜеӨӘз©әзү©зҗҶеӯҰ家пјҢеҹәжң¬дёҠйғҪжҳҜжғіиҰҒе»әз«ӢжЁЎеһӢ(models)жқҘиҜ йҮҠиҝҷдё–з•Ңзҡ„з§Қз§ҚзҺ°иұЎпјҢдҪҶдё»иҰҒзҡ„е·®еҲ«еңЁдәҺпјҢз»ҹи®ЎжЁЎеһӢжңүиҖғиҷ‘дәҶйҡҸжңәиҜҜе·®пјҢ并且еҜ№йҡҸжңәиҜҜе·®жңүдёҖж•ҙеҘ—дёҘеҜҶзҡ„и§ЈйҮҠдҪ“зі»пјҢдҪҶе…¶д»–йўҶеҹҹзҡ„专家жүҖе»әз«Ӣзҡ„жЁЎеһӢжңӘеҝ…жңүиҖғиҷ‘еҲ°йҡҸжңәиҜҜе·®гҖӮжүҖд»Ҙдё»иҰҒзҡ„е·®еҲ«еңЁдәҺпјҡ
дёҖиҲ¬з§‘еӯҰжЁЎеһӢпјҡ Y = f(X1,X2,…,Xk)
з»ҹи®ЎжЁЎеһӢпјҡ Y = f(X1,X2,…,Xk) + йҡҸжңәиҜҜе·®
еҰӮжһңиҮӘ然з•ҢдёҺдәәзұ»зӨҫдјҡзҡ„з§Қз§ҚзҺ°иұЎжІЎжңүиҝҷдёӘйҡҸжңәиҜҜе·®зҡ„еӯҳеңЁпјҢж•ҙдёӘз»ҹи®ЎйўҶеҹҹеҸҜд»Ҙе®Ңе…Ёж¶ҲеӨұд№ҹж— жүҖи°“гҖӮдҪҶдәӢе®һеҪ“然дёҚжҳҜиҝҷж ·гҖӮ
жӯӨеӨ–пјҢиҝҮеәҰйҮҚи§ҶгҖҢйў„жөӢиғҪеҠӣгҖҚд№ҹдјҡжңүиҜҜеҜјзҡ„еҸҜиғҪжҖ§пјҡжүҖи°“зҡ„гҖҢйў„жөӢиғҪеҠӣеҘҪгҖҚпјҢеҲ°еә•еҸӘжҳҜзү№е®ҡж—¶й—ҙ(жҹҗеҮ дёӘжңҲпјҹ)гҖҒзү№е®ҡз©әй—ҙ(еҸӘйҷҗдәҺжҹҗдёӘеӣҪ家жҹҗдёӘең°еҢәдёӯзҡ„жҹҗдёӘе…¬еҸёпјҹ) пјҹиҝҳжҳҜиҝҷж ·зҡ„жЁЎеһӢеңЁдёҚеҗҢж—¶з©әзҠ¶еҶөдёӢиЎЁзҺ°е°ұеҫҲе·®пјҹ
жҺҘи§ҰиҝҮжңәеҷЁеӯҰд№ гҖҒж•°жҚ®жҺўеӢҳгҖҒзұ»зҘһз»ҸзҪ‘з»ң(Artificial Neural Network)зҡ„дәәеӨ§жҰӮйғҪзҹҘйҒ“пјҢеҰӮжһңжІЎжңүж•ҙдёӘжҜҚдҪ“(Population)зҡ„жЁЎеһӢеҒҮи®ҫеҠ дёҠйҡҸжңәиҜҜе·®жЁЎеһӢзҡ„жҗӯй…ҚпјҢеҫҲеӨҡеҸ·з§°гҖҢиЎЁзҺ°еҫҲеҘҪгҖҚзҡ„жЁЎеһӢпјҢе…¶е®һиҝҮдёҖйҳөеӯҗе°ұйғҪдјҡе®ҢиӣӢпјҢд№ҹеӣ жӯӨз»ҸеёёйңҖиҰҒжҢҒз»ӯдёҚж–ӯзҡ„еҫ®и°ғеҸӮж•°гҖӮеҸҜжҳҜпјҢиҜқиҜҙеӣһжқҘпјҢдёҖдёӘз»ҸеёёйңҖиҰҒдёҚж–ӯи°ғж•ҙзҡ„жЁЎеһӢпјҢиғҪеӨҹи®Өдёәе®ғиЎЁзҺ°еҫҲеҘҪеҗ—пјҹ
жҲ‘жңҖеҗҺеҒҡдёӘе°Ҹз»“и®әпјҡ
1. жңәеҷЁеӯҰд№ йўҶеҹҹеҫҖеҫҖжҳҜйҖҸиҝҮиҝҮеҺ»ж”¶йӣҶзҡ„(еӨ§йҮҸ)иө„ж–ҷжқҘеҪ“дҪңйў„жөӢзҡ„еҹәзЎҖгҖӮеҰӮжһңиҝҮеҺ»зҡ„ж•°жҚ®е№¶дёҚе®Ңж•ҙпјҢж— жі•еҢ…еҗ«жүҖжңүеҸҜиғҪзҡ„зҠ¶еҶөпјҢиҝҷж—¶еҖҷжңәеҷЁеӯҰд№ жүҖеҫ—зҡ„жЁЎеһӢе°ұз®—зҹӯж—¶й—ҙеҶ…йў„жөӢеҫҲзІҫеҮҶпјҢдҪҶеҫҲеҝ«е°ұдјҡе®ҢиӣӢгҖӮзӣёеҸҚзҡ„пјҢжңүиҖғиҷ‘жҜҚдҪ“йҡҸжңәзү№жҖ§зҡ„з»ҹи®ЎжЁЎеһӢпјҢеӣ дёәжЁЎеһӢжң¬иә«е°ұе·Із»ҸжҠҠеҗ„з§ҚеҸҜиғҪжҖ§йғҪеҢ…еҗ«еңЁеҶ…пјҢе°ұжҜ”иҫғдёҚдјҡеҸ—еҲ°иҝҮеҺ»еұҖйғЁж•°жҚ®зҡ„еӨӘеӨ§еҪұе“ҚгҖӮ
2. жңәеҷЁеӯҰд№ зӣёе…іжҠҖжңҜеҰӮжһңжңүйҮҮзәігҖҢйҡҸжңәиҜҜе·®гҖҚзҡ„и§ӮеҝөпјҢе…¶е®һе°ұеҸҜд»Ҙи§ҶдёәжҳҜз»ҹи®ЎжЁЎеһӢпјҢжүҖд»ҘдёӨиҖ…д№Ӣй—ҙзҡ„еҢәеҲҶ并дёҚжҳҜйӮЈд№Ҳзҡ„дёҘж јгҖӮеҸҚиҝҮжқҘиҜҙпјҢйҷӨйқһжҳҜеғҸ E = m(C е№іж–№) иҝҷз§ҚзәҜзү©зҗҶеӯҰжЁЎеһӢпјҢдёҚиҖғиҷ‘йҡҸжңәиҜҜе·®зҺ°иұЎзҡ„д»»дҪ•жЁЎеһӢпјҢеҹәжң¬дёҠйғҪжҳҜеұҖйғЁзҡ„гҖҒжҡӮж—¶зҡ„пјҢж— жі•й•ҝиҝңиЎЁзҺ°иүҜеҘҪгҖӮдәӢе®һдёҠпјҢеҫҲеӨҡеҫҲеҺүе®ізҡ„зү©зҗҶеӯҰ家们еңЁйҮҸеӯҗеҠӣеӯҰйҮҢйқўдҪҝз”ЁдәҶйқһеёёй«ҳйҳ¶зҡ„з»ҹи®ЎжЁЎеһӢеңЁеҲҶжһҗж•°жҚ®пјҢдҪҶиҝҷж ·зҡ„зқҝжҷәжңӘеҝ…иғҪеңЁжңәеҷЁеӯҰд№ йўҶеҹҹзңӢеҲ°гҖӮ
3. API зҡ„еӘ’дҪ“жҠ•иө„жЁЎжӢҹеҷЁжҳҜеҢ…еҗ«з»ҹи®ЎжЁЎеһӢдёҺиҜҜе·®зҡ„жңәеҷЁеӯҰд№ жҠҖжңҜгҖӮ
Steve Chen
дј°и®Ўд№ҹдёҚдјҡжңүд»Җд№ҲдәәзңӢпјҢеҸҚиҖҢеҸҜд»ҘйҡҸеҝғзҡ„иҜҙдёҖиҜҙгҖӮ
дёҚз®Ўе“ӘдёӘдё“дёҡзҡ„дәәпјҢйҮҮеҸ–зҡ„ж–№жі•йғҪжҳҜе’ҢиҝҷдёӘдё“дёҡжүҖйқўдёҙзҡ„е®һйҷ…й—®йўҳзӣёиҒ”зі»гҖӮ
дј з»ҹдёҠеҒҡз»ҹи®Ўзҡ„дәәйқўдёҙзҡ„ж•°жҚ®йғҪжҳҜжқҘиҮӘдәҺиҮӘ然科еӯҰйҮҢзҡ„ж•°жҚ®пјҢжҜ”еҰӮFisherйқўдёҙзҡ„еҶңдёҡж•°жҚ®пјҢжҲ–иҖ…з”ҹзү©дёҠзҡ„ж•°жҚ®пјҢжҲ–иҖ…зү©зҗҶдёҠзҡ„ж•°жҚ®гҖӮиҝҷдәӣж•°жҚ®йғҪжңүдёҖдёӘзү№зӮ№е°ұжҳҜеҸҜд»ҘеҫҲеҘҪзҡ„з¬ҰеҗҲдј з»ҹзҡ„з»ҹи®ЎеҲҶеёғпјҢеҰӮжӯЈжҖҒеҲҶеёғ жіҠжқҫеҲҶеёғзӯүгҖӮйқўдёҙиҝҷдёӘе®һйҷ…жғ…еҶөпјҢеҒҡз»ҹи®Ўзҡ„дәәжңүдёҖдёӘж №ж·ұи’Ӯеӣәзҡ„жҖқз»ҙпјҢе°ұжҳҜз»ҹи®ЎжҳҜжҰӮзҺҮзҡ„еҸҚй—®йўҳгҖӮи®Өдёәз»ҹи®Ўзҡ„зӣ®ж ҮжҳҜжүҫеҮәз”ҹжҲҗз»ҹи®Ўж•°жҚ®иғҢеҗҺзҡ„зңҹе®һжҰӮзҺҮгҖӮиҝҷжҳҜдј з»ҹдёҠеҒҡз»ҹи®Ўзҡ„дәәзҡ„жңҖж ёеҝғжҖқжғіпјҢжүҖд»ҘдёҚз®ЎзӮ№дј°и®Ўд№ҹеҘҪпјҢеҒҮи®ҫжЈҖйӘҢд№ҹеҘҪпјҢеӨ§ж ·жң¬ж–№жі•д№ҹеҘҪгҖӮжүҖжңүзҡ„ж–№жі•иғҢеҗҺжүҖйҡҗеҗ«зҡ„жҖқжғіе°ұжҳҜж•°жҚ®дёҖе®ҡжҳҜз”ұжҹҗдәӣжҰӮзҺҮеҲҶеёғз”ҹжҲҗзҡ„гҖӮ
