еә”иҒҳжҹҗдёҖеІ—дҪҚжІЎиў«еҪ•з”ЁпјҹеҺҹеӣ еҸҜд»ҘжңүеҫҲеӨҡпјҡдёӘдәәиҒҢдёҡжңҹжңӣдёҺеІ—дҪҚдёҚз¬ҰпјӣиғҪеҠӣе°ҡжңӘиҫҫж ҮгҖӮдҪҶдҪ жҳҜеҗҰжғіиҝҮпјҢдҪ иў«жӢ’з»қзҡ„зҗҶз”ұз«ҹжҳҜжҖ§ж јжөӢиҜ•жІЎйҖҡиҝҮпјҒз®—жі•жӯЈеңЁеҪұе“ҚжҲ‘们зҡ„е·ҘдҪңе’Ңз”ҹжҙ»пјҢ其规模гҖҒйҮҚиҰҒзЁӢеәҰпјҢйҡҗз§ҳжҖ§пјҢдҪҝеҫ—иҝҷз§ҚеҪұе“ҚдёҚеҶҚжҷ®йҖҡгҖӮдёҚд»…еҰӮжӯӨпјҢз®—жі•еҮәй”ҷдәҶиҝҳдёҚеҘҪдјёеҶӨпјҢиҖҢдё”з ”з©¶жҳҫзӨәпјҢз®—жі•еҜ№з©·дәәжңүжӯ§и§ҶгҖӮ

Cathy O’Neil жҳҜзәҰзҝ°йҖҠе®һйӘҢе®Өй«ҳзә§ж•°жҚ®з§‘еӯҰ家гҖҒе“ҲдҪӣеӨ§еӯҰж•°еӯҰеҚҡеЈ«гҖҒйә»зңҒзҗҶе·ҘеӯҰйҷўж•°еӯҰзі»еҚҡеЈ«еҗҺгҖҒе·ҙзәіеҫ·еӯҰйҷўж•ҷжҺҲпјҢжӣҫеҸ‘иЎЁиҝҮеӨ§йҮҸз®—жңҜд»Јж•°еҮ дҪ•ж–№йқўзҡ„и®әж–ҮгҖӮд»–жӣҫеңЁи‘—еҗҚзҡ„е…ЁзҗғжҠ•иө„з®ЎзҗҶе…¬еҸёD.E. ShawжӢ…д»»еҜ№еҶІеҹәйҮ‘йҮ‘иһҚеёҲпјҢеҗҺеҠ е…Ҙдё“й—ЁиҜ„估银иЎҢе’ҢеҜ№еҶІеҹәйҮ‘йЈҺйҷ©зҡ„иҪҜ件公еҸё RiskMetricsгҖӮ
еҮ е№ҙеүҚпјҢдёҖдёӘеҸ«Kyle Behmзҡ„е№ҙиҪ»дәәз”ұдәҺиәҒйғҒз—ҮдёӯйҖ”иҫҚеӯҰпјҢзҰ»ејҖд»–е°ұиҜ»зҡ„иҢғеҫ·жҜ”е°”зү№еӨ§еӯҰпјҢиҜҘеӯҰж ЎдҪҚдәҺз”°зәіиҘҝе·һзәід»Җз»ҙе°”гҖӮдёҖе№ҙеҚҠеҗҺпјҢKyleеә·еӨҚдәҶпјҢ并еӣһеҲ°еҸҰдёҖжүҖеӨ§еӯҰ继з»ӯд»–зҡ„еӯҰдёҡгҖӮеңЁйӮЈж—¶пјҢд»–д»ҺдёҖдёӘжңӢеҸӢйӮЈе„ҝдәҶи§ЈеҲ°дёҖд»Ҫе…јиҒҢе·ҘдҪңпјҡеңЁKrogerи¶…еёӮжү“е·ҘпјҢе°Ҫз®Ўе·Ҙиө„зӣёеҪ“дҪҺпјҢдҪҶKyleж„ҝж„ҸеҒҡгҖӮKyleзҡ„жңӢеҸӢжӯЈеҘҪиҫһиҒҢпјҢ并ж„ҝж„Ҹдёәд»–еҒҡжӢ…дҝқгҖӮеҜ№дәҺеғҸKyleиҝҷж ·еӯҰд№ дјҳејӮзҡ„еӯҰз”ҹжқҘиҜҙпјҢжӢ…дҝқе°ұжҳҜиө°иө°еҪўејҸгҖӮ
然иҖҢKyle并没жңүжҺҘеҲ°йқўиҜ•йҖҡзҹҘгҖӮд»–иҜўй—®д»–зҡ„жңӢеҸӢпјҢд»–зҡ„жңӢеҸӢи§ЈйҮҠиҜҙпјҡKyleзҡ„жҖ§ж јжөӢиҜ•з»“жһңжҳҫзӨәпјҢд»–иў«еҲ—е…ҘвҖңзәўзҒҜеҢәвҖқгҖӮKyleеҒҡзҡ„жөӢиҜ•жҳҜз”ұжҖ»йғЁдҪҚдәҺжіўеЈ«йЎҝзҡ„дәәеҠӣиө„жәҗз®ЎзҗҶе…¬еҸёKronosејҖеҸ‘пјҢдҪңдёәдәәеҠӣйҖүжӢ”е‘ҳе·Ҙзҡ„дёҖйғЁеҲҶгҖӮKyleжҠҠиҝҷ件дәӢжғ…е‘ҠиҜүдәҶд»–зҡ„еҫӢеёҲзҲ¶дәІпјҢд»–зҡ„зҲ¶дәІй—®д»–жөӢиҜ•йўҳй—®дәҶдәӣд»Җд№ҲгҖӮKyleиҜҙе’Ңд»–еңЁеҢ»йҷўйҮҢеҒҡзҡ„йўҳзұ»дјјпјҢе°ұжҳҜвҖңдә”еӣ зҙ жЁЎеһӢвҖқиҝҷзұ»зҡ„й—®йўҳгҖӮж №жҚ®еӨ–еҗ‘жҖ§пјҢйҡҸе’ҢжҖ§пјҢи°Ёж…ҺжҖ§пјҢжғ…з»ӘзЁіе®ҡжҖ§д»ҘеҸҠејҖж”ҫжҖ§иҜ„еҲҶгҖӮ

иө·еҲқпјҢз”ұдәҺжөӢиҜ•йўҳдёўжҺүдёҖд»Ҫе·Ҙиө„дҪҺе»үзҡ„е·ҘдҪң并дёҚжҳҜд»Җд№ҲеӨ§й—®йўҳгҖӮRoland Behmйј“еҠұд»–зҡ„е„ҝеӯҗ继з»ӯжүҫгҖӮдҪҶKyleиў«дёҖж¬Ўж¬ЎжӢ’з»қгҖӮд»–еә”иҒҳзҡ„жҜҸдёҖ家公еҸёз”Ёзҡ„жҳҜеҗҢдёҖеҘ—жөӢиҜ•йўҳпјҢеҲ°жңҖеҗҺд»–д№ҹ没收еҲ°дёҖдёӘofferгҖӮ
Roland Behmд№ҹдёҚзҹҘжүҖжҺӘгҖӮеҝғзҗҶеҒҘеә·й—®йўҳдјјд№ҺдёҘйҮҚеҪұе“Қд»–е„ҝеӯҗзҡ„е°ұдёҡгҖӮз ”з©¶д№ӢеҗҺд»–еҸ‘зҺ°пјҡжҖ§ж јжөӢиҜ•йўҳеңЁеӨ§еһӢзҡ„жӢӣиҒҳе…¬еҸёд№Ӣй—ҙйқһеёёжҷ®йҒҚпјҢе°Ҫз®ЎеңЁжі•еҫӢдёҠе№¶ж— е®һйҷ…ж„Ҹд№үгҖӮд»–и§ЈйҮҠиҜҙпјҡеҫҲе°‘жңүдәәжүҫе·ҘдҪңеӣ дёәжөӢиҜ•з»“жһңиў«еҲ—е…ҘзәўзҒҜеҢәгҖӮеҚідҫҝ他们被вҖңзәўзҒҜвҖқдәҶпјҢ他们д№ҹдёҚдјҡжғізқҖеҺ»жүҫеҫӢеёҲгҖӮ
Behmз»ҷеҢ…жӢ¬Home Depotе’ҢWalgreensеңЁеҶ…зҡ„дёғ家公еҸёеҸ‘дәҶйҖҡзҹҘпјҢеҖЎи®®йҖҡиҝҮйӣҶдҪ“иҜүи®јжқҘжҠөеҲ¶жөӢиҜ•жӢӣдәәзҡ„иҝқжі•иЎҢдёәгҖӮеңЁжҲ‘еҶҷиҝҷзҜҮж–Үз« зҡ„ж—¶еҖҷпјҢиө·иҜүи®јд»ҚеңЁи·ҹиҝӣгҖӮжӯӨж¬Ўдәүи®®дё»иҰҒеңЁдәҺKronosзҡ„жөӢиҜ•жҳҜеҗҰжңүеҢ»еӯҰдҫқжҚ®пјӣеҸҰдҫқжҚ®1990е№ҙйўҒеёғзҡ„зҫҺеӣҪж®Ӣз–ҫдәәжі•жЎҲпјҢиҜҘиЎҢдёәжҳҜиҝқжі•зҡ„гҖӮеҰӮжһңиҜүи®јжҲҗеҠҹпјҢжі•йҷўдёҚеҫ—дёҚе°ұжӢӣиҒҳе…¬еҸёжҲ–KnorosжҳҜеҗҰиҝқеҸҚзҫҺеӣҪж®Ӣз–ҫдәәжі•еҒҡеҮәеҲӨеҶігҖӮ
然иҖҢпјҢй—®йўҳдёҚеҶҚжҳҜиҝҷдәӣе…¬еҸёжҳҜеҗҰйңҖиҰҒжӢ…иҙЈиҝҷд№Ҳз®ҖеҚ•пјҢеҹәдәҺеӨҚжқӮж•°еӯҰе…¬ејҸзҡ„иҮӘеҠЁеҢ–зі»з»ҹеңЁеҸ‘иҫҫеӣҪ家йҖҗжёҗжҷ®йҒҚгҖӮ其规模гҖҒйҮҚиҰҒзЁӢеәҰпјҢйҡҗз§ҳжҖ§пјҢдҪҝеҫ—з®—жі•жҠҠдёҖдёӘдәәжҷ®йҖҡзҡ„з”ҹжҙ»еҸҳеҫ—дёҚеҶҚжҷ®йҖҡгҖӮ
жӣҙеӨҡз®—жі•зҹҘиҜҶпјҡwww.yangfenzi.com/tag/suanfa
еӨ§еҸҜдёҚеҝ…иҝҷж ·гҖӮйҮ‘иһҚеҚұжңәеҗҺпјҢж•°еӯҰ家们жүҖи°“зҡ„вҖңйӯ”жі•е…¬ејҸвҖқеҶҚдёҖж¬ЎеёҰжқҘжҲҝиҙ·еҚұжңәпјҢеҜјиҮҙдёҖдәӣйҮҚиҰҒзҡ„йҮ‘иһҚжңәжһ„еҖ’й—ӯгҖӮеҰӮжһңи¶іеӨҹзҗҶжҷәпјҢжҲ‘们е®Ңе…ЁиғҪеӨҹйҳ»жӯўзұ»дјјдәӢ件еҶҚж¬ЎеҸ‘з”ҹгҖӮеҸҜдәӢе®һеҚҙжҳҜпјҢ新科еӯҰжҠҖжңҜеӨ§зғӯпјҢз”ҡиҮіжӢ“еұ•еҲ°жӣҙеӨҡйўҶеҹҹгҖӮ他们дёҚд»…е…іжіЁе…Ёзҗғз»ҸжөҺеёӮеңәпјҢиҝҳе…іжіЁдәәзұ»гҖӮж•°еӯҰ家е’Ңз»ҹи®ЎеӯҰ家жӯЈеңЁз ”究дәәзұ»зҡ„ж¬ІжңӣпјҢиЎҢдёәе’Ңж¶Ҳиҙ№жЁЎејҸгҖӮ他们预жөӢжҲ‘们зҡ„иҜҡе®һеәҰпјҢи®Ўз®—жҲ‘们жҲҗдёәеӯҰз”ҹпјҢе·ҘдәәпјҢжғ…дәәпјҢзҪӘзҠҜзҡ„еҸҜиғҪжҖ§гҖӮ