еҒҡжңәеҷЁеӯҰд№ зҡ„дәәжңүдёҖйғЁеҲҶжқҘиҮӘдәҺеҪ“е№ҙйӣ„еҝғеӢғеӢғз ”з©¶дәәе·ҘжҷәиғҪиҖҢеҗҺжүҝи®ӨзҺ°зҠ¶иҪ¬иҖҢз ”з©¶дёҖдәӣе®һйҷ…й—®йўҳзҡ„дәәпјҢеҸҰдёҖйғЁеҲҶжҳҜдә’иҒ”зҪ‘е…ҙиө·д№ӢеҗҺе®һйҷ…дёӯеҜ№ж•°жҚ®йў„жөӢжңүејәзғҲйңҖжұӮзҡ„дәәгҖӮжүҖд»Ҙ他们йқўдёҙзҡ„ж•°жҚ®жқҘжәҗе®Ңе…ЁдёҚеҗҢдәҺдј з»ҹзҡ„еҒҡз»ҹи®Ўзҡ„дәәгҖӮжңҖе…ёеһӢзҡ„жңәеҷЁеӯҰд№ зҡ„еә”з”Ёе°ұжҳҜзӮ№еҮ»зҺҮйў„дј°гҖҒе•Ҷе“ҒжҺЁиҚҗгҖӮжҲ‘们еҫҲйҡҫзӣёдҝЎжҲ‘们зӮ№ејҖдёҖ家иҙӯзү©зҪ‘з«ҷд№ӢеҗҺпјҢжҲ‘们е°ұиҮӘеҠЁзҡ„еҜ№иҝҷдёӘзҪ‘з«ҷдёҠжүҖжңүзҡ„зү©е“ҒжҳҜеҗҰиҙӯд№°жңүдёҖдёӘжҰӮзҺҮеҲҶеёғгҖӮдҪҶжҳҜеҰӮжһңз”Ёдј з»ҹзҡ„з»ҹи®Ўж–№жі•жқҘеҒҡйў„жөӢпјҢиҝҷз§ҚеҒҮи®ҫе°ұжҳҜеӨ©з„¶зҡ„йҡҗеҗ«зҡ„гҖӮжүҖд»Ҙйқўдёҙиҝҷз§Қе®һйҷ…жғ…еҶөпјҢеҒҡжңәеҷЁеӯҰд№ зҡ„дәәеҝ…йЎ»жүҫеҲ°е…¶д»–зңӢеҫ…ж•°жҚ®ж–№жі•гҖӮжүҖд»Ҙ他们зҡ„и§ӮзӮ№жҳҜж•°жҚ®зҡ„еҮ дҪ•з»“жһ„жүҚжҳҜеңЁиҝҷз§Қжғ…еҶөдёӢзңӢеҫ…ж•°жҚ®зҡ„жӯЈзЎ®ж–№жі•гҖӮйӮЈд№ҲиҮӘ然иҖҢ然зҡ„еҲҶзұ»е’ҢиҒҡзұ»зҡ„жүӢж®өе°ұжҲҗдәҶжңәеҷЁеӯҰд№ зҡ„дәәжңҖеҫ—еҝғеә”жүӢзҡ„дёӨз§ҚжүӢж®өгҖӮ
дёҫдёӘдҫӢеӯҗеҸҜд»ҘжҜ”иҫғеҘҪзҡ„иҜҙжҳҺпјҢе°ұжҳҜPCAдё»жҲҗеҲҶеҲҶжһҗгҖӮиҝҷдёӘж–№жі•дј з»ҹз»ҹи®ЎдёҠе°ұжңүпјҢжңәеҷЁеӯҰд№ дёҠд№ҹжңүгҖӮз»Ҹе…ёиҖҢз®ҖеҚ•гҖӮеҒҡз»ҹи®Ўзҡ„дәәпјҢ第дёҖж¬ЎзңӢеҲ°PCAйғҪжҳҜеңЁеӨҡе…ғз»ҹи®ЎеҲҶжһҗйҮҢпјҢйӮЈж—¶еҖҷеҜ№PCAзҡ„и§ЈйҮҠжҳҜ第дёҖдё»жҲҗеҲҶжҳҜйҡҸжңәеҸҳйҮҸзҡ„зәҝжҖ§з»„еҗҲпјҢиҝҷдёӘзәҝжҖ§з»„еҗҲзҡ„ж–№е·®жҳҜжүҖжңүзәҝжҖ§з»„еҗҲйҮҢж–№е·®жңҖеӨ§зҡ„гҖӮиҜ·жіЁж„ҸпјҢжӯӨж—¶зңӢеҫ…ж•°жҚ®зҡ„ж–№ејҸжҳҜжҰӮзҺҮзҡ„гҖӮеҒҡжңәеҷЁеӯҰд№ зҡ„дәәпјҢ他们зңӢеҫ…PCAжҳҜпјҢжҠҠж ·жң¬ж•°жҚ®е…ҲеҺ»жҺүеқҮеҖјгҖӮ然еҗҺжүҫKз»ҙеӯҗз©әй—ҙйҖјиҝ‘ж ·жң¬ж•°жҚ®пјҢйҖјиҝ‘жңҖеҘҪзҡ„Kз»ҙеӯҗз©әй—ҙзҡ„еҹәе°ұжҳҜжҲ‘们иҰҒжүҫзҡ„дё»жҲҗеҲҶгҖӮиҜ·жіЁж„ҸпјҢжӯӨж—¶зҡ„и§ӮзӮ№е®Ңе…ЁжҳҜеҮ дҪ•зҡ„гҖӮеҪ“然еңЁзӣ®еүҚеҗ„дёӘеӯҰ科дәӨеҸүиһҚеҗҲзҡ„жғ…еҶөдёӢпјҢеҸҢж–№йғҪдјҡйҮҮеҸ–дёҚеҗҢзҡ„и§ӮзӮ№пјҢдёҠиҝ°иҜҙ法并дёҚжҳҜиҜҙеҒҡз»ҹи®ЎжҲ–иҖ…еҒҡжңәеҷЁеӯҰд№ зҡ„дәәйғҪжҳҜйҮҮз”ЁдёҖжҲҗдёҚеҸҳзҡ„и§ӮзӮ№пјҢиҝҷзӮ№жҳҺзңјдәәеҝғйҮҢжңүж•°е°ұиЎҢпјҢдёҚеҝ…зә зј гҖӮеҜ№ж ·жң¬ж•°жҚ®еҒҡдё»жҲҗеҲҶеҲҶжһҗеҫ—еҮәжқҘжҜҸдёӘдё»жҲҗеҲҶзҡ„зү№еҫҒеҖјгҖӮдј—жүҖе‘ЁзҹҘпјҢз»қеӨ§йғЁеҲҶзү№еҫҒеҖјйғҪжҳҜеҫҲжҺҘиҝ‘дәҺ0зҡ„гҖӮиҝҷж—¶еҖҷеҸҢж–№жҖқз»ҙзҡ„дёҖдёӘдё»иҰҒеҢәеҲ«е°ұдҪ“зҺ°зҡ„жҜ”иҫғжҳҺжҳҫпјҢеҒҡжңәеҷЁеӯҰд№ зҡ„дәәд»ҺеҮ дҪ•зҡ„и§ӮзӮ№пјҢеҸҜд»ҘиҮӘ然зҡ„и®ӨдёәпјҢз”ұдәҺзү№еҫҒеҖјеӨӘе°Ҹиҝҷдәӣз»ҙеәҰзңӢжҲҗеҷӘеЈ°жҳҜеҫҲжӯЈеёёзҡ„еҸҜд»ҘеҺ»жҺүпјҢиҖҢдёҚеҪұе“Қж ·жң¬зҡ„жүҖеҢ…еҗ«зҡ„дҝЎжҒҜгҖӮдҪҶжҳҜеҒҡз»ҹи®Ўзҡ„дәәеӨ©з„¶и®Өдёәж ·жң¬жҳҜжҹҗдёӘеҲҶеёғз”ҹжҲҗзҡ„пјҢжүҖд»Ҙз”ұж ·жң¬жүҖз”ҹжҲҗзҡ„зү№еҫҒеҖјиҮӘ然жҳҜжңҚд»ҺжҹҗдёҖдёӘеҲҶеёғзҡ„пјҢйӮЈд№Ҳзү№еҫҒеҖјжҳҜдёҚжҳҜ0е°ұиҰҒиҝӣиЎҢзҡ„еҸӮж•°дј°и®Ўе’ҢеҒҮи®ҫжЈҖйӘҢгҖӮиҝҷдёӘеҜ№еҒҡжңәеҷЁеӯҰд№ зҡ„дәәжқҘиҜҙз»қеҜ№жҳҜ然иҖҢ并没жңүд»Җд№ҲеҚөз”Ёзҡ„жӯҘйӘӨгҖӮдҪҶеҜ№еҒҡз»ҹи®Ўзҡ„дәәжқҘиҜҙиҝҷжҳҜ他们жҖқз»ҙзҡ„иҮӘ然延伸гҖӮ
жүҖд»ҘеҸҢж–№жңҖдё»иҰҒзҡ„еҢәеҲ«е°ұжҳҜзңӢеҫ…ж•°жҚ®з”ҹжҲҗж–№ејҸгҖӮз»ҹи®Ўзҡ„дәәи®ӨдёәпјҢж•°жҚ®з”ұжҹҗдёӘжҰӮзҺҮеҲҶеёғз”ҹжҲҗгҖӮжңәеҷЁеӯҰд№ зҡ„дәәи®Өдёәж•°жҚ®жҳҜзү№еҫҒйӣҶеҲ°LabelйӣҶзҡ„зү№еҫҒжҳ е°„жүҖз”ҹжҲҗзҡ„гҖӮз»ҹи®Ўзҡ„зӣ®ж ҮжҳҜжҒўеӨҚйӮЈдёӘиғҢеҗҺзҡ„жҰӮзҺҮпјҢжңәеҷЁеӯҰд№ зҡ„зӣ®ж ҮжҳҜжҒўеӨҚзү№еҫҒжҳ е°„гҖӮ
жңҖеҗҺжҲ‘жғіиҜҙзҡ„жҳҜпјҢдёҠиҝ°еҜ№з»ҹи®Ўе’ҢжңәеҷЁеӯҰд№ зҡ„еҢәеҲ«еҒҡдәҶеҢәеҲ«гҖӮдҪҶдёҚд»ЈиЎЁеҒҡз»ҹи®Ўе’ҢеҒҡжңәеҷЁеӯҰд№ зҡ„дәәйғҪжҳҜжӯ»жқҝдәәпјҢйғҪд»ҘдёҖжҲҗдёҚеҸҳзҡ„ж–№ејҸзңӢеҫ…й—®йўҳгҖӮж—¶д»ЈеңЁиҝӣжӯҘгҖӮдёҚз®ЎеҒҡд»Җд№Ҳзҡ„дәәйғҪжҳҜдјҡйқўдёҙе®һйҷ…й—®йўҳпјҢйҮҮз”ЁеӨҡж–№и§ӮзӮ№гҖӮжңҖз»Ҳзҡ„зӣ®зҡ„жҳҜжҠҠй—®йўҳи§ЈеҶіжҺүиҖҢдёҚжҳҜеҒҡдёҖдәӣж— и°“зҡ„дәүи®әгҖӮ
иҝҷж ·зҡ„и§ӮзӮ№еҢ…жӢ¬дҪҶдёҚйҷҗдәҺд»ҘдёӢеҮ зӮ№пјҡ
дёҡз•ҢеӯҰз•Ңд№Ӣдәү
дёҘи°ЁжҖ§д№Ӣдәү
е°ұеҘҪеғҸи®©йӮЈдәӣе…іжіЁзҗҶи®әдёҘи°ЁжҖ§зҡ„Statistical Scientistе’Ңе…іжіЁе®һж•Ҳз»“жһңзҡ„Machine Learning Engineerж’•йҖјпјҢScienceе’ҢEngineeringжүҚжҳҜ他们зҡ„дё»иҰҒзҹӣзӣҫпјҢиҮӘ然дјҡеҫ—еҮәеҫҲеӨҡдёҚеңЁз»ҹи®Ўе’ҢжңәеҷЁеӯҰд№ дёӨдёӘеӯҰ科еҢәеҲ«иҢғз•ҙд№ӢеҶ…зҡ„и§ӮзӮ№гҖӮ
дәӢе®һдёҠжңәеҷЁеӯҰд№ дҪңдёәдёҖ门科еӯҰпјҢдҪңдёәи®Ўз®—жңә科еӯҰзҡ„еӯҗеӯҰ科зҡ„ж—¶еҖҷпјҢдёҖж ·жңүе…¶зҗҶи®әдёҘи°ЁжҖ§гҖӮд»ҘBoostingдёәдҫӢпјҢеңЁи®әиҜҒпјҡ
Can a set of weak learnerscreate a single strong learner?