иҝҷжҳҜеӨ§ж•°жҚ®з»ҸжөҺпјҢеҜ»жұӮеҲ©зӣҠжңҖеӨ§еҢ–гҖӮдёҖдёӘи®Ўз®—жңәзЁӢеәҸеҸҜд»ҘеңЁж•°еҚғд»Ҫз®ҖеҺҶжҲ–з”іиҜ·иЎЁдёӯиҝҗиЎҢпјҢиҺ·еҫ—дёҖд»Ҫз®ҖеҚ•жҳҺдәҶзҡ„иЎЁеҚ•пјҢжңҖдҪіеҖҷйҖүдәәдҪҚдәҺиЎЁеҚ•йҰ–иЎҢгҖӮж—ўзңҒж—¶еҸҲе…¬жӯЈе®ўи§ӮгҖӮдёҚеҸ—дәәзұ»еҒҸи§Ғзҡ„еҪұе“ҚпјҢе°ұжҳҜжңәеҷЁзј–иҜ‘д»Јз ҒгҖӮ2010е№ҙе·ҰеҸіпјҢж•°еӯҰе·Із»Ҹжё—йҖҸеҲ°дәәзұ»зҡ„з”ҹжҙ»дёӯпјҢеҸ—еҲ°дёҖдј—дәәзҡ„йқ’зқҗгҖӮ

еӨ§еӨҡж•°з®—жі•иў«еә”з”ЁеңЁеҘҪзҡ„ж–№йқўгҖӮзӣ®зҡ„жҳҜз”Ёе®ўи§ӮжөӢйҮҸд»Јжӣҝдё»и§ӮеҲӨж–ӯвҖ”вҖ”д№ҹеҸҜиғҪжҳҜжүҫеҮәеӯҰж ЎйҮҢж•ҷеӯҰжңҖе·®зҡ„ж•ҷеёҲпјҢжҲ–йў„жөӢдёҖдёӘзҪӘзҠҜдәҢж¬Ўиҝӣзӣ‘зӢұзҡ„жҰӮзҺҮжңүеӨҡеӨ§гҖӮ
з®—жі•зҡ„и§ЈеҶіж–№жЎҲдё»иҰҒй’ҲеҜ№зңҹжӯЈеӯҳеңЁзҡ„й—®йўҳгҖӮдёҖдёӘеӯҰж Ўзҡ„ж Ўй•ҝдёҚиғҪжҖ»жҳҜй’ҲеҜ№й—®йўҳиҖҒеёҲпјҢеӣ дёә他们д№ҹжҳҜжңӢеҸӢгҖӮжі•е®ҳжҳҜдәәпјҢжҳҜдәәе°ұдјҡжңүеҒҸи§ҒпјҢжңүеҒҸи§Ғе°ұдјҡеҜјиҮҙд»–д»¬ж— жі•еҒҡеҲ°е®Ңе…Ёе…¬е№ігҖӮдёҫдёӘдҫӢеӯҗпјҢеҚҲйӨҗеүҚжі•е®ҳ们дјҡж„ҹеҲ°йҘҘйҘҝпјҢйҘҘйҘҝдјҡ让他们зҡ„еҲӨеҶіжҜ”е№іж—¶жӣҙиӢӣеҲ»гҖӮжүҖд»ҘеҠ ејәдәәжңәзҡ„дёҖиҮҙжҖ§еҚҒеҲҶйҮҚиҰҒпјҢе°Өе…¶жҳҜеҪ“дҪ и§үеҫ—ж–°зі»з»ҹеҗ¬иө·жқҘе°ҡ且科еӯҰгҖӮ
йҡҫзҡ„жҳҜжңҖеҗҺдёҖйғЁеҲҶгҖӮеҸӘжңүе°‘ж•°зҡ„з®—жі•е’ҢиҜ„еҲҶзі»з»ҹз»ҸиҝҮдёҘж јзҡ„科еӯҰжЈҖжөӢпјҢиҖҢдё”жҲ‘们жңүе……еҲҶзҡ„зҗҶз”ұжҖҖз–‘д»–д»¬ж— жі•йҖҡиҝҮжөӢиҜ•гҖӮдёҫдёӘдҫӢеӯҗпјҢиҮӘеҠЁеҢ–ж•ҷеёҲзҡ„жөӢиҜ„жҜҸе№ҙйғҪеҸҜиғҪдёҚеҗҢгҖӮи’Ӯе§ҶВ·е…ӢйҮҢеӨ«еңЁзәҪзәҰеҪ“дәҶ26е№ҙзҡ„дёӯеӯҰиӢұиҜӯж•ҷеёҲпјҢеҚҙд»ҺжңӘж”№еҸҳиҝҮиҮӘе·ұзҡ„ж•ҷеӯҰйЈҺж јгҖӮеҪ“然пјҢеҰӮжһңеҲҶж•°дёҚйҮҚиҰҒпјҢйӮЈжҳҜдёҖеӣһдәӢгҖӮдҪҶдәӢе®һеҚҙжҳҜж•ҷеёҲеҫҖеҫҖйғҪиў«и§ЈйӣҮдәҶгҖӮ
йҷӨдәҶжі•е®ҳзҡ„иЈҒеҶіпјҢжҲ‘们жңүе…¶д»–зҡ„зҗҶз”ұжӢ…еҝ§иў«е‘Ҡиў«еҲӨеҶіжңүзҪӘгҖӮе°Ҷж•°жҚ®жіЁе…Ҙз®—жі•гҖӮе…¶д»–зұ»еһӢзҡ„иҫ“е…ҘеҫҖеҫҖд№ҹдјҡеҮәзҺ°й—®йўҳпјҢиҖҢдё”жӣҙйә»зғҰгҖӮдёҖдәӣжі•е®ҳз”ҡиҮідјҡиҜўй—®иў«е‘Ҡ家йҮҢжҳҜеҗҰжңүдәәжңүеүҚ科пјҢиҝҷжҳҺжҳҫжңүеӨұе…¬е№ігҖӮ
дёҚд»…еҰӮжӯӨпјҢеҰӮжһңдҪ зҡ„дҝЎз”ЁиҜ„еҲҶиҫғдҪҺжҲ–ж— д»»дҪ•дёҚиүҜй©ҫ驶记еҪ•пјҢдҪ еҸҜд»Ҙз”Ёз®—жі•еҶіе®ҡдәӨеӨҡе°‘дҝқйҷ©пјӣжҲ–иҖ…е…ідәҺиҙ·ж¬ҫжқЎж¬ҫжҲ‘们дјҡ收еҲ°е“Әзұ»ж”ҝжІ»дҝЎжҒҜпјҢжҲ‘们йғҪдјҡз”ЁеҲ°з®—жі•гҖӮз®—жі•еҸҜд»Ҙйў„жөӢеӨ©ж°”пјҢ然еҗҺеҶіе®ҡдәә们зҡ„е·ҘдҪңиЎҢзЁӢпјҢеҮҸ少他们йҖҒеӯ©еӯҗеҺ»еҢ»йҷўжҲ–иҖ…еӯҰж ЎеҸҜиғҪжөӘиҙ№зҡ„ж—¶й—ҙгҖӮ
е…¶еҸ—ж¬ўиҝҺзЁӢеәҰдҫқиө–дәҺе®ғ们жҳҜе®ўи§Ӯзҡ„жҰӮеҝөпјҢиҖҢз®—жі•еҪұе“Қж•°жҚ®з»ҸжөҺеҹәдәҺдәәзұ»дјҡзҠҜй”ҷиҜҜгҖӮе°Ҫ管他们被用еңЁеҘҪзҡ„дәӢжғ…дёҠпјҢз®—жі•иҝҳжҳҜдјҡжҠҠдәә们зҡ„еҒҸи§ҒпјҢиҜҜи§Јзј–иҜ‘еҲ°иҮӘеҠЁеҢ–зі»з»ҹйҮҢеҪұе“ҚжҲ‘们зҡ„з”ҹжҙ»гҖӮе°ұеғҸдёҠеёқдёҖж ·пјҢиҝҷдәӣж•°еӯҰжЁЎејҸ并дёҚйҖҸжҳҺпјҢ他们зҡ„е·ҘдҪңеҺҹзҗҶд»…еҜ№ж•°еӯҰ家е’Ңи®Ўз®—жңә科еӯҰ家еҸҜи§ҒгҖӮеҲӨеҶіеҚідҪҝй”ҷдәҶд№ҹдёҚе®№дәүи®®гҖӮеҫҖеҫҖз©·дәәиў«жғ©зҪҡеҺӢиҝ«пјҢеҜҢдәәи¶ҠжқҘи¶ҠеҜҢгҖӮ

ж’ҮејҖе…¬е№іжҖ§е’ҢеҗҲжі•жҖ§зҡ„й—®йўҳпјҢз ”з©¶иЎЁжҳҺпјҢжҖ§ж јжөӢиҜ•е№¶дёҚиғҪеҫҲеҘҪзҡ„йў„жөӢдёҖдёӘдәәзҡ„е·ҘдҪңиЎЁзҺ°гҖӮRoland BehmиЎЁзӨәпјҡжөӢиҜ•зҡ„жңҖеҲқзӣ®зҡ„并дёҚжҳҜжӢӣиҒҳеҘҪе‘ҳе·ҘпјҢе°ұжҳҜдёәдәҶе°ҪеҸҜиғҪеӨҡзҡ„зӯӣжҺүдәәгҖӮ
дҪ еҸҜиғҪи®ӨдёәжҖ§ж јжөӢиҜ•еҫҲеҘҪеҒҡгҖӮе…¶дёӯдёҖдёӘй—®йўҳжҳҜпјҡвҖңз»Ҹеёёдјҡжңүжғ…з»Әзҡ„жіўеҠЁпјҹвҖқдҪ еә”иҜҘеӣһзӯ”вҖңдёҚдјҡвҖқгҖӮеҸҰдёҖдёӘй—®йўҳвҖңеҫҲе®№жҳ“з”ҹж°”пјҹвҖқдҪ д№ҹиҰҒеӣһзӯ”вҖңдёҚдјҡвҖқгҖӮ
дәӢе®һдёҠпјҢдјҒдёҡйҖҡиҝҮиҝҷз§Қж–№ејҸзӯӣйҖүжұӮиҒҢиҖ…д№ҹдјҡйҒҮеҲ°йә»зғҰгҖӮзӣ‘з®Ўжңәжһ„еҸ‘зҺ°пјҢCVSиҝһй”ҒиҚҜеә—йҖҡиҝҮжҖ§ж јжөӢиҜ•иҰҒжұӮдәә们еӣһзӯ”иҜёеҰӮвҖңдәә们еҒҡе“ӘдәӣдәӢи®©дҪ ж„ӨжҖ’вҖқпјҢвҖңжңүдәІеҜҶзҡ„жңӢеҸӢжІЎжңүд»»дҪ•з”Ёпјӣ他们жҖ»жҳҜи®©дҪ еӨұжңӣвҖқзӯүй—®йўҳпјҢйқһжі•зӯӣйҖүеҮәжңүеҝғзҗҶз–ҫз—…зҡ„еә”иҒҳиҖ…гҖӮ
Krogerзҡ„й—®йўҳжӣҙз®ҖеҚ•дёҖдәӣпјҡе“ӘдёҖдёӘеҪўе®№иҜҚжӣҙиғҪжҸҸиҝ°дҪ е·ҘдҪңж—¶зҡ„зҠ¶жҖҒпјҡзӢ¬дёҖж— дәҢиҝҳжҳҜдә•дә•жңүжқЎпјҹеҰӮжһңеӣһзӯ”зӢ¬дёҖж— дәҢпјҢиҜҙжҳҺдҪ й«ҳеәҰејҖж”ҫпјҢиҮӘжҒӢпјӣеҰӮжһңдҪ еӣһзӯ”дә•дә•жңүжқЎпјҢиҜҙжҳҺдҪ иҮӘи§үпјҢиҮӘжҲ‘жҺ§еҲ¶иғҪеҠӣејәгҖӮ
жғіиұЎдёҖдёӢпјҡKyle Behmиў«rogerжӢ’з»қеҗҺеҲ°йәҰеҪ“еҠіе·ҘдҪңгҖӮд»–жҲҗдёәжҳҹзә§йӣҮе‘ҳгҖӮеңЁеҺЁжҲҝз®ЎзҗҶеӣӣдёӘжңҲпјҢдёҖе№ҙеҗҺжӢҝеҲ°ж•ҙдёӘеҲҶеә—зҡ„дё“иҗҘжқғгҖӮиҝҷдёӘж—¶еҖҷпјҢKrogerдјҡдёҚдјҡжңүдәәйҮҚж–°е®Ўи§ҶеҪ“е№ҙзҡ„жҖ§ж јжөӢиҜ•й”ҷзҡ„зҰ»и°ұгҖӮ