иҝҷдёӘй—®йўҳдёҠйқўпјҢMITзҡ„Robert Schapire 1990е№ҙеңЁMachine LearningеҸ‘иЎЁзҡ„ж–Үз« The strength of weak learnability еҜ№иҝҷдёӘй—®йўҳиҝӣиЎҢдәҶйқһеёёдёҘи°Ёзҡ„и®Ёи®әгҖӮ
жүҖд»Ҙ:
1. дёҡз•ҢдёҺеӯҰз•ҢпјҢзҗҶи®әдёҘи°Ёе’Ңе…іжіЁе®һж•ҲйғҪжҳҜ科еӯҰдёҺе·ҘзЁӢд№Ӣй—ҙеҢәеҲ«зҡ„иЎЁзҺ°пјҢиҖҢдёҚжҳҜз»ҹи®ЎдёҺжңәеҷЁеӯҰд№ еҢәеҲ«зҡ„иЎЁзҺ°гҖӮ
2. иҖҢз»ҹи®ЎеӯҰе’ҢжңәеҷЁеӯҰд№ йғҪжңүе…¶дҪңдёәдёҖ门科еӯҰзҡ„дёҖйқўпјҢд№ҹжңүеңЁеә”з”Ёдёӯе·ҘзЁӢзҡ„дёҖйқўгҖӮ
3. еҗҲзҗҶзҡ„жҜ”иҫғдјјд№Һеә”иҜҘжҳҜзӣҙжҺҘжҜ”иҫғпјҡз»ҹи®ЎпјҲ科еӯҰпјүе’ҢжңәеҷЁеӯҰд№ пјҲ科еӯҰпјүжҲ–иҖ…жҜ”иҫғпјҡз»ҹи®ЎпјҲе·ҘзЁӢеә”з”Ёпјүе’ҢжңәеҷЁеӯҰд№ пјҲе·ҘзЁӢеә”з”ЁпјүгҖӮ
4. еҪ“然жңәеҷЁеӯҰд№ з•Ңж•ҙдҪ“еҒҸе·ҘзЁӢпјҢз»ҹи®Ўз•Ңж•ҙдҪ“еҒҸ科еӯҰжң¬иә«д№ҹеҸҜд»ҘжҳҜдёӨиҖ…зҡ„дёҖдёӘйҮҚиҰҒеҢәеҲ«гҖӮеҗҢж ·жҲ‘们еҸҜд»ҘиҖғиҷ‘дёҖдёӘжңүж„ҸжҖқзҡ„й—®йўҳ: дёәд»Җд№Ҳдјҡжңүз»ҹи®ЎеҒҸеӯҰз•ҢпјҢжңәеҷЁеӯҰд№ еҒҸдёҡз•ҢпјҢз»ҹи®ЎжіЁйҮҚзҗҶи®әдёҘи°ЁпјҢжңәеҷЁеӯҰд№ е…іжіЁе®һж•Ҳзҡ„жҳ еғҸе‘ўпјҹ
з»ҹи®ЎеӯҰжғіе№Іеҳӣпјҹ
вҖңд»ҘдёӢзҡ„и®әиҝ°еҸҜиғҪжҜ”иҫғеҚЎйҖҡеҢ–пјҢжҳҜеҜ№й—®йўҳзҡ„дёҖдёӘз®ҖеҢ–пјҢдҪҶжҳҜд»Һжҹҗз§Қж„Ҹд№үдёҠжқҘиҜҙпјҢз»ҹи®ЎеӯҰжӣҙеғҸжҳҜйқўеҗ‘科еӯҰжңҚеҠЎзҡ„дёҖй—Ёе·Ҙе…·гҖӮз»ҹи®ЎжЈҖйӘҢе’ҢеҒҮи®ҫжЈҖйӘҢпјҢжҳҜеҪ“科еӯҰ家们жғіиҰҒзҗҶи§ЈиҝҷдёӘдё–з•Ңзҡ„дёҖдәӣжҖ§иҙЁпјҢжҲ–иҖ…жғіиҰҒеӣһзӯ”е…ідәҺжҹҗдёӘиҝӣзЁӢзҡ„дёҖдәӣе…ій”®еӣ зҙ ж—¶зҡ„йҰ–йҖүеҲ©еҷЁгҖӮжҜ”еҰӮиҜҙпјҢжҹҗз§ҚиҚҜзү©еҲ°еә•еҜ№жІ»з—…жңүжІЎжңүж•Ҳжһңпјҹз»ҹи®ЎеӯҰ家дёәиҝҷдёҖзұ»зҡ„й—®йўҳжҸҗдҫӣдәҶйқһеёёе®ҢзҫҺзҡ„е·Ҙе…·пјҢжңүдәҶиҝҷдәӣе·Ҙе…·пјҢ科еӯҰ家们еҫ—д»ҘеҺ»жөӢйҮҸе’Ңдј°и®ЎжҹҗдәӣеҸҜд»ҘзҗҶи§Јзҡ„еҸҳйҮҸзҡ„ж•Ҳжһңе’ҢдҪңз”ЁгҖӮжүҖи°“еҸҜд»ҘзҗҶи§Јзҡ„еҸҳйҮҸпјҢиҜҙзҡ„жҳҜпјҢ科еӯҰ家еңЁе»әжЁЎж—¶жүҖж¶үеҸҠеҲ°зҡ„еҸҳйҮҸйҖҡеёёйғҪжңүжӯЈеёёдәәзұ»иғҪеӨҹзҗҶи§Јзҡ„йҮҸзәІпјҲжҜ”еҰӮзү©зҗҶеӯҰжЁЎеһӢдёӯзҡ„иҙЁйҮҸпјҢйҖҹеәҰпјүпјҢ并且иғҪдёҺдҪ иҰҒи§ӮеҜҹзҡ„жҹҗз§ҚзҺ°иұЎжҲ–иҖ…ж•Ҳеә”зӣҙжҺҘжҢӮй’©пјҲжҜ”еҰӮз ”з©¶жҹҗз§Қеҹәеӣ дҝ®йҘ°еҜ№иЎЁи§ӮеһӢзҡ„еҪұе“ҚжңүеӨҡеӨ§ж—¶пјҢиҜҘз§Қеҹәеӣ еҗ«йҮҸпјҢжүҖиЎЁиҫҫзҡ„иӣӢзҷҪиҙЁзҡ„еҗ«йҮҸпјүгҖӮд№ҹе°ұжҳҜиҜҙпјҢз»ҹи®ЎеӯҰжЁЎеһӢйҮҢж¶үеҸҠеҲ°зҡ„еҸӮж•°йғҪжҳҜжңүе®һйҷ…ж„Ҹд№үзҡ„пјҢеӣ жӯӨеҪ“жҹҗдёӘеҒҮи®ҫйҖҡиҝҮдәҶжЈҖйӘҢж—¶пјҢжҲ‘们е°ұзҹҘйҒ“дёҖдәӣзҺ°е®һдёӯзҡ„еҸҳйҮҸжҳҜеҰӮдҪ•зӣёдә’дҪңз”Ёзҡ„гҖӮ
д»ҺиҝҷдёӘи§’еәҰжқҘиҜҙпјҢз»ҹи®ЎеӯҰйҖҡеёёжҠҠиҮӘе·ұзңӢеҒҡжҳҜйҮҸеҢ–еҲҶжһҗзҡ„е®Ҳй—ЁдәәпјҢе®ғзҡ„зӣ®ж ҮжҳҜйҖҡиҝҮдёҘж јзҡ„жөӢйҮҸдј°и®ЎпјҢеҒҮи®ҫжЈҖйӘҢпјҢжҢ‘йҖүеҮәеҖјеҫ—дҝЎд»»зҡ„еҒҮи®ҫпјҢд»ҘжӯӨжқҘзҗҶи§Јеҗ„з§Қз”ҹзү©дҪ“дёӯзҡ„еӣ жһңе…іиҒ”пјҢжҲ–иҖ…жҳҜзӨҫдјҡеӯҰдёӯзҡ„жҹҗз§ҚиҝӣзЁӢжҲ–иҖ…жҳҜж•Ҳеә”гҖӮеҪ“然пјҢз»ҹи®ЎеӯҰйҮҢиҝҳеҢ…жӢ¬дәҶеҫҲеӨҡе…¶д»–зҡ„йҮҚиҰҒжғіжі•е’ҢжҰӮеҝөпјҢжҜ”еҰӮпјҢе®ғеҜ№еҝғзҗҶеӯҰгҖҒеҢ»еӯҰгҖҒзӨҫдјҡеӯҰдёӯзҡ„еҗ„з§Қе®һйӘҢи®ҫи®ЎжҸҗеҮәдәҶ规иҢғе’Ңе»әи®ҫжҖ§жЎҶжһ¶гҖӮвҖқ
з®ҖиҖҢиЁҖд№ӢпјҢз»ҹи®ЎеӯҰжӣҙеӨҡжҳҜе…ідәҺдё–з•Ңжң¬иҙЁзҡ„дёҖдёӘдёӘжЈҖйӘҢпјҢе®ғзҡ„зӣ®ж ҮжҳҜе»әз«ӢдёҖдёӘеҸҜд»ҘзҗҶи§Јзҡ„дё–з•Ңзҡ„жЁЎеһӢгҖӮ
** жңәеҷЁеӯҰд№ зӣ®ж ҮдёәдҪ•пјҹ
вҖңдёҚеҗҢдәҺз»ҹи®ЎеӯҰпјҢжңәеҷЁеӯҰд№ жӣҙе…іеҝғзҡ„дёҚжҳҜжЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§пјҢиҖҢжҳҜжЁЎеһӢзҡ„йў„жөӢиғҪеҠӣгҖӮжңәеҷЁеӯҰд№ зҡ„зӣ®ж ҮжҳҜжҗӯе»әдёҖеҘ—й«ҳж•ҲеҸҜйқ зҡ„зі»з»ҹпјҢиғҪеӨҹжҢҒз»ӯзҡ„йў„жөӢжңӘжқҘ并且稳е®ҡзҡ„е·ҘдҪңгҖӮжҜ”еҰӮпјҢжңәеҷЁи§Ҷи§үзі»з»ҹйңҖиҰҒеҒҡзҡ„жҳҜжӯЈзЎ®йў„жөӢдёҖеј еӣҫзүҮйҮҢзҡ„е°ҸеҠЁзү©еҲ°еә•жҳҜзҢ«иҝҳжҳҜзӢ—пјҢдёӨеј дәәи„ёзҡ„з…§зүҮйҮҢжҳҜдёҚжҳҜеҗҢдёҖдёӘдәәпјҢдёҖдёӘе®ӨеҶ…жңәеҷЁдәәжҳҜдёҚжҳҜиғҪеӨҹжӯЈзЎ®зҡ„иҜҶеҲ«еҮәе®ғе‘Ёеӣҙзҡ„зҺҜеўғпјҢзӯүзӯүгҖӮдҪҶиҝҷдәӣзі»з»ҹеҶ…йғЁзҡ„еҸӮж•°йҖҡеёёжҳҜж•°йҮҸе·ЁеӨ§е№¶дё”ж— жі•иў«дәә们зӣҙжҺҘзҗҶи§Јзҡ„пјҢжӣҙдёҚз”ЁиҜҙжңүе’ҢзҺ°е®һз”ҹжҙ»дёӯзҡ„жҹҗдәӣзү№жҖ§еҜ№еә”зҡ„йҮҸзәІдәҶгҖӮдҪҶеҚідҪҝжҗһдёҚжё…иҝҷдәӣеҸӮж•°еҲ°еә•д»ЈиЎЁдәҶд»Җд№ҲпјҢеҸӘиҰҒдҪ зҡ„жЁЎеһӢworkпјҢжҖ»иғҪз»ҷеҮәжһҒдёәеҮҶзЎ®зҡ„йў„жөӢе°ұжҳҜзҺӢйҒ“гҖӮ
жңүж—¶еҖҷпјҢжҹҗдёҖзұ»жңәеҷЁеӯҰд№ й—®йўҳзҡ„жӯЈзЎ®зҺҮзӘҒ然жңүдәҶеӨ§е№…еәҰзҡ„жҸҗеҚҮпјҢеҸҜиғҪеҫ—зӣҠдәҺдәә们弄清дәҶиҜҘдјҳеҢ–й—®йўҳиғҢеҗҺзҡ„зҗҶи®әйҡҫзӮ№пјҢдҪҶжӣҙеӨҡзҡ„ж—¶еҖҷпјҢжҹҗз§Қз®—жі•жҳҜеҗҰжҲҗеҠҹе®Ңе…Ёз”ұйў„жөӢз»“жһңиҜҙдәҶз®—пјҢеҚідҪҝдәә们еҜ№е…¶дёӯзҡ„еҺҹзҗҶдҫқ然жүҖзҹҘз”ҡе°‘гҖӮвҖқ