е№ёиҝҗзҡ„жҳҜпјҢе№ҝеӨ§жұӮиҒҢиҖ…并жңӘеӣ иҮӘеҠЁеҢ–зі»з»ҹиў«жӢ’з»қгҖӮдҪҶ他们дҫқж—§йқўдёҙиҖ…з®ҖеҺҶиў«зӯӣжҺүжҲ–иҖ…йқўиҜ•зӯүжҢ‘жҲҳгҖӮиҝҷдәӣй—®йўҳдёҖзӣҙеӣ°жү°зқҖе°‘ж•°ж—ҸиЈ”е’ҢеҰҮеҘігҖӮ
规йҒҝиҝҷз§ҚеҒҸи§Ғзҡ„зҗҶжғіж–№жі•е°ұжҳҜдёҚеҜ№з”іиҜ·дәәдёҠзәІдёҠзәҝгҖӮ20дё–зәӘ70е№ҙд»ЈпјҢйҹід№җ家еҸӘиҰҒд»Ҙз”·жҖ§дёәдё»гҖӮеҪ“з§Қж—ҸпјҢеҗҚжңӣдёҚеҶҚйҮҚиҰҒж—¶пјҢеҘіжҖ§йҹід№җ家ејҖе§ӢеҮәзҺ°пјҢиҷҪ然仅еҚ жҖ»ж•°зҡ„еӣӣеҲҶд№ӢдёҖгҖӮ
жұӮиҒҢиҖ…дёҖе®ҡиҰҒи®©йқўиҜ•е®ҳеҜ№иҮӘе·ұзҡ„з®ҖеҺҶиҝҮзӣ®дёҚеҝҳгҖӮеҒҡеҲ°з®ҖжҙҒжңүй’ҲеҜ№жҖ§гҖӮз®ҖеҺҶдёӯеҸҜд»ҘеҢ…жӢ¬д№ӢеүҚд»ҺдәӢзҡ„иҒҢдҪҚпјҲй”Җе”®з»ҸзҗҶпјҢиҪҜ件жһ„жһ¶еёҲпјүпјҢиҜӯиЁҖпјҲжҷ®йҖҡиҜқпјҢJavaпјүпјҢжҲ–иҖ…иҚЈиӘүпјҲжҲҗз»©дјҳејӮпјүгҖӮ
гҖҗжқҘжәҗпјҡгҖҠеҚ«жҠҘгҖӢдҪңиҖ…пјҡCathy O’NeilВ иҜ‘иҖ…пјҡйғӯйӣ…иҸІгҖ‘

В·ж°§еҲҶеӯҗзҪ‘пјҲhttp://www.yangfenzi.comпјү延伸йҳ…иҜ»пјҡ
вһӨВ FacebookејҖжәҗж·ұеәҰеӯҰд№ жЎҶжһ¶TorchnetдёҺи°·жӯҢTensorFlowжңүдҪ•дёҚеҗҢ
вһӨВ ең°е№ізәҝжңәеҷЁдәәжқҺжҳҹе®ҮпјҡеӨҚжқӮзҡ„дёӯеӣҪй©ҫ驶еңәжҷҜпјҢжӯЈжҳҜж·ұеәҰеӯҰд№ зҡ„дјҳеҠҝ
вһӨВ зҷҫеәҰеҗҙжҒ©иҫҫи°Ҳж·ұеәҰеӯҰд№ еұҖйҷҗпјҡAIз»ҸжөҺд»·еҖјзӣ®еүҚд»…жқҘиҮӘзӣ‘зқЈеӯҰд№
вһӨВ Facebookж·ұеәҰеӯҰд№ дё“е®¶пјҡжңӘжқҘзҡ„дәәе·ҘжҷәиғҪжҳҜжҖҺж ·
вһӨВ еј дҪіжҷЁпјҡеӨҙжқЎеҸ·зҡ„иҝҷдёӘе°ҸеҠЁдҪңпјҢжҡҙйңІдәҶд»Ҡж—ҘеӨҙжқЎз®—жі•еҲҶеҸ‘зҡ„зҹӯжқҝ
вһӨВ еҚЎиҖҗеҹәжў…йҡҶеӨ§еӯҰйӮўжіўпјҡдёәдәәе·ҘжҷәиғҪиЈ…дёҠеј•ж“ҺвҖ”еҝҶж јжӢүдё№дёңзҷ»еұұд№Ӣж—…
вһӨВ з”өеӯҗ科жҠҖеӨ§еӯҰдә’иҒ”зҪ‘科еӯҰдёӯеҝғдё»д»»е‘Ёж¶ӣпјҡдҪ д№ҹеҸҜд»ҘжҲҗдёәж•°жҚ®йӯ”жі•еёҲ
вһӨВ еӮ…зӣӣпјҡж·ұеәҰеӯҰд№ жҳҜд»Җд№ҲпјҹдјҒдёҡж ёеҝғз«һдәүеҠӣжӯЈеңЁд»Һз®—жі•иҪ¬еҸҳдёәж•°жҚ®







Yao’s protocol.
гҖҢеҰӮдҪ•и®©дёӨдёӘеҘіеЈ«жҜ”иҫғеҮәи°Ғжӣҙиғ–вҖ”вҖ”еңЁеҘ№д»¬йғҪдёҚжғіжі„жјҸдҪ“йҮҚзҡ„еүҚжҸҗдёӢпјҹгҖҚ
й—®йўҳжҳҜиҝҷж ·зҡ„пјҡеҒҮи®ҫ Alice жүӢдёҠжңүдёҖдёӘйҡҗз§ҒеҮҪж•° fпјҢBob жңүйҡҗз§Ғж•°жҚ® xпјҢйӮЈд№ҲиҜ·дёә他们и®ҫи®ЎдёҖдёӘеҚҸи®®пјҢи®©еҸҢж–№дә’зӣёдёҚз»ҷд»»дҪ•дәәйҖҸйңІиҮӘе·ұйҡҗз§Ғзҡ„жғ…еҶөдёӢпјҢи®Ўз®—еҮә f(x) зҡ„ж•°еҖјпјҹпјҲд»Һ f(x) зҡ„з»“жһңжҺЁж–ӯ x жҲ–иҖ… f дёҚз®—еңЁеҶ…пјӣеҸҢж–№е§Ӣз»ҲйҒөе®ҲеҚҸи®®гҖӮпјү
е®һзҺ°жҳҜиҝҷж ·зҡ„пјҡиҖғиҷ‘дёҖдёӘ k дёӘ bit еҲ°дёҖдёӘ bit зҡ„з®ҖеҚ•еҮҪж•° fпјҲжӣҙеӨҚжқӮзҡ„еҮҪж•°еҸҜд»Ҙз®ҖеҢ–еҲ°иҝҷдёӘж ·еӯҗпјүпјҢalice еҸҜд»Ҙжү“еҮә f зҡ„зңҹеҖјиЎЁжқҘпјҢ然еҗҺеҘ№дә§з”ҹ k+1 еҜ№йҡҸжңәж•°пјҢиЎЁзӨә k дёӘиҫ“е…Ҙ bitпјҲпјүе’Ңиҫ“еҮә bit зҡ„ 0/1 еҖјпјҲпјүгҖӮ
жҺҘзқҖеҘ№жҢүз…§иҝҷдәӣйҡҸжңәж•°еҠ еҜҶзңҹеҖјиЎЁпјҢжҜ”еҰӮеҰӮжһң f(1, 1)=0пјҢеҲҷеҘ№з”ЁдёӨдёӘйҡҸжңәж•°дҪңдёәеҜҶй’ҘеҠ еҜҶдә§з”ҹдёҖдёӘеҜҶж–ҮгҖӮеҘ№еҸҜд»ҘжҠҠеҠ еҜҶзҡ„зңҹеҖјиЎЁиҝһеҗҢиЎЁзӨәз»“жһңзҡ„йҡҸжңәж•°еҸ‘з»ҷ BobгҖӮ
жҺҘдёӢжқҘ Bob йңҖиҰҒжҢүз…§иҮӘе·ұзҡ„ж•°жҚ®пјҲxпјүжүҫ Alice иҰҒ k дёӘйҡҸжңәж•°и§Јз Ғд»–жӢҝеҲ°зҡ„зңҹеҖјиЎЁпјҢзңҹеҖјиЎЁдёӯеҸӘжңүдёҖйЎ№еҸҜд»Ҙиў«и§Јз ҒпјҢи§Јз Ғзҡ„з»“жһңе°ұжҳҜ f(x)пјҢе…¶д»–зҡ„еҲҷж— жі•и§Јз ҒгҖӮ
иҰҒйҡҸжңәж•°зҡ„иҝҮзЁӢжҳҜеҹәдәҺ Oblivious TransferпјҢиҝҷдёӘеҚҸи®®иҰҒжұӮпјҡ
Bob ж №жҚ®иҮӘе·ұзҡ„йҖүжӢ©иҺ·еҸ– Alice дёӨжқЎз§ҒеҜҶж¶ҲжҒҜдёӯзҡ„дёҖжқЎпјҢеҸҰдёҖжқЎеҲҷж— жі•и§ЈеҜҶпјӣ
иҖҢ Alice дёҚиғҪеҫ—зҹҘ Bob зҡ„йҖүжӢ©гҖӮ
иҝҮзЁӢжҳҜпјҡ
Alice з”ҹжҲҗ RSA е…¬й’Ҙ-еҜҶй’ҘеҜ№пјҢеҘ№жҠҠе…¬й’ҘеҸ‘з»ҷ BobпјҢBob ж №жҚ®иҮӘе·ұзҡ„йҖүжӢ©иҺ·еҸ–гҖӮд»ҘдёӢи®Ўз®—еқҮеңЁдёҠиҝӣиЎҢгҖӮ
Alice з”ҹжҲҗдёӨдёӘйҡҸжңәж•°еҸ‘з»ҷ BobгҖӮ
Bob з”ҹжҲҗйҡҸжңәж•° kпјҢи®Ўз®—еҸ‘з»ҷ AliceгҖӮз”ұдәҺ k жҳҜз§ҒеҜҶзҡ„пјҢAlice ж— жі•и§ЈеҜҶеҮә c жқҘгҖӮ
Alice и®Ўз®—пјҢеҸ‘йҖҒз»ҷ BobгҖӮ
Bob и®Ўз®—пјҲеӣ дёәпјүпјҢиҖҢеҜ№дәҺеҸҰдёҖжқЎж¶ҲжҒҜпјҢд»–е°ұж— жі•жҲҗеҠҹи§Јз ҒгҖӮ
жңүе…і @aricatamoyгҖҢдёәд»Җд№ҲдёҚз”ЁеӨ©е№ігҖҚпјҢйӮЈд№ҲиҜ·й—®пјҡдёӨдёӘдәәиҜҘжҖҺд№ҲеҒҡжүҚиғҪдҝқиҜҒеӨ©е№ідёҠйқўжІЎиў«еҠЁиҝҮжүӢи„ҡпјҢжҡ—ең°йҮҢ收йӣҶеҘ№д»¬зҡ„дҪ“йҮҚе‘ўпјҹ
жҲ‘们д»ҺдёҖдёӘз®ҖеҚ•зҡ„з®—жі•йўҳејҖе§ӢиҖғиҷ‘пјҡз»ҷеҮәkдёӘжңүеәҸзҡ„ж•°з»„ пјҢжҜҸдёҖдёӘй•ҝеәҰдёәnпјӣдҪ еҸҜд»ҘеҜ№иҜҘж•°з»„иҝӣиЎҢзәҝжҖ§ж—¶й—ҙзҡ„йў„еӨ„зҗҶпјҢ然еҗҺеӣһзӯ”еҰӮдёӢиҜўй—®пјҡз»ҷеҮәxпјҢеӣһзӯ”жҜҸдёӘж•°з»„дёӯ第дёҖдёӘе°ҸдәҺxзҡ„е…ғзҙ жҳҜд»Җд№ҲгҖӮ