ж·ұеәҰеӯҰд№ пјҲdeep learningпјүд№ӢжүҖд»ҘеңЁ2000е№ҙиҮі2010е№ҙзҡ„еҚҒе№ҙй—ҙжҜ”иҫғжІүеҜӮпјҢеҺҹеӣ дёҚеӨ–д№ҺжҳҜдәәд»¬ж— жі•зҗҶи§Је®ғзҡ„еӯҰд№ иҝҮзЁӢдёӯеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲпјҢе®ғдёҖеұӮдёҖеұӮеӯҰеҮәжқҘзҡ„feature究з«ҹжҳҜд»Җд№ҲпјҢиҖҢе®ғзҡ„иЎЁзҺ°еҸҲ并йқһдёҖжһқзӢ¬з§ҖпјҢеӣ жӯӨе®ғеңЁдёҖжү№жӣҙе®№жҳ“иў«дәә们зҗҶи§Јзҡ„жЁЎеһӢд№Ӣй—ҙе°ұжҳҫеҫ—дёҚйӮЈд№Ҳиө·зңјдәҶгҖӮдҪҶеҪ“Geff еңЁ 2012 image net contestжҜ”иөӣдёҠд»Ҙdeep convolutional neural networkжҠҠеҜ№жүӢз”©ејҖеҚҒжқЎиЎ—еҗҺпјҢdeep netдҫҝзһ¬й—ҙд»ӨжүҖжңүдәәжҠҳжңҚдәҶ гҖӮеј•з”ЁGeffзҡ„еҺҹиҜқпјҢ"еҪ’ж №еҲ°еә•пјҢжҲ‘们иҝҳжҳҜеҫ—жӢҝж•°жҚ®иҜҙиҜқпјҢеҪ“дҪ зҡ„ж–№жі•иғҪе°Ҷй”ҷиҜҜзҺҮйҷҚдҪҺдёҖеҚҠж—¶пјҢдәә们еҝ…йЎ»еҫ—еҜ№дҪ еҲ®зӣ®зӣёзңӢгҖӮ"пјҲdata always wins, when you can half the error rate, people will take you seriously.пјү
*и°ҒдҝғиҝӣдәҶи°Ғпјҹ
д»Һжҹҗз§ҚзЁӢеәҰдёҠиҜҙпјҢз»ҹи®ЎеӯҰд№ зҗҶи®әйҮҢзҡ„еҫҲеӨҡжғіжі•зҡ„зЎ®з»ҷдәҶжңәеҷЁеӯҰд№ дёҖдәӣеҗҜеҸ‘пјҢдҪҶжҳҜпјҢиҝҷеҮ е№ҙжқҘжңәеҷЁеӯҰд№ еҸ‘еұ•зҡ„еҰӮжӯӨд№Ӣеҝ«пјҢеҰӮжӯӨзҒ«зҲҶзҡ„ж №жң¬еҺҹеӣ жӣҙеӨҡзҡ„жҳҜжқҘжәҗдәҺеҸҜи®ӯз»ғж•°жҚ®йҮҸзҡ„еӨ§е№…еәҰжҸҗеҚҮпјҲдә’иҒ”зҪ‘зҡ„жҷ®еҸҠпјҢhuman computationе№іеҸ°зҡ„жҲҗзҶҹпјҢеҗ„зұ»зәҝдёӢж•°жҚ®зҡ„з”өеӯҗеҢ–зӯүзӯүпјүд»ҘеҸҠз”өи„‘иҝҗз®—жҖ§иғҪзҡ„зӘҒйЈһзҢӣиҝӣпјҲpsпјҢжҳҫеҚЎи®Ўз®—зҡ„йЈһйҖҹеҸ‘еұ•е·Із»ҸеҲ°дәҶдё§еҝғз—…зӢӮзҡ„ең°жӯҘдәҶпјҢNVIDIAеҜ№з ”究жңәжһ„зҡ„иө„еҠ©з®ҖзӣҙжҳҜдёҚйҒ—дҪҷеҠӣпјҢдёҚжғңиЎҖжң¬зҡ„жӢје‘ҪеҫҖеӨ–йҖҒжҳҫеҚЎпјҢзңҹжҳҜи¶…зә§еӨ§жүӢ笔гҖӮгҖӮгҖӮпјүпјҢиҖҢ并дёҚдёҖе®ҡжҳҜз»ҹи®ЎзҗҶи®әжң¬иә«зҡ„ж №жң¬жҖ§зӘҒз ҙгҖӮ
вҖңдҪңдёәдёҖдёӘеҝ«йҖҹеҸ‘еұ•зҡ„иЎҢдёҡпјҢжҜ«ж— з–‘й—®пјҢжңәеҷЁеӯҰд№ еҗёеј•дәҶз»ҹи®ЎеӯҰ家зҡ„зӣ®е…үпјҢи¶ҠжқҘи¶ҠеӨҡзҡ„з»ҹи®ЎеӯҰз•Ңзҡ„дёҖжөҒдәәжүҚйғҪејҖе§Ӣд»ҺжңәеҷЁеӯҰд№ йўҶеҹҹеҗёж”¶ж–°йІңзҡ„жғіжі•пјҢж— и®әжҳҜз®—жі•еұӮйқўпјҢжЁЎеһӢеұӮйқўиҝҳжҳҜз»ҹи®ЎжҺЁж–ӯеұӮйқўгҖӮеҸҜд»ҘиҜҙпјҢжңәеҷЁеӯҰд№ жҳҜе°Ҷз»ҹи®ЎеӯҰд№ дёӯеҫҲж—©е°ұжҸҗеҮәжқҘзҡ„дёҖдәӣжғіжі•иҝӣиЎҢдәҶйҮҚж–°жҢ–жҺҳе’ҢйҮҚж–°е®ҡд№үгҖӮе°Ҫз®ЎжңәеҷЁеӯҰд№ зҡ„жҲҗеҠҹж¶үеҸҠеҲ°дәҶдёҖзі»еҲ—зҡ„з»ҹи®ЎеӯҰд№ ж–№жі•пјҢдҪҶиҝҷ并дёҚж„Ҹе‘ізқҖз»ҹи®ЎеӯҰжң¬иә«жҳҜиҝҷз§ҚжҲҗеҠҹзҡ„ж №жң¬еҺҹеӣ е’ҢжңҖеӨ§жҺЁеҠЁеҠӣгҖӮвҖқ
**гҖҖжұӮеҗҢеӯҳејӮ
е°Ҫз®Ўз»ҹи®ЎеӯҰе’ҢжңәеҷЁеӯҰд№ зҡ„зқҖзңјзӣ®ж ҮдёҚеҗҢпјҢдҪҶеңЁжҹҗдәӣжғ…еҶөдёӢпјҢдёӨиҖ…е…ұеҗҢе…іжіЁзҡ„дёҖдёӘй—®йўҳжҳҜпјҢдёҖдёӘжЁЎеһӢ究з«ҹдёәд»Җд№ҲworkгҖӮиҷҪ然д№ӢеүҚиҜҙеҲ°дәҶе®һжҲҳз»“жһңжҳҜжЈҖйӘҢжЁЎеһӢжңүж•ҲеһӢзҡ„з»ҲжһҒж ҮеҮҶпјҢдҪҶеӨ§е®¶жҖ»еҪ’жҳҜеёҢжңӣжңҖз»ҲиғҪеӨҹзҗҶи§ЈеңЁдёҖжӯҘдёҖжӯҘдјҳеҢ–зҡ„иҝҮзЁӢдёӯеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲпјҢжҳҜд»Җд№ҲtrickпјҢж»Ўи¶ідәҶд»Җд№ҲжқЎд»¶пјҢдҪҝеҫ—prediction errorиғҪеӨҹеҝ«йҖҹconvergeгҖӮжңүдәәиҜҙпјҢdevils are in the detailsжҜ”еҰӮпјҢеҚідҪҝеңЁж·ұеәҰеӯҰд№ жЁӘжү«дәҶе…ЁйўҶеҹҹзҡ„д»ҠеӨ©пјҢдәә们еҜ№neural networkеҶ…йғЁзҡ„trickдҫқ然жҳҜдёҖзҹҘеҚҠи§ЈпјҢеҰӮдҪ•ж”№иҝӣзҺ°жңүзҪ‘з»ңзҡ„з»“жһ„е’Ңжӣҙж–°иҝӯд»Јзҡ„规еҲҷдҪҝеҫ—е®ғиғҪеӨҹжӣҙеҝ«зҡ„convergeпјҢжӣҙеҮҶзЎ®зҡ„generalizeпјҹжңәеҷЁеӯҰд№ з•Ңзҡ„з ”з©¶иҖ…们еңЁдёҖжӯҘжӯҘжҺўз©¶е…¶еҶ…йғЁжңәзҗҶзҡ„иҝҮзЁӢдёӯд№ҹйҖҗжёҗзҡ„е°ҶжЁЎеһӢзҡ„еҮҶзЎ®зҺҮжҸҗдёҠж–°й«ҳгҖӮ
еҪ“然пјҢдҪңдёәжӣҙеҒҸеҗ‘дәҺеә”з”ЁдәҺе®һйҷ…зҡ„жңәеҷЁеӯҰд№ з•ҢпјҢйҷӨдәҶеҸ—еҲ¶дәҺзҗҶи®әдёҠзҡ„upper boundпјҢlower boundд№ӢеӨ–пјҢеңЁе®һйҷ…й—®йўҳдёӯпјҢиҝҳдјҡзў°еҲ°еҫҲеӨҡеҜ№иҝҗз®—ж—¶й—ҙе’ҢеӯҳеӮЁе®№йҮҸдёҠзҡ„йҷҗеҲ¶пјҢиҖҢиҝҷдәӣеҫҖеҫҖжҳҜеҒҡз»ҹи®ЎзҗҶи®әзҡ„дәәдёҚеӨӘе…іеҝғзҡ„й—®йўҳгҖӮ
еңЁеӣһзӯ”зҡ„жңҖеҗҺпјҢRyanиҜҙйҒ“пјҡ
еҒҡдёәеңЁиҝҷдёӨдёӘйўҶеҹҹйҮҢйғҪжңүжүҖжҙ»еҠЁзҡ„з ”з©¶дәәе‘ҳпјҢжңүж—¶иҮӘе·ұд№ҹдјҡиҝ·иҢ«жҲ‘еҲ°еә•еұһдәҺе“Әиҫ№пјҹйҖҡеёёжқҘиҜҙпјҢжңәеҷЁеӯҰд№ з•Ңзҡ„专家пјҢжҳҜдёҚдјҡзјәеёӯз»ҹи®ЎеӯҰзҡ„йЎ¶дјҡзҡ„гҖӮдҪҶеҶ…еҝғж·ұеӨ„пјҢжҲ‘иҝҳжҳҜдјҡи§үеҫ—жңәеҷЁеӯҰд№ жүҚжҳҜжҲ‘зңҹжӯЈзҡ„家пјҡпјү
жңәеҷЁеӯҰд№ зңҹжҳҜдёҖдёӘйқһеёёжңүи¶Јзҡ„йўҶеҹҹпјҢе®ғзҡ„жңүи¶ЈжҖ§дёҚд»…еңЁдәҺдҪ иғҪеӨҹйҖҡиҝҮе®ғеҸ‘зҺ°зҺ°е®һдёӯdataзҡ„еҫҲеӨҡжңүж„ҸжҖқзҡ„patternпјҢиҝҳеңЁдәҺйӮЈдәӣеј•йўҶзқҖдҪ еҸ‘зҺ°жңү趣规еҫӢзҡ„з®—жі•дёӯжң¬иә«и•ҙи—ҸзқҖзҡ„жҷәж…§гҖӮиҝҷзҜҮзӯ”жЎҲеҸӘжҳҜеҚғдёҮз§Қи§’еәҰдёӯзҡ„дёҖз§ҚпјҢ жІЎжңүи§ҰеҸҠеҲ°дёӨиҖ…жңҖжң¬иҙЁзҡ„еҲҶжӯ§пјҢд»…дҪңжҠӣз –еј•зҺүеҸӘз”ЁгҖӮ
еҰӮжһңдҪ зҡ„markovжЁЎеһӢиҫ“е…ҘйғҪжҳҜеҺҶеҸІиӮЎд»·пјҢйӮЈеҰӮжһң第дәҢеӨ©ж”ҝеәңйўҒеёғдәҶж–°жі•жЎҲзҰҒжӯўXиЎҢдёҡеҸ‘еұ•пјҢдҪ еңЁXиЎҢдёҡеҺҶеҸІеҲ©еҘҪеҹәзЎҖдёҠеҒҡеҮәзҡ„еҲӨж–ӯе°ұзҷҪзһҺдәҶпјӣ
еҰӮжһңдҪ зҡ„иҫ“е…ҘжҳҜеҺҶеҸІиӮЎд»·е’Ңж”ҝзӯ–и¶ӢеҠҝпјҢйӮЈз¬¬дәҢеӨ©йӮ»еӣҪеҮәдәҶдёӘXиЎҢдёҡBе…¬еҸёдә§е“Ғеј„жӯ»дәәзҡ„ж–°й—»пјҢдҪ еңЁXиЎҢдёҡAе…¬еҸёжң¬еӣҪиӮЎзҘЁзҡ„жҠ•иө„еҸҲзҷҪзһҺдәҶпјӣ