常规зҡ„жғіжі•жҳҜеҜ№дәҺжҜҸдёӘж•°з»„дәҢеҲҶжҹҘжүҫпјҢеӨҚжқӮеәҰжҳҜпјҢиҖҢfractional cascadingйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„ideaе…Ғи®ёжҲ‘们еҒҡеҲ°гҖӮ
иҝӣиЎҢеҰӮдёӢзҡ„йў„еӨ„зҗҶпјҡд»Өпјӣ然еҗҺйҖ’еҪ’жһ„йҖ еҜ№дәҺжҜҸдёҖдёӘпјҢд»Өдёәе°Ҷж•°з»„зҡ„е…ЁйғЁе…ғзҙ дёҺдёӯеҒ¶ж•°дҪҚзҪ®зҡ„е…ғзҙ еҪ’并иҖҢеҫ—еҲ°зҡ„ж–°ж•°з»„гҖӮиҝҷдёӘйў„еӨ„зҗҶеҸҜд»ҘеңЁзәҝжҖ§ж—¶й—ҙеҶ…е®ҢжҲҗпјҢеӣ дёәжҲ‘们еҸ‘зҺ°еҜ№дәҺд»»дҪ• i ж»Ўи¶і гҖӮ
еҗҢж—¶жҜҸдёӘе…ғзҙ и®Ўз®—е·ҰеҸідёӨдёӘжҢҮй’ҲпјҢеҜ№дәҺдёӯзҡ„е…ғзҙ пјҲдёҠдёҖж®өдёӯпјҢе®ғжҳҜйҖҡиҝҮдёӨдёӘжңүеәҸж•°з»„еҪ’并еҫ—еҲ°зҡ„пјүпјҡ
1) еҰӮжһңжқҘиҮӘпјҢеҲҷз»ҙжҠӨе·ҰеҸіз¬¬дёҖдёӘжқҘиҮӘзҡ„е…ғзҙ зҡ„дҪҚзҪ®пјӣ
2) еҰӮжһңжқҘиҮӘпјҢеҲҷз»ҙжҠӨе·ҰеҸіз¬¬дёҖдёӘжқҘиҮӘзҡ„е…ғзҙ зҡ„дҪҚзҪ®пјӣ
иҝҷзұ»жҢҮй’ҲеҸҜд»ҘеңЁзәҝжҖ§ж—¶й—ҙеҶ…йҖҡиҝҮйҖ’жҺЁжұӮеҫ—гҖӮ
еҜ№дәҺиҜўй—®xпјҢйҰ–е…ҲеңЁдёӯдәҢеҲҶ并дҪҝз”ЁжҢҮй’ҲжүҫеҲ°еҜ№еә”зҡ„дҪҚзҪ®гҖӮ然еҗҺеҲ©з”Ёе·ҰеҸіжҢҮй’Ҳp1 p2пјҢжүҫеҲ°еҜ№еә”еңЁдёӯзҡ„дҪҚзҪ®гҖӮз”ұдәҺp1 p2еңЁдёӯдёҖе®ҡеҸӘйҡ”дёҖдёӘе…ғзҙ пјҢж•…жҲ‘们еҸӘиҰҒжү«жҸҸеёёж•°дёӘдҪҚзҪ®е°ұиғҪжүҫеҲ°дёӯзҡ„第дёҖдёӘе°ҸдәҺxзҡ„е…ғзҙ пјҲдё”еҺҹжң¬еұһдәҺпјүгҖӮд»ҘжӯӨзұ»жҺЁпјҢеҫ—еҲ°дәҶзҡ„зӯ”жЎҲеҗҺпјҢеҸӘиҰҒеёёж•°ж—¶й—ҙе°ұиғҪеҫ—еҲ°зҡ„зӯ”жЎҲгҖӮж•…жҖ»зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәпјҢеҚіз¬¬дёҖж¬ЎдҪҝз”ЁдәҶдәҢеҲҶпјҢд№ӢеҗҺжҜҸж¬ЎйғҪжҳҜеёёж•°жҹҘжүҫгҖӮ
иҜҘж–№жі•иҝҳдҪҝз”ЁдәҺrange tree е’Ң half-plane range reporting data structureпјҲз»ҷеҮәе№ійқўдёҠдёҖдәӣзӣҙзәҝпјҢжһ„йҖ дёҖдёӘзәҝжҖ§з©әй—ҙзҡ„ж•°жҚ®з»“жһ„пјҢеҸҜд»ҘеңЁзҡ„ж—¶й—ҙеҶ…еӣһзӯ”дёҖдёӘзӮ№зҡ„дёҠж–№жңүе“ӘдәӣзӣҙзәҝпјҢиҝҷйҮҢmжҳҜзӯ”жЎҲж•°йҮҸпјүзӯүзӯүж•°жҚ®з»“жһ„дёӯжқҘдјҳеҢ–жҺүдёҖдёӘlog nеӣ еӯҗгҖӮ
并жҹҘйӣҶзҡ„и·Ҝеҫ„еҺӢзј©:
并жҹҘйӣҶжҳҜз”ЁжқҘи§ЈеҶійӣҶеҗҲжҹҘиҜў/еҗҲ并问йўҳзҡ„з»Ҹе…ёж–№жЎҲпјҢ
е®ғжһ„йҖ дәҶдёҖдёӘжЈ®жһ—пјҢжЈ®жһ—дёӯжҜҸжЈөж ‘д»ЈиЎЁдёҖдёӘйӣҶеҗҲгҖӮ
еҲқе§Ӣж—¶еҜ№дәҺжүҖжңүзҡ„иҠӮзӮ№и®ҫ x.parent = xпјҢиЎЁзӨәжҜҸдёӘиҠӮзӮ№йғҪжҳҜж ‘ж №пјҢд»ЈиЎЁдёҖдёӘйӣҶеҗҲгҖӮ
жҹҘиҜўдёҖдёӘиҠӮзӮ№жүҖеұһйӣҶеҗҲж—¶пјҢйҖ’еҪ’иҝ”еӣһиҠӮзӮ№жүҖеңЁж ‘зҡ„ж №иҠӮзӮ№:
def find(x):
if x.parent != x:
return find(x.parent)
return x
еҗҲ并时еҸӘйңҖе°ҶдёҖдёӘиҠӮзӮ№зҡ„ж №зҡ„parentжҢҮеҗ‘еҸҰдёҖдёӘж №,
иҝҷж ·е°ұжҠҠдёӨжЈөж ‘еҗҲ并дёәдәҶдёҖжЈө
def union(x,y):
xRoot = find(x)
yRoot = find(y)
xRoot.parent = yRoot
并жҹҘйӣҶжң¬иә«жҳҜдёҖдёӘе·§еҰҷзҡ„и®ҫи®ЎпјҢ
дҪҶйҡҸзқҖдёҚж–ӯзҡ„unionж“ҚдҪңе®№жҳ“еёҰжқҘж ‘ж·ұеәҰиҝҮж·ұпјҢ
еҜјиҮҙж•ҲзҺҮйҷҚдҪҺзҡ„й—®йўҳ(жҹҘиҜўж“ҚдҪңеӨҚжқӮеәҰдёәж ‘зҡ„ж·ұеәҰ)пјҢ
дәҺжҳҜе°ұжңүдёӘзҘһеҘҮзҡ„и·Ҝеҫ„еҺӢзј©зӯ–з•ҘпјҢ
еҸӘеҜ№findз®—жі•иҝӣиЎҢдәҶе°Ҹж”№:
def find(x):
if x.parent != x:
x.parent = find(x.parent)
return x.parent
еўһеҠ дёҖдёӘжӣҙж–°x.parentж“ҚдҪңпјҢ
жҜҸж¬ЎжҹҘиҜўд№ӢеҗҺпјҢд»Һж №еҲ°xзҡ„й•ҝеәҰдёәkзҡ„и·Ҝеҫ„пјҢе°Ҷжӣҙж–°дёәkжқЎй•ҝеәҰдёә1зҡ„и·Ҝеҫ„пјҢ
дҪҝеҫ—并жҹҘйӣҶзҡ„ж“ҚдҪңд»ҺO(n)зӣҙжҺҘйҷҚеҲ°дәҶд»ӢдәҺдёҺзҡ„дёҖдёӘеҖјгҖӮ
е…·дҪ“зҡ„еӨҚжқӮеәҰеҲҶжһҗи§Ғ
Cormen, Thomas H. Introduction to algorithms. MIT press, 2009. иҝҷжң¬д№Ұзҡ„21.3пјҢ
еҸӘдҪҝз”Ёи·Ҝеҫ„еҺӢзј©зҡ„иҜқпјҢ
жү§иЎҢnж¬ЎеҲқе§ӢеҢ–,жңҖеӨҡn-1ж¬ЎunionпјҢдёҺmж¬Ўfindзҡ„жҖ»ж—¶й—ҙпјҢеңЁжңҖеқҸжғ…еҶөдёӢжҳҜ
дёҠиҝ°з« иҠӮйҮҢиҝҳи®Ёи®әдәҶеҸҰеӨ–зҡ„дёҖдәӣдјҳеҢ–пјҢж„ҹе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘиҮӘиЎҢйҳ…иҜ»гҖӮ
еҪ“е№ҙжҳҜеңЁеҒҡдёҖйҒ“йңҖиҰҒеҸҚеӨҚжҹҘиҜўзҡ„йўҳзҡ„ж—¶еҖҷпјҢ
иҮӘе·ұYYеҮәдәҶйӣҶеҗҲжҹҘиҜўзҡ„еҹәжң¬жҖқи·Ҝ(и·ҹеҹәзЎҖ并жҹҘйӣҶе·®дёҚеӨҡпјҢдёҚиҝҮжҳҜйқһйҖ’еҪ’зҡ„)пјҢ
дҪҶжҳҜеҸ—еӣ°дәҺжҜҸж¬ЎжҹҘиҜўиҠӮзӮ№зҡ„O(n)зҡ„ж“ҚдҪңпјҢж— жі•ACпјҢ
然еҗҺжңүдәәе‘ҠиҜүжҲ‘иҝҷйҒ“йўҳз”Ё"并жҹҘйӣҶ"еҸҜд»Ҙи§ЈеҶіпјҢ
жҹҘдәҶдёҖдёӢиө„ж–ҷд№ӢеҗҺпјҢжғҠдёәеӨ©дәә…
дёҚеҫ—дёҚиҜҙеүҚдәәзҡ„жҷәж…§е®һеңЁеӨӘејәеӨ§…