еҰӮжһңдҪ зҡ„иҫ“е…ҘжҳҜеҺҶеҸІиӮЎд»·гҖҒж”ҝзӯ–и¶ӢеҠҝе’ҢеӣҪйҷ…ж–°й—»пјҲиҝҷжҳҜеҫҲеӨҡеҜ№еҶІеҹәйҮ‘е…¬еҸёеҒҡзҡ„дәӢжғ…пјүпјҢйӮЈз¬¬дәҢеӨ©жҹҗдёӘеӨ§ж–°й—»зҪ‘з«ҷзҡ„е®ҳж–№еҫ®еҚҡиў«й»‘дәҶпјҢеҸ‘дәҶжқЎеҒҮж¶ҲжҒҜпјҢдҪ еҒҡзҡ„жҠ•иө„з»„еҗҲеҸҲзҷҪзһҺдәҶпјҲзңҹдәӢпјҡStocks plunge, recover after fake tweetпјүпјӣ
еҰӮжһңдҪ зҡ„иҫ“е…ҘжҳҜеҺҶеҸІиӮЎд»·гҖҒж”ҝзӯ–и¶ӢеҠҝгҖҒеӣҪйҷ…新闻并иҮӘеҠЁеҲӨж–ӯж–°й—»зҡ„зңҹеҒҮпјҢз»“жһң第дәҢеӨ©Aе…¬еҸёжҖ»йғЁең°йңҮдәҶпјҢAе…¬еҸёд»ҺжӯӨдёҖ蹶дёҚжҢҜпјҢдҪ зҡ„жҠ•иө„еҸҲзҷҪзһҺдәҶгҖӮ
иғҪеҪұе“ҚиӮЎд»·зҡ„factorеӨӘеӨҡпјҢжүҖжңүжЁЎеһӢдёҚз®Ўз®ҖеҚ•/еӨҚжқӮпјҢйғҪжңүйҖӮз”ЁиҢғеӣҙе’Ңиў«еқ‘зҡ„ж—¶еҖҷпјҢжүҖд»ҘжңәеҷЁеӯҰд№ пјҲжҲ–иҖ…иҜҙз»ҹи®Ўпјүиҝҷз§ҚдёңиҘҝдёҚиғҪдёҚдҝЎпјҢдҪҶеҲҮеҝҢе…ЁдҝЎгҖӮ
з®ҖиҖҢиЁҖд№ӢпјҢжңәеҷЁеӯҰд№ еҸ‘зҺ°зҡ„жҳҜдәӢзү©зҡ„зӣёе…іжҖ§пјҲиҫ“е…Ҙ-иҫ“еҮәжҳ е°„пјүпјҢеңЁжңүйҷҗзҡ„ж ·жң¬йӣҶе’ҢдёҖе®ҡзҡ„еҒҮи®ҫдёӢеҸҜд»ҘжҺЁе№ҝеҲ°жңӘзҹҘдәӢзү©пјҢиҖҢдё”жЁЎеһӢеҸҜд»ҘзӣёеҜ№жҜ”иҫғеӨҚжқӮпјҢиғҪе»әжЁЎзӣёеҜ№еӨҚжқӮзҡ„иҫ“е…Ҙ-иҫ“еҮәжҳ е°„пјҢдҪҶеҫҲйҡҫдҝқиҜҒзЁіе®ҡжҖ§е’Ңе®ҢеӨҮжҖ§пјӣеҸҰдёҖж–№йқўз»ҹи®ЎеӯҰ家жӣҙе…іеҝғзЁіе®ҡжҖ§пјҲзҪ®дҝЎеҢәй—ҙпјүе’Ңе®ҢеӨҮжҖ§пјҲжЁЎеһӢйҖүжӢ©пјүзӯүпјҢжӣҙжіЁйҮҚиғҢеҗҺзҡ„зҗҶи®әдҝқиҜҒпјҢдҪҶиҝҷд№ҹйҷҗеҲ¶дәҶиҝҮеҲҶеӨҚжқӮзҡ„жЁЎеһӢзҡ„дҪҝз”ЁпјҢеӣ дёәиҝҮеҲҶеӨҚжқӮзҡ„жЁЎеһӢйҡҫд»Ҙз”Ёж•°еӯҰеҲ»з”»пјҢд№ҹе°ұеҫҲйҡҫз»ҷеҮәзҗҶи®әдҝқиҜҒгҖӮ
з»ҹи®ЎеӯҰжӣҙжіЁйҮҚеҜ№дёҚзЎ®е®ҡжҖ§зҡ„йҮҸеҢ–пјҡж–№е·®пјҢзҪ®дҝЎеҢәй—ҙ
жңәеҷЁеӯҰд№ жӣҙе…іжіЁеҸҜи®Ўз®—жҖ§пјҢж— жі•еңЁеӨҡйЎ№ејҸж—¶й—ҙеҶ…и®Ўз®—еҮәжқҘзҡ„и§Јжі•дёҚеҸ«и§Јжі•
жңәеҷЁеӯҰд№ еңЁж•°жҚ®з§Қзұ»дёҠзҡ„йҖӮеә”жҖ§жӣҙе№ҝпјҡеӣҫзүҮпјҢи§Ҷйў‘пјҢж–Үеӯ—пјҢе…ізі»е’Ңе…ҙи¶Јеӣҫи°ұ
з»ҹи®ЎеӯҰзңӢдёҚдёҠжңәеҷЁеӯҰд№ зҡ„дёҖзӮ№пјҢе°ұжҳҜжңәеҷЁеӯҰд№ е–ңж¬ўжҠҠдёҖдёӘй—®йўҳеҪ“дҪңдјҳеҢ–й—®йўҳпјҲoptimizationпјүжқҘеҒҡгҖӮзҷҫеәҰ Deep Learning зҡ„иҖҒеӨ§ Andrew NgпјҲеҗҙжҒ©иҫҫпјүеңЁж–ҜеқҰзҰҸзҡ„жңәеҷЁеӯҰд№ иҜҫпјҢ第дёҖи®Іе°ұдјҡжҸҗеҲ° gradient descentгҖӮ然иҖҢпјҢеҜ№дәҺдјҳеҢ–жүҖеҫ—зҡ„з»“жһңжңүеӨҡзЎ®е®ҡжҲ–жҳҜдёҚзЎ®е®ҡпјҢжңәеҷЁеӯҰд№ е…іжіЁз”ҡе°‘гҖӮиҖҢиҝҷз§ҚеҜ№дёҚзЎ®е®ҡжҖ§зҡ„йҮҸеҢ–пјҢжҳҜз»ҹи®ЎеӯҰзҡ„з«Ӣиә«д№Ӣжң¬гҖӮж–№е·®е’ҢзҪ®дҝЎеҢәй—ҙжҳҜз»ҹи®ЎеӯҰзҡ„е…Ҙй—Ёзә§жҰӮеҝөпјҢеңЁеҗҙжҒ©иҫҫзҡ„иҜҫдёҠеҚҙеҫҲе°‘иў«жҸҗеҸҠгҖӮзјәд№ҸеҜ№дёҚзЎ®е®ҡжҖ§зҡ„йҮҸеҢ–е…іжіЁпјҢи®©з»ҹи®ЎеӯҰ家们жҖ»и§үеҫ—жңәеҷЁеӯҰд№ жҳҜеңЁзһҺжҗһгҖӮ
дёҚиҝҮпјҢжҜ”иө·з»ҹи®ЎеӯҰпјҢжңәеҷЁеӯҰд№ д№ҹжңүиҮӘе·ұзҡ„е·ЁеӨ§дјҳеҠҝпјҢе°ұжҳҜеҜ№еҸҜи®Ўз®—жҖ§зҡ„е…іжіЁгҖӮ
еңЁжңәеҷЁеӯҰд№ зҡ„еӯҰжңҜеңҲйҮҢпјҢеҪ“жңүдәәи·ҹдҪ иҜҙд»–и§ЈеҶідәҶдёҖдёӘй—®йўҳпјҢд»–еҫҲеҸҜиғҪжҳҜиҜҙд»–жүҫеҲ°дәҶдёҖдёӘеӨҡйЎ№ејҸж—¶й—ҙзҡ„и§Јжі•гҖӮе°ұеғҸжүҖжңүи®Ўз®—жңә科еӯҰзҡ„еӯҗеӯҰ科дёҖж ·пјҢжңәеҷЁеӯҰд№ еҸӘе…іжіЁеңЁжңүйҷҗж—¶й—ҙеҶ…зҡ„еҸҜи®Ўз®—жҖ§гҖӮз ”з©¶NP-hardзҡ„й—®йўҳжҳҜж— ж„Ҹд№үзҡ„пјҢдёҚеҰӮеҸ–иҝ‘дјјжқҘз®ҖеҢ–дёҖдёӢй—®йўҳгҖӮеҜ№з»ҹи®ЎеӯҰжқҘиҜҙпјҢиҝҷз§Қиҝ‘дјјеӨ§жҰӮжҳҜж— жі•жҺҘеҸ—зҡ„еҰҘеҚҸгҖӮ然иҖҢжӯЈжҳҜиҝҷз§ҚеҰҘеҚҸпјҢдҝғжҲҗдәҶжңәеҷЁеӯҰд№ д»ҺеӯҰжңҜеҲ°е·Ҙдёҡзҡ„и·ғиҝҒгҖӮ
иҖҢдё”пјҢиҷҪ然иҜҙз»ҹи®ЎеӯҰжҳҜд»Һж•°жҚ®дёӯеӯҰд№ пјҢжңәеҷЁеӯҰд№ д№ҹжҳҜд»Һж•°жҚ®дёӯеӯҰд№ пјҢдҪҶж•°жҚ®е’Ңж•°жҚ®дёҚеӨ§дёҖж ·гҖӮз»ҹи®ЎеӯҰзҡ„ж•°жҚ®еҸӘжҳҜж•°еӯ—пјҢиҖҢжңәеҷЁеӯҰд№ зҡ„йҖӮеә”жҖ§жӣҙе№ҝдёҖдәӣгҖӮд»ҺеӯҰжңҜеҲ°е·Ҙдёҡзҡ„и·ғиҝҒеҰӮеҗҢејҖеҗҜдәҶжҪҳеӨҡжӢүд№Ӣзӣ’пјҢиҝҷйҮҢзҡ„ж•°жҚ®жңүеӣҫзүҮпјҢи§Ҷйў‘пјҢзҪ‘йЎөпјҢиҝҳжңүдәәдёҺдәәд№Ӣй—ҙзҡ„зӨҫдәӨе…ізі»е’Ңе…ҙи¶Јеӣҫи°ұгҖӮеҪ“жңәеҷЁеӯҰд№ ејҖе§Ӣз ”з©¶иҝҷдәӣзҡ„ж—¶еҖҷпјҢз»ҹи®ЎеӯҰе°ұеҫҲйҡҫеҶҚиҝҪдёҠдәҶгҖӮ
жүҖд»ҘпјҢдёәд»Җд№Ҳз»ҹи®ЎеӯҰ家дёҚи®ӨеҗҢжңәеҷЁеӯҰд№ зҡ„и§ӮзӮ№пјҢеӣ дёәжңәеҷЁеӯҰд№ дёҚе…іжіЁдёҚзЎ®е®ҡжҖ§пјҢйӮЈдёәд»Җд№ҲжңҖеҗҺжҗһз»ҹи®ЎеӯҰзҡ„жңҖеҗҺйғҪеҺ»еҒҡжңәеҷЁеӯҰд№ дәҶпјҢеӣ дёәжңәеҷЁеӯҰд№ зҡ„еә”з”ЁиҢғеӣҙжӣҙе№ҝпјҢжҲҗе°ұжӣҙе®№жҳ“д№ҹжӣҙеӨ§гҖӮ
STATе’ҢMLзҡ„е…·дҪ“е·®ејӮдёҠйқўиҜёдҪҚе·Із»ҸжҲҗеҗ„дёӘи§’еәҰи®Ёи®әдәҶеҫҲеӨҡпјҲдёҚиөһжҲҗMLжӣҙйқ иҝ‘Bayesianзҡ„и§ӮзӮ№пјүпјҢдҪҶйҖ жҲҗдёӨй—ЁеӯҰ科и§ӮзӮ№е·®ејӮзҡ„ж №жәҗиҝҳжҳҜеӯҰ科еҸ‘еұ•иҮӘиә«еёҰжқҘзҡ„вҖңж–№жі•и®әвҖқгҖҒвҖңдё–з•Ңи§ӮвҖқзҡ„е·®ејӮпјҢжҚўеҸҘиҜқиҜҙпјҢдҪҶеҮЎж¶үеҸҠвҖңж–№жі•и®әвҖқзӯүзҡ„и§ӮзӮ№пјҢдёӨй—ЁеӯҰ科йғҪдјҡжңүдёҚе°Ҹзҡ„е·®ејӮгҖӮ