еңЁжңүеҗҜеҸ‘ејҸеҗҲ并зҡ„дјҳеҢ–дёӢжүҚжҳҜackermannеҮҪж•°зҡ„еҸҚеҮҪж•°зҡ„ж—¶й—ҙеӨҚжқӮеәҰ дҪҶеҸӘиҖғиҷ‘и·Ҝеҫ„еҺӢзј©зҡ„жғ…еҶөдёӢд№ҹжҳҜдёҖдёӘжҜ”logNе°Ҹзҡ„еҖје·Із»ҸеҝҳдәҶд№ӢеүҚи®Ёи®әзҡ„й—®йўҳжҳҜе•ҘдәҶпјҢеҰӮжһңиҜҙжҜ”д»Ҙ2дёәеә•е°ҸжІЎй—®йўҳпјҢдҪҶжҳҜеҰӮжһңеҘ—дёҠдәҶThetaпјҢеҘҪеғҸеә•е·Із»ҸжІЎжңүж„Ҹд№үдәҶпјҢеӣ дёәеә•жҳҜеҸҜд»ҘжҚўзҡ„пјҢдәҺжҳҜе°ұдёҖж ·еӨ§дәҶ并жҹҘйӣҶзҡ„и·Ҝеҫ„еҺӢзј©пјҢе®һйҷ…дёҠеҸӘжҳҜзӣёеҪ“дәҺWAMйҮҢзҡ„unificationзҡ„е®һзҺ°гҖӮSPFA (Shortest Path Faster Algorithm)
иҜҙеҲ°еҚ•жәҗжңҖзҹӯи·Ҝеҫ„пјҢеӨ§е®¶еёёеёёдјҡжғіеҲ°зҡ„жҳҜDijkstraз®—жі•пјҲеҸ‘йҹіпјҡ иҚ·е…°иҜӯпјҡ[ЛҲЙӣtsxЙҷr ЛҲКӢibЙҷ ЛҲdЙӣikstra] пјүгҖӮдҪҶжҳҜеҜ№дәҺеёҰжңүиҙҹжқғзҡ„еҚ•жәҗжңҖзҹӯи·Ҝеҫ„зҡ„иҜқпјҢеҸҜиғҪе°ұеҸӘиғҪжұӮеҠ©дәҺBellman Fordз®—жі•дәҶгҖӮдҪҶжҳҜBFз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜпјҢжңүжІЎжңүжӣҙеҝ«зҡ„и§ЈеҶіеҠһжі•е‘ўпјҹ
иҝҷйҮҢе°ұиҰҒд»Ӣз»ҚдёҖдёӢиҘҝеҚ—дәӨйҖҡеӨ§еӯҰзҡ„ж®өеҮЎдёҒдәҺ1994е№ҙеҸ‘иЎЁзҡ„гҖҠе…ідәҺжңҖзҹӯи·Ҝеҫ„зҡ„SPFAеҝ«йҖҹз®—жі•гҖӢдәҶгҖӮSPFAз®—жі•зҡ„еңЁиҜҘзҜҮж–Үз« дёӯзҡ„жңҹжңӣж—¶й—ҙеӨҚжқӮеәҰзҡ„иҜҒжҳҺжҚ®иҜҙжҳҜй”ҷиҜҜзҡ„пјҢдҪҶжҳҜеӣ дёәе…¶жқ°еҮәзҡ„е®һйҷ…иҝҗиЎҢж•ҲзҺҮе’Ңз®ҖеҚ•зҡ„е®һзҺ°иҖҢи®©ACMerйғҪжҺЁеҙҮеӨҮиҮігҖӮ
Dijkstraз®—жі•дёӯзҡ„йҳҹеҲ—дҝқеӯҳзҡ„жҳҜжүҖжңүжңӘзЎ®е®ҡзҡ„зӮ№пјҢжүҖд»ҘйңҖиҰҒжҜҸж¬Ўд»ҺдёӯйҖүеҸ–жңҖзҹӯи·Ҝеҫ„дј°и®ЎжңҖе°Ҹзҡ„йЎ¶зӮ№зҡ„йӮ»иҫ№жқҘиҝӣиЎҢжқҫејӣгҖӮиҖҢSPFAз®—жі•дёӯзҡ„йҳҹеҲ—дҝқеӯҳзҡ„жҳҜжүҖжңүжқҫејӣиҝҮзҡ„иҫ№еҜ№еә”зҡ„йЎ¶зӮ№гҖӮдёҠиҝ°дёӨз§Қз®—жі•дёҺBFз®—жі•зӣёжҜ”пјҢдјҳеҠҝйғҪдҪ“зҺ°еңЁдёҚжҳҜзӣІзӣ®ең°еҜ№жүҖжңүиҫ№иҝӣиЎҢжқҫејӣпјҢж•…еҸҜд»Ҙеҫ—еҲ°жҜ”BFз®—жі•жӣҙеҘҪзҡ„жҖ§иғҪз»“жһңгҖӮ
дҪҶжҳҜDijkstraз®—жі•дёӯзҡ„жңҖзҹӯи·ҜзӣёеҪ“дәҺеңЁдёҖзӮ№дёҖзӮ№вҖңз”ҹй•ҝвҖқпјҢеҰӮжһңеҮәзҺ°иҙҹжқғиҫ№пјҢйӮЈд№ҲдёӘз”ҹй•ҝзҡ„иҝҮзЁӢе°ұйңҖиҰҒз»•еӣһеҺ»пјҢиҝҷеҜ№дәҺDijkstraз®—жі•жқҘиҜҙжҳҜеҒҡдёҚеҲ°зҡ„гҖӮиҖҢBF算法并дёҚжҳҜдҫқйқ иҝҷз§ҚвҖңз”ҹй•ҝвҖқзҡ„еҠһжі•пјҢжүҖд»Ҙе®ғеҸҜд»ҘеҒҡеҲ°иҝҷдёҖзӮ№гҖӮеӣ жӯӨпјҢSPFAдҪңдёәBFз®—жі•зҡ„йҳҹеҲ—дјҳеҢ–зүҲпјҢи§ЈеҶідәҶDijkstraз®—жі•йқўеҜ№иҙҹжқғиҫ№зҡ„й—®йўҳпјҢеҸҲйҒҝе…ҚдәҶBFз®—жі•еңЁжҖ§иғҪдёҠзҡ„еҠЈеҠҝпјҢжҳҜдёҖдёӘе®һйҷ…иҝҗз”ЁдёӯеҫҲеҸ—ж¬ўиҝҺзҡ„з®—жі•гҖӮ
и·іиЎЁпјҡ
з”ұдәҺй“ҫиЎЁдёҚжҳҜcall-by-rankиҖҢжҳҜcall-by-positionзҡ„дёҖзұ»зәҝжҖ§ж•°жҚ®еӯҳеӮЁз»“жһ„гҖӮжүҖд»Ҙй“ҫиЎЁзҡ„жҹҘжүҫжІЎжңүеҠһжі•еә”з”ЁдҫӢеҰӮжңүеәҸж•°з»„дёӯдәҢеҲҶжҹҘжүҫдёҖзұ»зҡ„ж–№жі•пјҢеҸӘиғҪйҖҡиҝҮзәҝжҖ§жҗңзҙўиҝӣиЎҢе…ғзҙ зҡ„жҹҘжүҫгҖӮ
иҖҢеҜ№дәҺдёҖдёӘжңүеәҸй“ҫиЎЁжқҘиҜҙпјҢеҰӮжһңжҲ‘们еҸҜд»ҘеңЁжҹҘиҜўзҡ„ж—¶еҖҷе…ҲйҡҸжңәи·іиҝҮеӨ§йҮҸе…ғзҙ пјҢеҶҚйҖҗжӯҘеҮҸе°‘и·іи·ғзҡ„е№…еәҰпјҢй”Ғе®ҡеҲ°жҲ‘们жңҖз»ҲжҹҘжүҫзҡ„е…ғзҙ дёҠж—¶пјҢйӮЈд№ҲжҲ‘们зҡ„жҗңзҙўжҲҗжң¬е°Ҷдјҡеҫ—еҲ°жһҒеӨ§ең°еҮҸе°‘гҖӮSkip listе°ұжҳҜиҝҗз”ЁиҝҷдёӘеҺҹзҗҶи®ҫи®ЎеҮәжқҘзҡ„гҖӮ
дҫӢеҰӮдёҠеӣҫеҪ“дёӯпјҢеҰӮжһңиҰҒжҗңзҙўж•°еӯ—19зҡ„иҜқпјҢйңҖиҰҒд»Һе·Ұдҫ§еӨҙз»“зӮ№ејҖе§ӢпјҢи·іеҲ°дёӢдёҖдёӘз»“зӮ№21пјҢеҸ‘зҺ°21 > 19еҲҷи·іеӣһеҺ»еҲ°дёӢдёҖеұӮгҖӮдёӢдёҖеұӮдёӢдёҖдёӘз»“зӮ№дёә9пјҢеҶҚеҗҺйқўдёҖдёӘжҳҜ21 > 19пјҢеҸҲи·іеӣһ9并дёӢй’»гҖӮдёӢдёҖдёӘз»“зӮ№дёә17 < 19еҲҷ继з»ӯеҗҺи·іеҲ°21пјҢеҶҚж¬ЎеҸ‘з”ҹ21 > 19пјҢеҲҷеҫҖеӣһи·іеҲ°17并дёӢй’»пјҢжңҖеҗҺеҲ°иҫҫеҫ…жҗңзҙўзҡ„иҠӮзӮ№19зҡ„дҪҚзҪ®дёҠгҖӮ
и·іиЎЁжңүзқҖзұ»дјје№іиЎЎBSTзҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢиҖҢе®һзҺ°жӣҙз®ҖеҚ•пјҢеёёзі»ж•°жӣҙе°ҸпјҢз©әй—ҙеҚ з”Ёжӣҙе°ҸгҖӮиҝҷдәӣзү№зӮ№еёёеёёдҪҝеҫ—е®ғдҪңдёәе№іиЎЎBSTзҡ„жӣҝд»Је“Ғиў«еә”з”ЁгҖӮ
е№іж–№ж №еҖ’ж•°йҖҹз®—жі•пјҡ
еңЁеҲ©з”ЁеҲ°3DеӣҫеҪўжёІжҹ“зҡ„дёҖдәӣжёёжҲҸжҲ–иҖ…зЁӢеәҸеҪ“дёӯпјҢжі•еҗ‘йҮҸзҡ„еҚ•дҪҚеҢ–и®Ўз®—жҳҫеҫ—е°ӨдёәйҮҚиҰҒгҖӮеңЁдёүз»ҙ欧еҮ йҮҢеҫ—з©әй—ҙеҪ“дёӯпјҢжҹҗдёҖеҗ‘йҮҸзҡ„еҚ•дҪҚеҢ–жҳҜжҢҮи®Ўз®—гҖӮе…¶дёӯиЎЁзӨәеҗ‘йҮҸзҡ„дәҢиҢғж•°пјҢд№ҹеҚігҖӮе…¶дёӯи®ҫпјҢзҡ„и®Ўз®—дё»иҰҒжҳҜд№ҳжі•дёҺеҠ жі•пјҢжүҖд»ҘжҖ§иғҪдёҠдёҚдјҡжңүеӨӘеӨ§з“¶йўҲгҖӮиҖҢи®Ўз®—зҡ„ж—¶еҖҷпјҢж•°еҖјжұӮи§Јзҡ„йҖҹеәҰеҰӮдҪ•е°ҶдјҡжһҒеӨ§еҪұе“Қеҗ‘йҮҸеҚ•дҪҚеҢ–зҡ„иҝҗиЎҢж•ҲзҺҮгҖӮе№іж–№ж №еҖ’ж•°йҖҹз®—жі•жӯЈжҳҜдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳиҖҢеҮәзҺ°зҡ„гҖӮ
float Q_rsqrt(float x)
{
float x2 = x * 0.5F;
int i = *(int*)&x; // evil floating point bit level hacking
i = 0x5f3759df – (i >> 1); // what the fuck?