STATжқҘжәҗдәҺж•°еӯҰпјҢжҲ–иҖ…еҮҶзЎ®ең°иҜҙпјҢи„ұиғҺдәҺжҰӮзҺҮи®әгҖӮеӣ жӯӨпјҢSTATжҲ–еӨҡжҲ–е°‘дҝқз•ҷдәҶж•°еӯҰиҝҷй—ЁеӯҰ科зңӢеҫ…вҖңж–№жі•и®әвҖқзҡ„и§ӮзӮ№пјҢжҜ”еҰӮпјҢйҮҮз”Ёз»Ҹе…ёзҡ„вҖңеҒҮи®ҫ-жҺЁзҗҶ-з»“и®әвҖқд»ҘеҸҠвҖңжңӘз»ҸиҜҒжҳҺеҲҷдёҚиғҪдҪҝз”ЁвҖқиҝҷж ·зҡ„жҖқз»ҙжЁЎејҸгҖӮеӣ жӯӨпјҢSTATе’ҢMLеҜ№дёҖдәӣеӯҰжңҜи§ӮзӮ№зҡ„жҢҒжңүдёҚеҗҢжҖҒеәҰпјҢжң¬иҙЁдёҠе°ұжҳҜж•°еӯҰдёҺе…¶д»–еӯҰ科еҜ№дёҖдәӣй—®йўҳжҢҒжңүдёҚеҗҢзҡ„жҖҒеәҰгҖӮеӣ жӯӨпјҢеңЁSTATдёӯпјҢиҜ„д»·дёҖдёӘжЁЎеһӢпјҲжҲ–дј°и®Ўж–№жі•пјүпјҢжӣҙзӣёеҪ“дәҺжҳҜдёҖдёӘе®ҡзҗҶпјҢжҜ”еҰӮпјҡвҖңеңЁз¬ҰеҗҲеҒҮи®ҫжқЎд»¶дёӢпјҢжңҖе°ҸдәҢд№ҳдј°и®Ўе°ұжҳҜпјҲеңЁжҹҗз§Қж ҮеҮҶдёӢпјүжҳҜжңҖдјҳзҡ„гҖӮвҖқиҝҷж ·зҡ„жЁЎеһӢпјҲе®ҡзҗҶпјүз»ҷеҮәдәҶе…іжіЁеҜ№иұЎзҡ„йҖӮз”ЁжқЎд»¶пјҲеҒҮи®ҫпјүе’Ңдёәд»Җд№ҲдјҡжҳҜжҲҗз«Ӣзҡ„пјҲжҺЁзҗҶпјүпјҢи®Іеҫ—жё…жҘҡд»Җд№Ҳж—¶еҖҷеҸҜд»Ҙз”Ёд»Җд№Ҳж—¶еҖҷдёҚеҸҜд»Ҙз”ЁгҖӮжіЁж„ҸпјҢиҝҷйҮҢжҳҜжҢҮжҳҜеҗҰеҸҜд»ҘдҪҝз”ЁпјҢиҖҢдёҚжҳҜдҝқиҜҒдҪҝз”ЁеҗҺж•ҲжһңжҳҜеҗҰеҘҪгҖӮпјҲж•ҲжһңдёҠпјүеҘҪз”Ёе’ҢпјҲйҖ»иҫ‘дёҠпјүеҸҜз”ЁжҳҜдёӨеҘ—дёҚеҗҢзҡ„иҜ„д»·дҪ“зі»пјҢжҹҗдәӣжғ…еҶөдёӢжҲ‘们еҪ“然жңҹжңӣдёӨиҖ…е…јйЎҫгҖӮ
еӨҡиҜҙеҮ еҸҘж•°еӯҰгҖӮж•°еӯҰжҳҜдёҖй—ЁеҪўејҸйҖ»иҫ‘еӯҰ科пјҢж•°еӯҰжң¬иә«зҡ„еӯҰ科йҖ»иҫ‘е’ҢеҸ‘еұ•жҳҜжәҗдәҺеҸӨеёҢи…Ҡзҡ„йӮЈдёҖеҘ—пјҢеҪ“然зҺ°еңЁе·Із»ҸеәһеӨ§зІҫз»ҶеӨҚжқӮеҲ°дёҚеҸҜеҗҢж—ҘиҖҢиҜӯдәҶгҖӮж•°еӯҰд»ҺжқҘдёҚдјҡе…іеҝғеҫ—еҲ°з»“жһңдјҡжңүд»Җд№Ҳз”ЁпјҢдёҚдјҡе…іеҝғиҮӘе·ұжҳҜеҗҰеҒҡдәҶдёҖдәӣеҫ®е°Ҹзҡ„иҙЎзҢ®пјҢж•°еӯҰеҸӘжҳҜеңЁж„Ҹеҫ—еҲ°зҡ„з»“и®әжҳҜеҗҰжҳҜз¬ҰеҗҲйҖ»иҫ‘зҡ„гҖӮи®ІйҒ“зҗҶпјҢж•°еӯҰиҝҷд№Ҳй«ҳеҶ·пјҢе°ұеә”иҜҘи¶ҠжқҘи¶Ҡе°Ҹдј—гҖҒи¶ҠжқҘи¶ҠејҸеҫ®пјҢдҪҶжҳҜпјҢеҘҪеҹәеҸӢзү©зҗҶи·іеҮәжқҘдёәж•°еӯҰеҸ«еҘҪпјҢеӣ дёәеңЁиҝҷдёӘе®Үе®ҷдёӯзҡ„гҖҒзӣ®еүҚе·ІзҹҘзҡ„зү©зҗҶе®ҡеҫӢпјҢеҮ д№Һе…ЁйғЁз¬ҰеҗҲдәҶж•°еӯҰдёӯзҡ„з»“и®әпјҢ并且数еӯҰпјҲдҪңдёәе·Ҙе…·пјүжҳҜиғҪеӨҹжҲҗдёәжҢҮеҜјзү©зҗҶеҸ‘зҺ°зҡ„еҲ©еҷЁзҡ„гҖӮиҝҷдёҚжҳҜдёҖ件еҫҲеҘҮжҖӘзҡ„дәӢжғ…еҗ—пјҹж•°еӯҰжҳҜдәәзұ»иҮӘиә«YYзҡ„пјҢдёәжҜӣзү©зҗҶдё–з•Ңе°ұеҰӮжӯӨй«ҳзҡ„еҘ‘еҗҲиҝҷдәӣе‘ўпјҹ
иҜқйўҳжүҜеӣһжқҘпјҢSTATзҡ„з ”з©¶дёӯпјҢеҜ№дёҖдёӘж–°еҮәзҺ°зҡ„дј°и®ЎйҮҸпјҲжҲ–иҖ…з®—жі•пјүпјҢйҰ–е…ҲдјҡиҖғеҜҹе®ғзҡ„дёҖдәӣеҹәжң¬жҖ§иҙЁпјҢ然еҗҺиҮӘ然иҖҢ然зҡ„дјҡиҖғиҷ‘е®ғзҡ„жёҗиҝӣжҖ§иҙЁпјҡеҲ°еә•ж ·жң¬и¶ҠеӨ§д»ҘеҗҺпјҢиҝҷдёӘ估计收дёҚ收ж•ӣпјҹ收ж•ӣзҡ„иҜқжҳҜеҗҰжңүдјҳеҢ–йҖҹзҺҮзҡ„йҖүжӢ©ж–№жЎҲпјҹж–№е·®жҖҺд№Ҳи®Ўз®—пјҹзӯүзӯүдёҖзі»еҲ—зҗҶи®әдёҠйңҖиҰҒи§ЈеҶізҡ„й—®йўҳгҖӮжҜ”еҰӮпјҢEMз®—жі•зЎ®е®һеҘҪз”ЁпјҢдҪҶ Jeff Wu е°ұжҳҜиҰҒеҺ»иҜҒжҳҺ其收ж•ӣжҖ§пјӣCoxиҮӘе·ұд№ҹиҜҙдёҚжё…жҘҡдёәд»Җд№ҲпјҲз”ҹеӯҳеҲҶжһҗдёӯCoxжЁЎеһӢзҡ„пјүеҒҸ似然иғҪеӨҹдҝқз•ҷеӨ§йғЁеҲҶзҡ„дҝЎжҒҜпјҢдҪҶд»Қ然数еҚҒе№ҙеүҚд»ҶеҗҺ继зҡ„и®әж–ҮжҠҠиҝҷдёӘй—®йўҳи®Іжё…жҘҡдәҶгҖӮжңүдәӣдәәдјҡй—®жҗһSTATзҡ„дәәпјҢдёәд»Җд№ҲдҪ еҜ№иҜҒжҳҺиҝҷдёӘиҜҒжҳҺйӮЈдёӘйӮЈд№ҲзҶҹз»ғе•Ҡпјҹеӣ дёәSTATжң¬иә«е°ұиҮӘ然иҖҢ然ең°е…іеҝғиҝҷдәӣдәӢжғ…гҖӮжЁЎеһӢжҳҜеҗҰиғҪеӨҹеңЁзҗҶи®әдёҠдҝқжҢҒйҖ»иҫ‘дёҖиҮҙпјҢиҝҷеҜ№STATжқҘиҜҙеҫҲйҮҚиҰҒпјҢиҖҢеҰӮжһңжЁЎеһӢеңЁе®һйҷ…еә”з”Ёдёӯж•Ҳжһңд№ҹеҫҲеҘҪзҡ„иҜқпјҢиҝҷе°ұз®—жҳҜдёҖдёӘй”ҰдёҠж·»иҠұзҡ„жғҠе–ңгҖӮ
дёҚдёҘж јең°иҜҙпјҢSTATз®—жҳҜmethod/model-driven зҡ„еӯҰ科пјҢMLз®—жҳҜdata-driven зҡ„еӯҰ科пјҢиҝҷйҮҢеҜ№STATжқҘиҜҙзҡ„modelжҳҜжҜ”иҫғдёҘж јзҡ„гҖҒиҮіе°‘з»ҸиҝҮдёҘеҜҶи®әиҜҒзҡ„пјҢиҖҢдёҚжҳҜйҡҸж„Ҹзҡ„еӨ„зҗҶжүӢжі•йғҪиғҪз§°дёәmodelгҖӮ
жҖ»дҪ“жқҘзңӢпјҢжҲ‘и®ӨдёәеҸҰдёҖдёӘзӯ”дё»зҡ„йӮЈеҸҘвҖңз»ҹи®ЎеӯҰ家жӣҙе…іеҝғжЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§пјҢиҖҢжңәеҷЁеӯҰд№ дё“е®¶жӣҙе…іеҝғжЁЎеһӢзҡ„йў„жөӢиғҪеҠӣвҖқиҝҳз®—жҳҜиҜҙзҡ„жҜ”иҫғеңЁзҗҶзҡ„гҖӮжҲ–иҖ…жҚўеҸҘиҜқиҜҙпјҢз»ҹи®ЎеӯҰ家жӣҙе…іеҝғжһ„жҲҗmodelзҡ„еҸҳйҮҸе’ҢеҸӮж•°пјҢиҖҢжңәеҷЁеӯҰд№ дё“е®¶жӣҙе…іеҝғйў„жөӢзҡ„з»“жһңгҖӮдҪҶиҝҷдәӣжҜ•з«ҹд№ҹеҸӘжҳҜзӣёиҫғиҖҢиЁҖгҖӮ
дёҫдёӘдҫӢеӯҗпјҢеҗҢж ·жҳҜзәҝжҖ§еӣһеҪ’пјҢз»ҹи®ЎеӯҰ家дјҡеҺ»зңӢжҜҸдёӘеҸҳйҮҸжҳҜдёҚжҳҜsignificantпјҢresidualеҲҶеёғжҳҜдёҚжҳҜжҺҘиҝ‘GaussianпјҢд»–д№ҹеҸҜиғҪдјҡз”Ёforward/backwardзӯүдёҖдәӣж–№жі•жқҘйҖүжӢ©еҸҳйҮҸгҖӮиҝҷдёҖж–№йқўжҳҜеҮәдәҺеҜ№modelжүҖеҹәдәҺзҡ„еҒҮи®ҫзҡ„йӘҢиҜҒпјҲеңЁеҗҲзҗҶеҒҮи®ҫдёӢOLSжҳҜBLUEпјүпјҢеҸҰдёҖж–№йқўд№ҹжҳҜеӣ дёәе®һйҷ…еә”з”ЁдёӯпјҢзәҝжҖ§еӣһеҪ’еҸҜд»Ҙз”ЁжқҘжЈҖйӘҢyжҳҜеҗҰеҸҜд»Ҙз”ЁеҸҳйҮҸxи§ЈйҮҠгҖӮеӣ иҖҢз»ҹи®ЎеӯҰ家еңЁеҒҡзәҝжҖ§еӣһеҪ’зҡ„ж—¶еҖҷпјҢдјҡжҜ”иҫғеңЁж„ҸжҜҸдёӘеҸҳйҮҸеҸҠе…¶еҜ№еә”зҡ„еҸӮж•°гҖӮ
дҪҶеҜ№дәҺдёҖдёӘеҒҡжңәеҷЁеӯҰд№ зҡ„дәәжқҘиҜҙпјҢиҝҷдәӣйғҪдёҚйҮҚиҰҒпјҢз”ҡиҮіscikit-learnйҮҢйқўзҡ„зәҝжҖ§еӣһеҪ’йғҪжІЎжңүи®Ўз®—tеҖјгҖҒpеҖјзҡ„еҠҹиғҪгҖӮйӮЈд№ҲдёҮдёҖеј•е…ҘдәҶдёҚиҜҘеј•е…Ҙзҡ„еҸҳйҮҸжҖҺд№ҲеҠһпјҹеҫҲз®ҖеҚ•пјҢеҠ regularizationе•ҠпјҢиҰҒsparseеҠ L1пјҢеҸӘжұӮйў„жөӢж•ҲжһңеҘҪе°ұеҠ L2пјҢ然еҗҺеңЁvalidation setдёҠи°ғlambdaгҖӮжҖ»д№ӢжҲ‘иҝҪжұӮзҡ„зӣ®ж ҮеҸӘжңүдёҖдёӘпјҢеңЁtest setдёҠжҲ‘зҡ„йў„жөӢеҖји·ҹе®һйҷ…еҖји¶ҠжҺҘиҝ‘и¶ҠеҘҪпјҢеҜ№жҲ‘жқҘиҜҙеҸҳйҮҸе’ҢеҸӮж•°йғҪеҲҶеҲ«еҸӘжҳҜдёҖдёӘеҗ‘йҮҸиҖҢе·ІгҖӮ