x = *(float*)&i;
x = x * (1.5F – (x2 * x * x)); // 1st iteration
return x;
}
иҝҷдёӘж–№жі•д»Һжң¬иҙЁдёҠжқҘд»Ӣз»Қзҡ„иҜқпјҢе°ұжҳҜе…Ҳиҝ‘дјји®Ўз®—дёҖдёӘеҲқе§ӢеҖјпјҢ然еҗҺеёҰе…ҘзүӣйЎҝиҝӯд»Јжі•жқҘи®Ўз®—жңҖеҗҺзҡ„иҫғдёәзІҫзЎ®зҡ„гҖӮж¶үеҸҠзҡ„дёӯй—ҙеҸҳйҮҸжңүгҖӮйҰ–е…Ҳи®Ўз®—i = *(int*)&xжҳҜдёәдәҶиҺ·еҫ—жө®зӮ№ж•°еҜ№еә”зҡ„ж•ҙж•°иЎЁзӨәгҖӮ然еҗҺеҲ©з”ЁеҺ»жұӮеҮәдёӯеҜ№еә”зҡ„ж•ҙж•°иЎЁзӨәпјҢиҝҷд№ҹе°ұжҳҜдёҠиҝ°жіЁйҮҠвҖңwhat the fuckвҖқеҜ№еә”зҡ„йӮЈеҸҘi = 0x5f3759df – (i >> 1)зҡ„дҪңз”ЁгҖӮ
жұӮеҫ—дәҶж•ҙж•°иЎЁзӨәд»ҘеҗҺпјҢе°ҶиҜҘж•°иҪ¬жҚўеӣһжө®зӮ№ж•°пјҢд№ҹеҚіжұӮеҲ°дәҶзҡ„иҝ‘дјјеҖјгҖӮжңҖеҗҺдёҖеҸҘдҪҝз”ЁзүӣйЎҝиҝӯд»Јжі•еҜ№иҝӣиЎҢдёҖйҒҚиҝӯд»ЈжұӮи§ЈпјҢд№ҹе°ұжҳҜе°ҶдёҠйқўеҫ—еҲ°зҡ„еёҰе…ҘзүӣйЎҝиҝӯд»Јжі•зҡ„е…¬ејҸеҪ“дёӯдҪңдёәеҲқе§ӢеҖји®Ўз®—дёҖйҒҚпјҢжңҖеҗҺеҫ—еҲ°иҫғдёәзІҫзЎ®зҡ„з»“жһңгҖӮ
иҝҷдёӘз®—жі•зҡ„ж ёеҝғең°ж–№еңЁдәҺеҰӮдҪ•еҲ©з”ЁиҝҷдёҖзӯүејҸеҫ—еҲ°дёҺзҡ„е…ізі»пјҢиҖҢиҝҷд№ҹе°ұжҳҜ0x5f3759dfзҡ„йҮҚиҰҒж„Ҹд№үжүҖеңЁгҖӮе…·дҪ“зҡ„ж•°еӯҰжҺЁеҜјд»ҘеҸҠдёӯй—ҙзҡ„вҖңйӯ”ж•°вҖқ0x5f3759dfжҳҜжҖҺд№Ҳз®—еҮәжқҘзҡ„еҸҜд»ҘеҸӮи§Ғз»ҙеҹәзҷҫ科Fast inverse square rootгҖӮ
зҸ жҺ’еәҸпјҡ
зҸ жҺ’еәҸдҪңдёәдёҖз§ҚиҮӘ然жҺ’еәҸз®—жі•пјҢеңЁи®Ўз®—жңәеҪ“дёӯжІЎжңүеҠһжі•жүҫеҲ°дёҖз§ҚеҫҲеҘҪзҡ„е®һзҺ°жқҘиҝӣиЎҢжЁЎжӢҹпјҢдҪҶжҳҜпјҢ并且еҸӘиғҪдёәжӯЈж•ҙж•°еәҸеҲ—иҝӣиЎҢжҺ’еәҸгҖӮдҪҶжҳҜе…¶дёӯзҡ„жҖқи·ҜеҚҙзңҹзҡ„з®—жҳҜдёҖз§ҚеҘҮжҠҖж·«е·§дәҶгҖӮ
еҜ№дёӘжӯЈж•ҙж•°иҝӣиЎҢжҺ’еәҸзҡ„иҜқпјҢжҲ‘们е°ұйҖ ж №жҹұеӯҗгҖӮ然еҗҺеҜ№дәҺжҜҸдёҖдёӘжӯЈж•ҙж•°пјҢжҲ‘们е°ұжҠҠе®ғжғіиұЎжҲҗдёӘзҸ еӯҗгҖӮжҲ‘们е°ҶиҝҷдёӘзҸ еӯҗеҲҶеҲ«дёІеңЁеңЁз¬¬1ж №гҖҒ第2ж №гҖҒвҖҰвҖҰз¬¬ж №жҹұеӯҗдёҠгҖӮ
жүҖжңүж•°йғҪдёІе®ҢдәҶд»ҘеҗҺпјҢе°Ҷиҝҷж №жҹұеӯҗеһӮзӣҙж”ҫзҪ®дёӢжқҘпјҢжүҖжңүзҸ еӯҗйғҪйҡҸйҮҚеҠӣдёӢиҗҪпјҢ然еҗҺжҜҸиЎҢдёҠпјҲдёҚжҳҜжҜҸж №жҹұеӯҗдёҠпјүзҡ„зҸ еӯҗж•°пјҢе°ұжҳҜжңҖеҗҺзҡ„жҺ’еәҸз»“жһңгҖӮ
Duff’s Deviceпјҡ {
{
д»ҺдёҖдёӘжҢҮй’Ҳfromеҗ‘еҸҰдёҖдёӘжҢҮй’ҲtoжӢ·иҙқcountдёӘеӯ—иҠӮпјҢдҪ жү“з®—жҖҺд№ҲеҒҡпјҹ
жӯЈеёёзҡ„еҒҡжі•жҳҜ
do {
*to++ = *from++;
} while(–count > 0);
иҝҷж®өд»Јз ҒеҪ“дёӯпјҢиҝҷеҸҘ–count > 0зҡ„дјҡиў«еҲӨж–ӯcountж¬ЎгҖӮ
йӮЈд№Ҳзңҹзҡ„йңҖиҰҒеҲӨж–ӯиҝҷд№ҲеӨҡж¬Ўд№Ҳпјҹи®©жҲ‘们жқҘзңӢзңӢDuff’s Deviceзҡ„е®һзҺ°жҳҜжҖҺд№ҲеҒҡзҡ„
void send(int *to, int *from, int count)
{
int n = (count + 7) / 8;
switch (count %
case 0 : do { *to++ = *from++;
case 7 : *to++ = *from++;
case 6 : *to++ = *from++;
case 5 : *to++ = *from++;
case 4 : *to++ = *from++;
case 3 : *to++ = *from++;
case 2 : *to++ = *from++;
case 1 : *to++ = *from++;
} while (–n > 0);
}
}
иҝҷж®өд»Јз Ғе·§еҰҷең°е°Ҷswitchе’ҢwhileжқӮзі…еңЁдёҖиө·пјҢдёҚд»…жҜҸж¬Ў8дёӘеӯ—иҠӮиҝӣиЎҢжӢ·иҙқпјҢиҖҢдё”еҜ№жң«е°ҫдёҚи¶і8дёӘеӯ—иҠӮзҡ„йғЁеҲҶеҒҡдәҶзІҫе·§зҡ„еӨ„зҗҶпјҢйҖҡиҝҮеҫӘзҺҜеұ•ејҖеҮҸе°‘дәҶеҫӘзҺҜеҲӨж–ӯзҡ„ж¬Ўж•°пјҢд»ҺиҖҢдјҳеҢ–дәҶжҖ§иғҪгҖӮ
е°ҫйҖ’еҪ’пјҡ
з»ҷдҪ дёҖдёӘеҚ•й“ҫиЎЁзҡ„еӨҙз»“зӮ№пјҢи®©дҪ еҫ—еҲ°иҝҷжқЎй“ҫиЎЁзҡ„й•ҝеәҰжҳҜеӨҡе°‘пјҢиҰҒжұӮз”ЁйҖ’еҪ’иҝӣиЎҢзј–еҶҷзҡ„иҜқпјҢдҪ дјҡжҖҺд№ҲеҒҡе‘ўпјҹ
жӯЈеёёзҡ„еҒҡжі•жҳҜ
int linked_list_length(node *head)
{
if (head->next == NULL)
return 0;
else
return linked_list_length(head->next) + 1;
}
иҝҷж®өд»Јз Ғзҡ„й—®йўҳеңЁдәҺд»Җд№Ҳе‘ўпјҹеҰӮжһңй“ҫиЎЁйқһеёёй•ҝзҡ„иҜқпјҢжҲҗзҷҫдёҠеҚғж¬Ўзҡ„йҖ’еҪ’еҺӢж Ҳе°ҶдјҡиҖ—е°Ҫж Ҳз©әй—ҙпјҢйҖ жҲҗж ҲжәўеҮәгҖӮеҰӮжһңжҲ‘们дҪҝз”Ёе°ҫйҖ’еҪ’зҡ„иҜқпјҢе°ұеҸҜд»Ҙиҝҷж ·
int linked_list_length(node *head, int len)
{
if (head->next == NULL)
return len;
else
return linked_list_length(head->next, len + 1);
}
е°ҫйҖ’еҪ’дёҺжҷ®йҖҡйҖ’еҪ’жңҖеӨ§зҡ„еҢәеҲ«еңЁдәҺпјҢж•ҙдёӘйҖ’еҪ’и°ғз”ЁеҚ жҚ®дәҶж•ҙдёӘreturnеҗҺйқўзҡ„йғЁеҲҶгҖӮз”ұдәҺе®ғеңЁж•ҙдёӘж–№жі•зҡ„жңҖеҗҺжүҚиў«и°ғз”ЁпјҢйӮЈд№Ҳд№ӢеүҚеҮҪж•°еҺӢж Ҳдҝқз•ҷзҡ„жүҖжңүеұҖйғЁеҸҳйҮҸзӯүзӯүдҝЎжҒҜйғҪдёҚеҪұе“ҚдёӢдёҖж¬ЎйҖ’еҪ’и°ғз”ЁпјҢжүҖд»Ҙжң¬ж¬Ўж–№жі•дёӯж ҲеҶ…зҡ„дҝЎжҒҜеҸҜд»Ҙиў«жё…з©әпјҢи®©дёӢж¬Ўи°ғз”ЁеҸҜд»ҘйҮҚеӨҚдҪҝз”Ёиҝҷж®өж Ҳз©әй—ҙгҖӮ
жүҖд»Ҙе°ҫйҖ’еҪ’зҡ„жң¬иҙЁпјҢе…¶е®һе°ұжҳҜе°Ҷиҝҷж¬ЎйҖ’еҪ’ж–№жі•еҪ“дёӯзҡ„еҝ…иҰҒдҝЎжҒҜпјҢдј йҖ’еҲ°дёӢж¬ЎйҖ’еҪ’еҪ“дёӯпјҢд»ҺиҖҢдҝқиҜҒreturnеҗҺйқўжҳҜдёҖдёӘе®Ңж•ҙзҡ„йҖ’еҪ’еҮҪж•°и°ғз”ЁиҖҢдёҚжҳҜдёҖдёӘиЎЁиҫҫејҸгҖӮ
дәҢзә§жҢҮй’ҲеҲ йҷӨеҚ•еҗ‘й“ҫиЎЁдёӯз»“зӮ№пјҡ
иҝҷдёӘеҲ©з”ЁдәҢзә§жҢҮй’ҲпјҲpointers-to-pointersпјүдјҳеҢ–еҚ•еҗ‘й“ҫиЎЁеҪ“дёӯзҡ„еҲ йҷӨж“ҚдҪңпјҢжҳҜLinusеңЁLinus Torvalds Answers Your QuestionsдёҠе°ұд»Җд№ҲжүҚжҳҜзңҹжӯЈзҡ„вҖңcore low-level kind of codingвҖқжүҖжҸҗеҮәзҡ„дёҖдёӘдҫӢеӯҗгҖӮеҪ“дҪ иҰҒеҶҷдёҖдёӘеҚ•еҗ‘й“ҫиЎЁеҪ“дёӯж №жҚ®жҹҗдёӘзү№е®ҡжқЎд»¶жқҘеү”йҷӨз»“зӮ№зҡ„еҮҪж•°пјҢдҪ дјҡжҖҺд№ҲеҶҷе‘ўпјҹ
жӯЈеёёзҡ„еҒҡжі•жҳҜ
typedef bool (*remove_fn)(const node *n);
void remove_if(node *head, remove_fn rm)
{
for (node *prev = NULL, *curr = head; curr != NULL; )
{
node* next = curr->next;
if (rm(curr))
{
if (prev) prev->next = next;
else head = next;
delete curr;
}
else
prev = curr;
curr = next;
}
}
е…¶дёӯremove_fnжҳҜдёҖдёӘеҮҪж•°жҢҮй’Ҳзұ»еһӢпјҢиЎЁзӨәеҲӨж–ӯжҳҜеҗҰеҲ йҷӨз»“зӮ№зҡ„жқЎд»¶гҖӮиҝҷйҮҢзҡ„е®һзҺ°йҖҡиҝҮз»ҙжҠӨдёҖдёӘprevжҢҮй’ҲжқҘиҝӣиЎҢз»“зӮ№зҡ„еҲ йҷӨпјҢйңҖиҰҒеҲӨж–ӯprevжҳҜеҗҰдёәNULLжқҘзЎ®е®ҡеҪ“еүҚеҲ йҷӨзҡ„з»“зӮ№жҳҜдёҚжҳҜеӨҙз»“зӮ№гҖӮиҝҷз§Қе®һзҺ°ж–№ејҸжҳҜиў«LinusжүҖе”ҫејғзҡ„вҖңThis person doesnвҖҷt understand pointersвҖқгҖӮйӮЈд№ҲдҪҝз”ЁдәҢзә§жҢҮй’ҲеҜ№дёҠиҝ°д»Јз ҒиҝӣиЎҢдјҳеҢ–зҡ„иҜқпјҢе°ұжҳҜ
void remove_if(node **head, remove_fn rm)
{
for (node **curr = head; *curr; )