жүҖд»ҘеғҸеүҚйқўжңүдёҖдҪҚзӯ”дё»иҜҙзҡ„пјҢз»ҹи®ЎеӯҰеңЁйў„жөӢзҡ„ж—¶еҖҷйҖҡеёёдјҡж №жҚ®жҰӮзҺҮжЁЎеһӢз»ҷеҮәдёҖдёӘзҪ®дҝЎеҢәй—ҙпјҢиҖҢжңәеҷЁеӯҰд№ еҲҷдёҖиҲ¬дёҚдјҡиҝҷд№ҲеҒҡпјӣзӣёжҜ”д№ӢдёӢеә”з”ЁеұӮйқўзҡ„жңәеҷЁеӯҰд№ зҰ»ж•°еӯҰжӣҙиҝңгҖӮ
дҪҶиҝҷд№ҹ并йқһз»қеҜ№пјҢжҜ”еҰӮжңәеҷЁеӯҰд№ дёӯд№ҹдјҡз”ЁеҲ°baysian inferenceзҡ„дёңиҘҝжқҘе»әз«ӢжҰӮзҺҮжЁЎеһӢпјҢgraphical modelдёӯд№ҹдјҡз»Ҹеёёж¶үеҸҠжҰӮзҺҮзҡ„и®Ўз®—гҖӮз”ҡиҮіеҒҡlearning theoryзҡ„йӮЈжү№дәәз»Ҹеёёдјҡз”Ёж•°еӯҰзҗҶи®әжқҘиҜҒжҳҺдёәд»Җд№ҲжңәеҷЁеӯҰд№ з®Ўз”ЁгҖҒжҖҺж ·иғҪд»ҺиҝҷдёӘиҜҒжҳҺдёӯиҺ·еҫ—жӣҙеҘҪзҡ„еӯҰд№ з®—жі•гҖӮ
дёҚиҝҮlearning theoryжүҖе…іеҝғзҡ„пјҢдёҖиҲ¬д№ҹеҸӘжҳҜз”Ёи®ӯз»ғйӣҶзҡ„errorе’ҢжЁЎеһӢзҡ„еӨҚжқӮеәҰжқҘжұӮиҝҷдёӘжЁЎеһӢеңЁжүҖжңүеҸҜиғҪзҡ„ж•°жҚ®дёҠзҡ„errorзҡ„дёҠйҷҗпјҢжүҖд»ҘеҪ’ж №еҲ°еә•е…іеҝғзҡ„иҝҳжҳҜйў„жөӢиғҪеҠӣиғҪеҗҰжіӣеҢ–еҲ°жІЎи§ҒиҝҮзҡ„ж•°жҚ®гҖӮиҮідәҺз»ҹи®ЎеӯҰзҡ„зҗҶи®әз ”з©¶пјҢжҒ•жҲ‘зӣёе…іж–ҮзҢ®иҜ»зҡ„е°‘пјҢдҪҶжҚ®жҲ‘дәҶи§ЈиҝҳжҳҜжңүдёҖе®ҡж•°йҮҸйӣҶдёӯеңЁйҖҡиҝҮжҰӮзҺҮжЁЎеһӢжқҘи§ЈйҮҠжҹҗдәӣзҺ°иұЎпјҢд»ҺиҖҢи§ЈеҶіеј•з”іеҮәжқҘзҡ„й—®йўҳпјҢеӣ жӯӨеҰӮдҪ•з”ЁжңүеҗҲзҗҶдҫқжҚ®зҡ„ж–№ејҸжҠҠеҸҳйҮҸж”ҫиҝӣжЁЎеһӢйҮҢе°ұжҳҜдёҖдёӘйҮҚиҰҒй—®йўҳдәҶгҖӮ
гҖҢиҒҪиӘӘдәһжҙІдәәйғҪд№ізі–дёҚиҖҗгҖҚпјӣ
гҖҢиҒҪиӘӘзҫҺеңӢдәәйғҪеҫҲй–Ӣж”ҫгҖҚгҖӮ
иҝҷй—®йўҳй—®еҫ—иІҢдјјжңәеҷЁеӯҰд№ и·ҹз»ҹи®ЎйҮҚеҸ еҫҲеӨ§дјјзҡ„, зү№жӯӨжҫ„жё…:
и·ҹз»ҹи®ЎжүҜдёҚдёҠиҫ№зҡ„жңәеҷЁеӯҰд№ д№ҹжңүдёҖеӨ§зұ»
йӮЈзұ»жҳҜжҠҠиө„ж–ҷзӮ№еҪ“жҲҗеҮ дҪ•з©әй—ҙзҡ„зӮ№, е…іжіЁзҡ„жҳҜжҺ’йҷӨдёҚйҮҚиҰҒзҡ„еҮ дҪ•жҖ§иҙЁе№¶з»ҙжҢҒйҮҚиҰҒзҡ„еҮ дҪ•жҖ§иҙЁ, ж¶өзӣ–Manifold learningи·ҹеӨ§йғЁеҲҶзҡ„йҷҚз»ҙеҲҶзҫӨз®—жі•, еҫ®еҲҶжөҒеҪў, жөӢеәҰз©әй—ҙи·ҹжӢ“жңҙеӯҰжүҚжҳҜйӮЈзұ»з®—жі•зҡ„еҹәзЎҖ,
иҝҷеҸӘжҳҜдёҖдёӘж №жҚ®жҲ‘дёӘдәәз»ҸйӘҢзҡ„з®ҖеҚ•зҡ„иҜҙжі•пјҡжҚўеҸҘиҜқиҜҙпјҢе®ғиӮҜе®ҡдёҚдјҡ100%иҜҙеҫ—йҖҡгҖӮдҪҶ既然еҗ„дҪҚи®Ёи®әзҡ„йғҪжҳҜеӨҡе°‘жҮӮз»ҹи®ЎпјҢжғіеҝ…дјҡеҲӨж–ӯжҲ‘и®Ізҡ„еҲ°еә•жҳҜдёҖиҲ¬жғ…еҶөиҝҳжҳҜзү№ж®ҠдҫӢеӯҗпјҢжҜ•з«ҹз»ҹи®ЎжҳҜеңЁи°ҲеӨ§йғЁд»Ҫзҡ„гҖӮ
еҪ“е№ҙжҲ‘её®еҗҢеӯҰзҡ„и®әж–Үи·‘зӣёе…іжҖ§йӘҢиҜҒж—¶пјҢR square=53%д»–д№ҹз…§еҶІпјҢиҝҳеҶІиҝҮеҺ»дәҶпјҢжүҖд»Ҙе•ҰвҖҰжҲ‘们иҒҠдёӘеӨ§жҰӮе°ұеҘҪдәҶгҖӮ
иҝӣеҢ–?д»Һе“ӘжқҘзҡ„пјҢеҫҖе“ӘеҺ»?иҝҷдёӘй—®йўҳеҫҲеҘҪеӣһзӯ”пјҢд»ҺеӣҪе°ҸдёҖе№ҙзә§дёҖи·ҜеҫҖеҗҺзңӢе°ұеҘҪдәҶгҖӮ
жңҖејҖе§ӢпјҢжҲ‘们еӯҰз®—жңҜпјҢз®—жңҜйўҳдёҖе®ҡдјҡз®—еҮәдёҖдёӘе”ҜдёҖзҡ„жӯЈзЎ®и§ЈпјҢ1еҠ 1дёҚеҸҜиғҪжҳҜ2д»ҘеӨ–зҡ„е…¶д»–зӯ”жЎҲгҖӮеӣәе®ҡзҡ„иҫ“е…Ҙе’Ңеӣәе®ҡзҡ„еӨ„зҪ®пјҢеҝ…然дјҡеҫ—еҲ°еӣәе®ҡзҡ„з»“жһңгҖӮ
жҺҘзқҖпјҢеҮәзҺ°дәҶгҖҢдёҖжһҡе…¬е№ізҡ„й’ўи№ҰдёўжЎҢйқўпјҢдјҡжҳҜеӯ—иҝҳжҳҜиҠұгҖҚзҡ„й—®йўҳгҖӮзҗҶи®әдёҠпјҢеҰӮжһңдҪ еҸҜд»ҘжҠҠжүҖжңүдјҡеҪұе“Қз»“жһңзҡ„еҸҳж•°пјҢеҢ…еҗ«зЎ¬еёҒиҙЁйҮҸгҖҒиҙЁеҝғгҖҒжҺҘи§ҰжЎҢйқўвҖӢвҖӢи§’еәҰгҖҒйҖҹеәҰгҖҒжҺҘи§ҰйқўзЎ¬еәҰгҖҒеҪўзҠ¶гҖҒзЈЁж“Ұзі»ж•°гҖҒеҪ“ж—¶йЈҺйҖҹгҖҒйЈҺеҗ‘вҖҰ.еҘҪеҗ§пјҢзһҺдёҫдҫӢиҖҢе·ІпјҢдёҚеҶҚеҲ—дәҶгҖӮжҖ»д№Ӣе°ұжҳҜеҫҲеӨҡеҫҲеӨҡпјҢеҗ„ејҸеҗ„ж ·дјҡеҪұе“Қз»“жһң(Y)зҡ„еӣ еӯҗ们(Xi)пјҢеҸҠиҝҷдәӣеӣ еӯҗе’Ңз»“жһңзҡ„е…ізі»(е…¬ејҸ)жүҫеҮәжқҘпјҢзҗҶи®әдёҠдҪ еә”иҜҘжҳҜеҸҜд»Ҙз®—еҮәгҖҢдёҖжһҡй’ўи№ҰдёўжЎҢйқўпјҢдјҡжҳҜеӯ—иҝҳжҳҜиҠұгҖҚзҡ„з»“жһңгҖӮ
дҪҶе®һйҷ…дёҠпјҢд»ҺжқҘйғҪжІЎдәәиҝҷд№Ҳе№ІгҖӮиҝҷиҜҙзҡ„жҳҜпјҢзҗҶи®әи§Ј(е…¬ејҸжұӮе”ҜдёҖи§Ј)жҳҜжңүзҡ„пјҢдҪҶеҪ“ж•°еӯҰжЁЎеһӢеӨҚжқӮеҲ°и¶…иҝҮдёҖдёӘйҷҗеәҰж—¶пјҢзҗҶи®әжұӮи§Је°ұж— ж„Ҹд№үдәҶгҖӮе®һйҷ…дёҠпјҢжҲ‘们дјҡиҜҙгҖҢиҝҷж¬ЎдҪ дёўеҮәжҳҜеӯ—иҝҳжҳҜиҠұпјҢжҲ‘дёҚзҹҘйҒ“гҖӮдҪҶеҰӮжһңдҪ дёўдёӘдёҖдёҮж¬ЎпјҢйӮЈдә”д»ҹеӯ—дә”д»ҹиҠұеҗ§вҖҰ.еӨ§жҰӮжҳҜиҝҷж ·е•ҰпјҢе°ұз®—е·®д№ҹдёҚдјҡе·®еҲ°зҷҫеҲҶд№Ӣйӣ¶зӮ№еҮ гҖӮгҖҚ
й—®жҲ‘дёәд»Җд№Ҳ?дёҚзҹҘйҒ“гҖӮдҪ дёҚдҝЎ?йӮЈжқҘиҜ•иҜ•!е°ұжңүдәҶз»ҹи®ЎгҖӮ
жҲ‘и®ӨдёәпјҢз»ҹи®ЎжҳҜз®—жңҜзҡ„иҝӣеҢ–пјҢе®ғеңЁж•°еӯҰжЁЎеһӢеӨҚжқӮеҲ°ж— жі•жұӮеҮәзҗҶи®әи§Јж—¶пјҢи·іиҝҮдёӯй—ҙжұӮи§ЈиҝҮзЁӢпјҢдҫқйқ еӨ§йҮҸзҡ„ж•°жҚ®и§ӮеҜҹжүҫеҮәеӣ жһңд№Ӣй—ҙзҡ„е…іиҒ”жҖ§пјҢе»әз«ӢдәҶз»ҹи®Ўж•°жЁЎгҖӮзЁіе®ҡеҲ¶зЁӢеҫ—еҮәзҡ„дә§е“Ғз»“жһңе‘Ҳй«ҳж–ҜеҲҶй…ҚпјҢе°ұжҳҜжңҖе…ёеһӢзҡ„дҫӢеӯҗпјҢжҲ‘们еҸҜд»ҘзӣҙжҺҘд»ҘиҝҷдёӘдҫӢеӯҗеҸ‘еұ•еҮәз»ҹи®ЎеҲ¶зЁӢз®ЎеҲ¶(SPC)зҗҶи®әгҖӮ
йӮЈеҰӮжһңй—®йўҳжӣҙеӨҚжқӮдәӣе‘ў?жҜ”ж–№иҜҙдёҠж®өиҜҙзҡ„пјҢзЁіе®ҡеҲ¶зЁӢе‘ҲдёҖдёӘй«ҳж–ҜеҲҶеёғпјҢдҪ з”Ёе№іеқҮеҖјеҠ еҮҸдёүеҖҚж ҮеҮҶе·®е°ұиғҪдҪңдёҠдёӢйҷҗз®ЎжҺ§дәҶпјҢдҪҶеҰӮжһңдҪ зҡ„дә§е“ҒжҳҜжқҘиҮӘдә”еҸ°жңәеҷЁпјҢж•°жҚ®жҳҜдә”дёӘй«ҳж–ҜеҲҶеёғзҡ„еҸ еҠ е‘ў?йӮЈдҪ е°ұеҸӘеҘҪиҜ·еҮәжңәеҷЁеӯҰд№ зҡ„ж··еҗҲй«ҳж–ҜжЁЎејҸ(GMM)жқҘдәҶгҖӮ
жҲ‘们дёәд»Җд№ҲдёҚжҠҠдә”дёӘй«ҳж–ҜеҲҶеёғз”Ёз»ҹи®ЎзҗҶи®әеҲҶеҲ«жӢҶи§Ј? вҖ”иҝҷж•°жЁЎеӨӘеӨҚжқӮдәҶгҖӮ
既然没жңүз»ҹи®Ўи§ЈйҮҠпјҢйӮЈиҝҷдәӣж•°жҚ®зҡ„еӣ жһңеҲ°еә•жңүжІЎе…ізі»(е…¬ејҸ)?вҖ”еә”иҜҘжңүеҗ§гҖӮ
йӮЈжҳҜд»Җд№Ҳе…ізі»?вҖ”и®ІдёҚеҮәжқҘгҖӮ
йӮЈдҪ жҖҺд№ҲзЎ®е®ҡжңүе…ізі»вҖ”е•ҠвҖҰдёҚе°ұжҳҜзңӢжө·йҮҸиө„ж–ҷпјҢиҝҷж ·зҡ„з»„еҗҲиҝӣе°ұдёҖе®ҡдјҡжңүйӮЈж ·зҡ„з»“жһңеҮәпјҢз»„еҗҲеӨҡжІЎе•ҘдәҶдёҚиө·пјҢи®©жңәеҷЁиҮӘе·ұж…ўж…ўзңӢдёҚе°ұеҘҪдәҶгҖӮ
жҖҺд№Ҳжүҫе…ізі»вҖ”е°ұз”ЁжңәеҷЁеӯҰд№ еҳӣгҖӮ
иҝҷж®өиҝҮзЁӢи·ҹеүҚйқўд»Һз®—жңҜдёӯдә§з”ҹз»ҹи®Ўзҡ„иҝҮзЁӢе…¶е®һиҝҳж»ЎеғҸзҡ„гҖӮеӣ жӯӨпјҢжҲ‘жҸҗдёҖдёӘз®ҖеҚ•зҡ„иҜҙжі•–жңәеҷЁеӯҰд№ жҳҜз»ҹи®ЎеӯҰеңЁж•°еӯҰйўҶеҹҹзҡ„иҝӣеҢ–гҖӮ
еҫҲжңүж„ҸжҖқзҡ„жҳҜпјҢ欧зҫҺеҫҲеӨҡеӨ§дә’иҒ”зҪ‘дјҒдёҡзҡ„йҰ–еёӯеӨ§ж•°жҚ®з§‘еӯҰ家еҹәжң¬жқҘиҮӘдәҺеҮ дёӘдё“дёҡпјҡж•°еӯҰпјҲеҗ«з»ҹи®ЎеӯҰ家пјүгҖҒзү©зҗҶгҖҒи®ЎйҮҸз»ҸжөҺеӯҰгҖӮ
жңәеҷЁеӯҰд№ з®ҖеҚ•зІ—жҡҙпјҹж·ұеәҰеӯҰд№ зҗҶи®әзІ—жө…пјҹ
иҝҳжҳҜдёҠеӣҪеӨ–йЎ¶е°–жқӮеҝ—е’ҢеӨ§еӯҰзҪ‘з«ҷжҗңжҗңpapers жҜ”иҫғеҘҪгҖӮ
еӨ§зәҰжҠҠжңәеҷЁеӯҰд№ дё“е®¶е’Ңз»ҹ计专家еҲҶејҖпјҢжҳҜеӣ дёәеҜ№еҸҳйҮҸзҡ„еҲҶеёғгҖҒжқЎд»¶жҰӮзҺҮзҡ„и§ЈйҮҠгҖҒиҜҜе·®зҡ„еҲҶжһҗдёү件дәӢпјҢдјјд№ҺеҒҡжі•дёҚеҗҢпјҹ
дҪҶе®һйҷ…дёҠпјҢеҸӘжҳҜеҜ№дёү件дәӢзҡ„еӨ„зҗҶж–№ејҸпјҡеҮәеҸ‘зӮ№гҖҒи·Ҝеҫ„гҖҒжүӢж®өдёҚеҗҢзҪўдәҶгҖӮ
иҜҙжңәеҷЁеӯҰд№ дёҚзңӢеҲҶеёғпјҢдёҚз®ЎиҜҜе·®еҲҶжһҗвҖҰзҡ„пјҢе…¶е®һжңәеҷЁеӯҰд№ жҳҜиҰҒеҒҡзҡ„гҖӮеҸҳйҮҸзҡ„еҲҶеёғеҶіе®ҡдәҶжЁЎеһӢзҡ„еүҚжҸҗзІҫзЎ®еәҰпјҢеёёи§Ғзҡ„е…іиҒ”гҖҒеҚҸеҗҢиҝҮж»ӨгҖҒж”ҜжҢҒеҗ‘йҮҸжңәгҖҒиҙқеҸ¶ж–ҜеҲҶзұ»зӯүпјҢе…¶е®һйғҪеҸҜд»ҘеңЁиҖғиҷ‘еҸҳйҮҸеҲҶеёғзҡ„еүҚжҸҗдёӢпјҢи°ғж•ҙжЁЎеһӢзІҫеәҰгҖӮдёҺ常规з»ҹ计专家зҡ„ж–№жі•дёҚеҗҢд№ӢеӨ„еңЁдәҺпјҢжңәеҷЁеӯҰд№ жӣҙдҫ§йҮҚдәҺеңЁеҗ‘йҮҸз©әй—ҙж“ҚдҪңпјҢд»ҺиҖҢи§ЈеҶіеӨҡеҸҳйҮҸзҡ„й—®йўҳгҖӮеӣҙз»•зҹ©йҳөд»Јж•°зҡ„жҰӮзҺҮгҖҒеҫ®еҲҶж–№зЁӢгҖҒйҡҸжңәиҝҮзЁӢжҳҜжңәеҷЁеӯҰд№ зҡ„ж–№жі•и®әгҖӮ
еңЁиҜҜе·®зҡ„еӨ„зҗҶдёҠпјҢжңәеҷЁеӯҰд№ зҡ„иҖғиҷ‘ж–№ејҸд№ҹжӣҙеӨҚжқӮдёҖдәӣпјҢе…¶еҲ©з”ЁжӣҙеӨҡзҡ„жіӣеҮҪеҲҶжһҗжқҘи°ғж•ҙе…¶иҜҜе·®жҺ§еҲ¶гҖӮ
жҖ»дҪ“жқҘи®ІпјҢз»ҹи®ЎеӯҰжҳҜеңЁйҡҸжңәдәӢ件зҡ„еҲҶжһҗеҹәзЎҖдёҠпјҢдёҚж–ӯиһҚеҗҲзҹ©йҳөгҖҒеҫ®еҲҶж–№зЁӢгҖҒеҫ®з§ҜеҲҶзӯүж•°еӯҰжҖқжғіпјҢз”Ёж•°еӯ—жҸҸиҝ°йҡҸжңәдәӢ件зҡ„科еӯҰпјҢжҜ”жңәеҷЁеӯҰд№ иҰҒжӣҙеҹәзЎҖдёҖдәӣпјӣ
иҖҢжңәеҷЁеӯҰд№ пјҢжҳҜд»Һзҹ©йҳөгҖҒеҫ®еҲҶж–№зЁӢгҖҒжіӣеҮҪеҲҶжһҗгҖҒеҗ‘йҮҸеҫ®з§ҜеҲҶгҖҒйҡҸжңәиҝҮзЁӢгҖҒйҮҸеӯҗзү©зҗҶзӯүзҗҶи®әдёҠеҜ»жүҫеӨ§и§„жЁЎеӨҡз»ҙж•°жҚ®зҡ„жЁЎејҸиҜҶеҲ«зҡ„й—®йўҳгҖӮ
и§ЈйҮҠеәҰе’Ңйў„жөӢеәҰеҢәеҲ«дёҚеӨ§гҖӮдҪ жҠҠдёҖ件дәӢи§ЈйҮҠжё…жҷ°дәҶпјҢе’ҢдҪ еҮҶзЎ®йў„жөӢзұ»дјјдәӢ件пјҢйҡҫйҒ“дёҚжҳҜе……еҲҶеҝ…иҰҒд№ҲгҖӮ
еӣҪеҶ…жҠҠжңәеҷЁеӯҰд№ еҪ“й»‘з®ұпјҢи§үеҫ—жІЎе•Ҙз»ҹи®Ўеӣ зҙ пјҢжІЎе•Ҙж•°еӯҰеӣ зҙ вҖҰеҸҚжӯЈзҺ°еңЁеӨ§еӨҡж•°дёҡз•Ңеә”з”Ёзҡ„ж”ҜжҢҒеҗ‘йҮҸжңәгҖҒзҘһз»ҸзҪ‘з»ңе•Ҙзҡ„жЁЎеһӢпјҢеҮҶзЎ®еәҰеҲ°60гҖҒ70%е°ұеҲ°еӨҙдәҶпјҢжҜ”дәәе®¶дј з»ҹеҲҶжһҗдәәе‘ҳзҡ„жүӢе·ҘејәдёҚдәҶеӨӘеӨҡпјҢеҜ№е®һйҷ…дёҡеҠЎжҢҮеҜјж„Ҹд№үдёҚеӨ§пјҢжЁЎеһӢйҖӮеә”жҖ§дёҚејәпјҢжҲ‘дј°и®Ўиҝ‘жңҹйҡҫе…ҚеңЁеӨ§дјҒдёҡеңҲеӯҗйҮҢеҪўжҲҗеҜ№еӨ§ж•°жҚ®гҖҒжңәеҷЁеӯҰд№ зҡ„еҸҚеҜ№иҲҶи®әгҖӮ
ж— д»–пјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№ж•°еӯҰз”Ёзҡ„иҝҳдёҚеҘҪе•ҠгҖӮ
еҫҲжӢ…еҝғпјҢжңәеҷЁеӯҰд№ иҝҷдәӣдёңиҘҝпјҢе°ұеғҸиҝҷдёүеҚҒе№ҙеј•е…Ҙзҡ„е…¶д»–иҪҜжҠҖжңҜпјҡppt еҸҳжҲҗдәҶзңӢеӣҫиҜҙиҜқпјҢcrm еҸҳжҲҗдәҶз”ЁжҲ·иЎЁж јпјҢbiе°ұжҳҜи¶ӢеҠҝеӣҫе’ҢйҘјеӣҫжҹұзҠ¶еӣҫвҖ”жңәеҷЁеӯҰд№ е°ұжҳҜй»‘з®ұи®Ўз®—еҷЁгҖӮ
жҠҖжңҜеҜ№ж•ҲзҺҮзҡ„жҸҗеҚҮдёҚеә”иҜҘжҳҜзәҝжҖ§зҡ„гҖӮдёҚж·ұе…Ҙз ”з©¶иғҢеҗҺзҡ„зҗҶи®әпјҢй—®йўҳеҫҲеӨ§гҖӮ
з»ҹи®Ўе’ҢжңәеҷЁеӯҰд№ ж–№жі•дёҠйғҪжҳҜеҸҜд»Ҙдә’зӣёеҖҹйүҙзҡ„пјҢд№ҹйғҪжңүзҗҶи®әеҸ‘еұ•е’Ңеә”з”Ёе®һи·өгҖӮжң¬иҙЁдёҠжҳҜдёҚеҗҢзҡ„еӯҰ科пјҢеҸӘжҳҜжҒ°еҘҪйғҪеңЁдҪҝз”Ёж•°жҚ®гҖӮ
дёӨдёӘеӯҰ科зҡ„е…ій”®еҢәеҲ«еңЁдәҺжңҚеҠЎеҜ№иұЎгҖӮзҺ°д»Јз»ҹи®Ўзҡ„дё»жөҒдёҖзӣҙжҳҜз§‘з ”е·Ҙе…·пјҢзӣ®зҡ„жҳҜеҲ©з”Ёж•°жҚ®еӣһзӯ”科еӯҰй—®йўҳгҖӮ科еӯҰзҡ„жң¬иҙЁйғҪжҳҜз»ҸйӘҢзҡ„пјҢж•°жҚ®жҳҜйўҳдёӯеә”жңүд№Ӣж„ҸгҖӮ
жңәеҷЁеӯҰд№ жңҖз»Ҳзӣ®зҡ„иҝҳжҳҜе®һзҺ°дёҖзі»еҲ—еҠҹиғҪпјҢеӣһзӯ”科еӯҰй—®йўҳеңЁиҝҷдёӘзі»еҲ—дёӯжҳҜеҫҲе°Ҹзҡ„дёҖз«ҜгҖӮ
дј з»ҹз»ҹи®ЎеӯҰзҡ„з ”з©¶еҜ№иұЎйҖҡеёёжҳҜжҜ”иҫғз®ҖеҚ•зҡ„еҸҳйҮҸпјҢжҜ”еҰӮиҜҙиә«й«ҳпјҢдҪ“йҮҚд»Җд№Ҳзҡ„гҖӮжңәеҷЁеӯҰд№ зҡ„з ”з©¶еҜ№иұЎпјҢйҖҡеёёжҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢжҜ”еҰӮиҜҙжЁЎејҸиҜҶеҲ«гҖӮеҫҲйҡҫжқҘеҜ№е…¶зү№еҫҒиҝӣиЎҢйҮҸеҢ–гҖӮиҖҢдё”еҫҲеӨҡеӯҰд№ жңәеҲ¶жҳҜйқһзәҝжҖ§жңәеҲ¶пјҢеңЁз”Ёдј з»ҹз»ҹи®ЎеӯҰжқҘжҸҸиҝ°зҡ„ж—¶еҖҷпјҢеҫҲйҡҫжүҫеҲ°еҗҲйҖӮзҡ„еәҰ规гҖӮ