{
node *entry = *curr;
if (rm(entry))
{
*curr = entry->next;
delete entry;
}
else
curr = &entry->next;
}
}
дёҠиҝ°д»Јз Ғзҡ„йҮҚзӮ№еңЁдәҺдәҢзә§жҢҮй’ҲcurrгҖӮеҫӘзҺҜејҖе§Ӣж—¶пјҢдәҢзә§жҢҮй’ҲcurrжҢҮеҗ‘еӨҙз»“зӮ№зҡ„жҢҮй’ҲгҖӮеҰӮжһңеӨҙз»“зӮ№жҳҜйңҖиҰҒеҲ йҷӨзҡ„з»“зӮ№зҡ„иҜқпјҢ*curr=entry->nextе°ұзӣёеҪ“дәҺ*head=(*head)->nextпјҢд№ҹеҚідҝ®ж”№еӨҙз»“зӮ№зҡ„жҢҮй’ҲжҢҮеҗ‘дёӢдёҖдёӘз»“зӮ№гҖӮ
еҰӮжһңиҰҒеҲ йҷӨзҡ„иҠӮзӮ№дёҚжҳҜеӨҙз»“зӮ№зҡ„иҜқпјҢз”ұдәҺcurrжҳҜйҖҡиҝҮ&entry->nextжӣҙж–°зҡ„пјҢжүҖд»ҘиҰҒжӯӨж—¶currжҢҮеҗ‘иҰҒеҲ йҷӨзҡ„иҠӮзӮ№зҡ„дёҠдёҖдёӘиҠӮзӮ№зҡ„nextжҢҮй’ҲпјҢиҖҢentryжҢҮеҗ‘зҡ„жҳҜиҰҒеҪ“еүҚиҰҒеҲ йҷӨзҡ„жҢҮй’ҲпјҢжӯӨж—¶*curr=entry->nextе°ұзӣёеҪ“дәҺprev->next=entry->nextпјҢд»ҺиҖҢе®ҢжҲҗеҪ“еүҚиҠӮзӮ№зҡ„еҲ йҷӨгҖӮ
еҰӮдҪ•еҲӨж–ӯдёҖдёӘй“ҫиЎЁдёӯжңүй—ӯзҺҜпјҹ
еҰӮжһңжңүй—ӯзҺҜпјҢеҰӮдҪ•зЎ®е®ҡй—ӯзҺҜзҡ„иө·е§ӢиҠӮзӮ№пјҹ
иҝҷдёӘй—®йўҳжҳҜжҲ‘们数жҚ®з»“жһ„иҜҫзҡ„иҖҒеёҲ(еҗҢж—¶иҝҳжҳҜеӯҰж ЎACMйҳҹж•ҷз»ғ)еңЁиҜҫе ӮдёҠи®©жҲ‘们讨и®әз ”з©¶зҡ„пјҢж•ҙж•ҙи®Ёи®әдәҶдёҖиҠӮиҜҫеҗ§гҖӮе…¶еҹәжң¬зҹҘиҜҶд»…д»…жҳҜй“ҫиЎЁпјҢдҪҶиҝҷдёӘй—®йўҳеҚҙйқһеёёжңүж„ҸжҖқгҖӮеӨ§е®¶дёҚж–ӯи®Ёи®әдёӯпјҢеҗ„з§Қж–№жі•и¶ҠжқҘи¶ҠдјҳеҢ–пјҢжңҖеҗҺзҡ„жңҖдҪіз®—жі•зңҹжҳҜи®©дәәзңјеүҚдёҖдә®гҖӮ
еҗҺжқҘе®һд№ йқўиҜ•ж—¶пјҢдёҖйқўиҖғе®ҳеңЁй—®дәҶдёҖе Ҷз®ҖеҚ•зҡ„жҺ’еәҸз®—жі•еҗҺиҜҙиҰҒй—®жҲ‘дёҖдёӘйҡҫдёҖзӮ№зҡ„й—®йўҳпјҢ然еҗҺе°ұй—®дәҶдёҠиҝ°зҡ„第дёҖдёӘй—®йўҳгҖӮжҲ‘иҜҙдәҶзӯ”жЎҲеҗҺйЎәдҫҝиҝҳиҜҙдәҶ第дәҢдёӘй—®йўҳзҡ„зӯ”жЎҲгҖӮд»–дёҖи„ёжғҠ讶ең°й—®жҲ‘жҳҜдёҚжҳҜйҒҮеҲ°иҝҮпјҢжҲ‘е‘ҠиҜүд»–жҲ‘们дёҠиҜҫи®ІиҝҮвҖҰ
з°Ўе–®гҖҒз„ЎйҒһжӯёпјҢдҝқйҡңжҷӮй–“иӨҮйӣңеәҰ != x)
!= x) = djs[djs
= djs[djs  ], x = djs
], x = djs  ;
;
int find(x)
{
while (djs
djs
return x;
}
`Variant` segment tree (еӯёеҗҚдёҚжҳҺ)еҚҖй–“иЎЁзӨә
еҫһ[0,n)й–Ӣе§ӢпјҢжҜҸж¬ЎдҪҝз”Ё floor((l+h)/2) зҡ„еҚҖй–“жҠҳеҚҠзӯ–з•ҘгҖӮеҰӮ [0,5) еҫ—еҲ° [0,2) [2,5) [0,1) [1,2) [2,3) [3,5) [3,4) [4,5)гҖӮ
еҸҜд»Ҙз”ЁеҰӮдёӢжҳ е°„жі•еүҮзөҰеҚҖй–“з·Ёиҷҹпјҡ
int id(int l, int h)
{
return l == h-1 ? 2*n+l : l+h;
}
зөҰе®ҡ xпјҢжһҡиҲүж»ҝи¶і (y & x) == y зҡ„ y
for (int y = x; ; y = y-1 & x) {
// process y
if (! y) break;
}
жүҖжңүmдҪҚ01дёІдёӯжһҡиҲүеҢ…еҗ«mmеҖӢ1зҡ„
int large = (1<<mm)-1 << m-mm, g = (1<<m)-1, h;
for(;;) {
// process g
if (g == large) break;
h = (g | g-1) + 1;
g = h | (h&-h)-1 >> __builtin_ctz(g)+1;
}
32-1-__builtin_clz(x) иЁҲз®— floor(log2(x))
Topological sort
degreeеҗ‘йҮҸдёӯжёӣе°‘зҲІ0зҡ„е…ғзҙ еҸҜд»Ҙзө„з№”жҲҗдёҖеҖӢжЈ§
for (i=0; i<n; i++) )
) ++
++ )
) = top, top = i;
= top, top = i; )
) )
) = top, top = u;
= top, top = u;
for (auto j: e
d
top = -1
for (i=0; i<n; i++)
if (! d
d
while (top != -1) {
v = top
top = d[top]
// process v
for (auto u: e
if (! –d
d
}
Sieve of Eratosthenes жұӮ Euler phi == i)
== i) = phi
= phi  /i*(i-1);
/i*(i-1);
iota(phi, phi+n, 0);
for (i=2; i<n; i++)
if (phi
for (j=i; j<n; j+=i)
phi
Fenwick tree (жҲ‘е–ңжӯЎдёӢжЁҷеҫһ0й–Ӣе§Ӣ) += y;
+= y;
void add(int x, int y)
{
for (; x < n; x |= x+1)
fenwick
}
// sum of [0,x)
void getSum(int x)
{
int s = 0;
for (; x; x &= x-1)
s += fenwick[x-1];
return s;
}
еҜҰйҡӣдёҠ add еҸҜд»ҘеҫһйҒһеўһи®ҠзҲІйҒһжёӣпјҢиҖҢ getSum еҫһйҒһжёӣи®ҠзҲІйҒһеўһ
void add(int x, int y)
{
for (x++; x; x &= x-1)
fenwick[x-1] += y;
}
// sum of [x,n)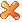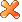 ;
;
void getSum(int x)
{
int s = 0;
for (; x < n; x |= x+1)
s += fenwick
return s;
}
Binary heap ж №ж“ҡйҚөжҹҘдҪҚзҪ®
make_heap push_heap pop_heap зӯүпјҢйҮҚијү operator= еҶҚж №ж“ҡ this жҢҮйҮқжӣҙж–°йҚөеҲ°дҪҚзҪ®зҡ„жҳ е°„гҖӮеҜҰйҡӣдёҠжІ’е•Ҙз”ЁпјҢиҮӘе·ұеҜҰзҸҫжӣҙж–№дҫҝ
еңЁйӮЈеҖӢNOIP/NOIдёҚиғҪз”ЁSTLзҡ„е№ҙд»ЈпјҢжҲ‘зҗўзЈЁдәҶжҖҺйәјйҮҚијүж“ҚдҪңз¬ҰдҪҝ stl_set.h ж”ҜжҢҒзҜҖй»һsizeдҝЎжҒҜгҖӮдҪҶSTLеҜҰзҸҫзҡ„зҜҖй»һжҢҮйҮқдҝ®ж”№жҺЁжё¬дёҚжҳҜеҸҜзө„еҗҲзҡ„пјҢеҫҲйӣЈеҜҰзҸҫгҖӮ
TreapйЎһдјјSplayз¶ӯиӯ·dynamic sequence
еңЁжҹҘи©ўеҚҖй–“е…©з«ҜжҸ’е…ҘдҪҺpriorityзҡ„зҜҖй»һпјҢдҪҝеҫ—еҚҖй–“е°ҚжҮүзҡ„зҜҖй»һеҪўжҲҗдёҖжЈөеӯҗжЁ№дёҰиў«жҸҗеҚҮеҲ°жҺҘиҝ‘ж №зҡ„дҪҚзҪ®пјҢеҸҜд»ҘзӣҙжҺҘи®ҖеҮәmonoidе’ҢдҝЎжҒҜгҖӮ
йҖҷжЁЈеҒҡдёҚжё…жҘҡжҷӮй–“иӨҮйӣңеәҰжңғи®ҠжҲҗд»ҖйәјжЁЈгҖӮ
Top-down Splay tree
top-down Splay treeеҸҜд»ҘйЎҚеӨ–з¶ӯиӯ·monoidеҹҹпјҢleft/right spineиЎЁзӨәзҡ„зҜҖй»һеҰӮжһңдёҠдёӢеҖ’зҪ®еүҮеҸҜд»ҘзңҒеҺ»parentжҢҮйҮқпјҢеҸғиҰӢ<fxr.watson.org: sys/vm/vm_map.c>
еҰӮжһңжҳҜgroupзҡ„и©ұжңүзЁҚз°Ўе–®зҡ„еҒҡжі•пјҢз„ЎйңҖеҖ’зҪ®spineдёҠзҡ„зҜҖй»һпјҡ<http://www.link.cs.cmu.edu/link/ftp-site/splaying/top-down-size-splay.c>
Wavelet tree
дҝ—зЁұвҖңеҠғеҲҶжЁ№вҖқгҖӮж–ҮзҚ»дёӯжҸҸиҝ°Wavelet treeжҷӮйҖҡеёёд»Ҙеӯ—жҜҚиЎЁдҪңзҲІеҠғеҲҶдҫқж“ҡпјҢжҜҸеҖӢеҚҖй–“е°ҚжҮүдёҖеҖӢеӯ—жҜҚиЎЁеҚҖй–“пјҢ當еҸӘеү©дёҖеҖӢеӯ—жҜҚжҷӮеҠғеҲҶзөҗжқҹжҲҗзҲІи‘үеҚҖй–“
競иіҪдёӯеёёд»Ҙrank(е°Қж–јзӣёзӯүе…ғзҙ пјҢе…ҲеҮәзҸҫзҡ„rankе°Ҹ)зҲІеҠғеҲҶдҫқж“ҡпјҢйҖҷжЁЈеҜҰзҸҫжҜ”ијғз°Ўе–®гҖӮеҰӮжһңд»Ҙеӯ—жҜҚиЎЁзҲІеҠғеҲҶдҫқж“ҡзҡ„и©ұпјҢWavelet matrixжҖ§иғҪжӣҙй«ҳ(жёӣе°‘дәҶselect rankж“ҚдҪңж•ё)
Strongly-connected components
Kosaraju’s algorithmгҖҒTarjan’s SCC algorithmгҖҒGabow’s SCC algorithmз”ўз”ҹSCCзҡ„й ҶеәҸжҳҜtopological orderжҲ–йҖҶеәҸзҡ„пјҢзӣёе°Қ於收縮SCCеҫҢеҫ—еҲ°зҡ„ең–иҖҢиЁҖ
жұӮ2-SATзҡ„д»»дёҖж–№жЎҲжҷӮпјҢж №ж“ҡ x иҲҮ ~x жүҖеңЁSCCзҡ„жЁҷиҷҹеӨ§е°ҸдҫҶеҲӨе®ҡ x еҸ– true/falseгҖӮжҺЎз”Ё Tarjan’s SCC algorithm еҸӘйңҖиҰҒдёҖж¬ЎDFS
Stack migration
競иіҪдёӯеҒ¶жңүдҪҝз”ЁDFSзӯүйҒһжӯёз®—жі•жңғжЈ§жәўеҮәзҡ„жғ…жіҒ
Windows PEеҸҜеҹ·иЎҢж–Ү件еҸҜд»Ҙй…ҚзҪ®жЈ§еӨ§е°Ҹ(`#pragma comment(linker, "/STACK:16777216")`)пјҢLinux x86/64еҸҜд»ҘйҒ·з§»esp/rsp
const size_t STACK_SIZE = 16*1024*1024; // ulimit -s => usually 8 MiB
char st[STACK_SIZE];
void callee()
{
int g;
scanf("%d", &g);
printf("g=%dn", g);
}
void with_stack()
{
static long sp;
asm volatile("movq %%rsp, %0nt"
"movq %1, %%rspnt"
: "=g"(sp) : "g"(st+STACK_SIZE) : "memory");
callee();
asm volatile("movq %0, %%rspnt"
: "=g"(sp) :: "memory");
}
int main()
{
with_stack();
}
е°Қз·ЁиӯҜеҷЁзһӯи§ЈеҫҲе°‘пјҢжҹҗдәӣз”ЁдҫӢеҸҜиғҪйңҖиҰҒдҝ®ж”№йҖҷеҖӢд»Јзўј
жҜ”еҰӮжҹҗдәӣжғ…жіҒдёӢжЈ§жңғжЁҷиЁҳзҲІеҸҜеҹ·иЎҢпјҢжӯӨжҷӮйңҖиҰҒжЁҷиЁҳ`st`жүҖеңЁsegmentж¬ҠйҷҗеҸҜеҹ·иЎҢзӯүгҖӮ
Shunting-yard algorithm
operator-precedence grammarзҡ„зү№ж®Ҡжғ…еҪўгҖӮеёёиҰӢеҜҰзҸҫжңғеҲ¶е®ҡдёҖејө |ж“ҚдҪңз¬Ұ|^2 зҡ„иЎЁж јгҖӮ
жҜҸеҖӢж“ҚдҪңз¬Ұжңү in-stack е’Ң incoming е…©зЁ®зӢҖж…ӢпјҢеҲӨж–·е„Әе…Ҳзҙҡж №ж“ҡ in-stack priority е’Ң incoming priority еҚіеҸҜпјҢеҸҜд»ҘжҠҠ |ж“ҚдҪңз¬Ұ|^2 зҡ„иЎЁж јз°ЎеҢ–зҲІ 2*|ж“ҚдҪңз¬Ұ|
е„Әе…ҲзҙҡзӣёзӯүжҷӮд»ЈиЎЁе…©з«ҜзҲІ terminal symbol зҡ„ production зҡ„ reductionпјҢжҜ”еҰӮ `(` иҲҮ `)` зҡ„жҠөж¶Ҳ
Tarjan’s offline lowest common ancestors algorithm
еҸҜд»ҘеңЁиЁҲз®—LCAзҡ„еҗҢжҷӮиҷ•зҗҶжЁ№дёҠи·Ҝеҫ‘зҡ„monoidжҹҘи©ў
int find(int x)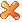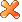 == x) return x;
== x) return x;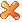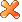 ;
;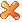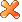 = find(y);
= find(y); = mconcat(info
= mconcat(info  , info
, info  ); // sum of info
); // sum of info  & info
& info 
 ;
;
{
if (djs
int y = djs
djs
info
return djs
}
void tarjan(int u) = u; // MakeSet
= u; // MakeSet = …… // sum of path from u to djs
= …… // sum of path from u to djs 
 == -1
== -1 == -1
== -1 = u
= u = calculated info of edge (u,v)
= calculated info of edge (u,v) `
` , info
, info  )
)
{
djs
info
for each query `q` with one endpoint at `u`
v = other endpoint of `q`
if djs
lca = find(v)
qq[lca] << (query_id, u, v, lca)
for each edge `e` with one endpoint at `u`
v = other endpoint of `q`
if djs
tarjan(v)
djs
info
for each LCA result (query_id, x, y, u) of `qq
find(x)
find(y)
result of query_id = mconcat(info
}
жңүдёӨжң¬д№ҰеҜ№гҖҠеҲқзӯүз®—жі•гҖӢеҪұе“ҚжңҖеӨ§гҖӮдёҖжң¬жҳҜChris Okasakiзҡ„гҖҠPurely functional data structureгҖӢеҸҰеӨ–дёҖжң¬жҳҜгҖҠз®—жі•еҜји®әгҖӢгҖӮеҶҷдҪңиҝҮзЁӢдёӯиҝҳеҸӮиҖғдәҶдёҖдәӣе…¶д»–д№ҰзұҚпјҢеҢ…жӢ¬Knuthзҡ„гҖҠи®Ўз®—жңәзЁӢеәҸи®ҫи®ЎиүәжңҜгҖӢпјҢRichard Birdзҡ„гҖҠPearls of functional algorithm designгҖӢпјҢBentleyзҡ„гҖҠзј–зЁӢзҸ зҺ‘гҖӢд»ҘеҸҠдёҖдәӣи®әж–ҮгҖӮ
дёҚи¶іпјҡ
еҶҷиҝҷжң¬д№Ұзҡ„е…ӯе№ҙдёӯпјҢжҲ‘жҖ»жҳҜжғіиө·жі•еӣҪж•°еӯҰеӨ©жүҚдјҪзҪ—з“ҰжңҖеҗҺеҶҷзҡ„йӮЈеҸҘиҜқпјҡвҖңжҲ‘жІЎжңүж—¶й—ҙдәҶпјҒвҖқпјҢжҲ‘еҺҹи®ЎеҲ’з”Ё10е№ҙеҶҷе®Ңиҝҷжң¬д№ҰпјҢз»“жһңжҸҗеүҚдәҶ4е№ҙгҖӮиҝҷж ·зҡ„д»Јд»· еҫҲеӨ§гҖӮдёәдәҶйҒҝе…Қзҝ»иҜ‘пјҢиҝҮж»ӨвҖңеҷӘеЈ°вҖқпјҢжҲ‘зӣҙжҺҘз”ЁиӢұж–ҮеҶҷдҪңгҖӮз”ұдәҺдёҚжҳҜnative speakerпјҢд№Ұдёӯзҡ„иӢұж–ҮиҜӯжі•е’ҢжӢјеҶҷйҡҫе…Қиҙ»з¬‘еӨ§ж–№гҖӮдёәдәҶиө¶ж—¶й—ҙпјҢproof readingиў«еҺӢзј©пјҢи®ёеӨҡз»“и®әйҮҮеҸ–дәҶвҖңжӢҝжқҘдё»д№үвҖқпјҢжІЎжңүиҝӣиЎҢдёҘж јзҡ„ж•°еӯҰиҜҒжҳҺгҖӮдёҖдәӣз« иҠӮзҡ„иҜҫеҗҺд№ йўҳд№ҹжІЎжңүз»ҷеҮәзӯ”жЎҲгҖӮ
жңӘжқҘпјҡ
зҗҶжғіжғ…еҶөдёӢпјҢдёҖжң¬дёҘиӮғзҡ„з®—жі•д№Ұеә”иҜҘеңЁзЁіе®ҡгҖҒе®Ҫжқҫзҡ„зҺҜеўғдёӢзІҫйӣ•з»ҶзҗўгҖӮеҸҜжҳҜеңЁзӨҫдјҡеү§зғҲеҸ‘еұ•зҡ„д»ҠеӨ©пјҢеңЁж—Ҙж–°жңҲејӮзҡ„дёӯеӣҪпјҢеңЁдәәд»¬д№ жғҜеҝ«йӨҗиҖҢдёҚеҶҚдә«еҸ—еӨ§йӨҗзҡ„ еҝ«иҠӮеҘҸз”ҹжҙ»дёӯпјҢеңЁеҫ®еҚҡгҖҒеҫ®дҝЎеҸ–д»Јж–Үз« гҖҒд№ҰдҝЎзҡ„жүӢжңәзҪ‘з»ңеӨ§жҪ®дёӢпјҢиҝҷж ·зҡ„зҗҶжғізҺҜеўғж №жң¬дёҚеӯҳеңЁгҖӮжңӘжқҘдёҚеҸҜйў„зҹҘгҖӮеҜ№дәҺгҖҠеҲқзӯүз®—жі•гҖӢиҝҷжң¬д№ҰпјҢејҖж”ҫз»ҷзӨҫеҢәжҳҜжңҖеҘҪзҡ„йҖүжӢ©гҖӮйңҖиҰҒеҒҡзҡ„е·ҘдҪңеҫҲеӨҡпјҡ
* зҝ»иҜ‘дёӯж–ҮзүҲ
* зӨҫеҢәproof readingе’ҢreviewпјҢдҝ®жӯЈеҶ…е®№дёҠзҡ„й”ҷиҜҜе’ҢиӢұж–ҮдёҠзҡ„дёҚи¶і
* жҸҗдҫӣдёҖжң¬д№ йўҳйӣҶ
* иЎҘи¶іж•°еӯҰиҜҒжҳҺ
* йҮҮз”ЁејәеӨ§зҡ„ж•°еӯҰе·Ҙе…·пјҢеҜ№еҪўејҸеҢ–зҡ„з®—жі•иҝӣиЎҢеҲҶжһҗ
дёҖдәӣж•°жҚ®пјҡ
гҖҠеҲқзӯүз®—жі•гҖӢй»„йҮ‘еҲҶеүІ0.618зүҲжң¬пјҢеҺҶж—¶6е№ҙпјҢеңЁgithubдёҠжҖ»е…ұжҸҗдәӨ1680ж¬ЎcommitгҖӮе…Ёд№Ұ600еӨҡйЎөпјҢ19дёҮеӯ—пјҲwordпјүгҖӮ2дёҮ2еҚғиЎҢзӨәдҫӢд»Јз ҒгҖӮ
дҝқжҠӨпјҡ
гҖҠеҲқзӯүз®—жі•гҖӢеңЁGNU FDLи®ёеҸҜеҚҸи®®дёӢеҸ‘еёғпјҢжүҖжңүд»Јз ҒеңЁGNU GPLv3еҚҸи®®дёӢеҸ‘еёғгҖӮ
зңӢгҖҠз®—жі•еҜји®әгҖӢпјҢйҮҚеӨҚзңӢгҖӮеңЁз•ҘиҝҮеӨҚжқӮеәҰж‘ҠиҝҳеҲҶжһҗзҡ„жғ…еҶөдёӢпјҢеҲқдёӯж•°еӯҰеҹәзЎҖи¶іеӨҹеј„жҳҺзҷҪз»қеӨ§йғЁеҲҶеҶ…е®№дәҶгҖӮ
еҗҢж ·жҺЁиҚҗзҡ„иҝҳжңүгҖҠж•°жҚ®з»“жһ„дёҺз®—жі•еҲҶжһҗгҖӢпјҢд»ҘеҸҠйӮ“дҝҠиҫүиҖҒеёҲзҡ„MOOCиҜҫзЁӢгҖҠж•°жҚ®з»“жһ„гҖӢгҖӮ
з®—жі•еҜји®әиҝҷжң¬д№ҰпјҢд»ҺеҲқдёүеҲ°й«ҳдәҢпјҢиҮӘе·ұж–ӯж–ӯз»ӯз»ӯзҡ„зңӢдәҶдёүе№ҙж—¶й—ҙгҖӮеҜ№дәҺз®—жі•еҜји®әпјҢиҮӘе·ұзҡ„йҳ…иҜ»и·Ҝеҫ„жҜ”иҫғжӣІжҠҳиү°йҡҫпјҢиҝҷжҳҜеҪ“ж—¶иҮӘе·ұеҸӘжңүдёӯеӯҰеҹәзЎҖзҡ„зјҳж•…гҖӮеҘҪеңЁз®—жі•еҜји®ә еҒҸеҗ‘дәҺеҹ№е…»жһ„йҖ жҖ§зҡ„жҖқз»ҙпјҢи§ЈйўҳгҖҒиҜҒжҳҺжҠҖе·§жҳҜвҖңз®—жі•зҡ„ж–№ејҸвҖқиҖҢйқһвҖңж•°еӯҰзҡ„ж–№ејҸвҖқпјҢеӣ иҖҢеҫ—д»ҘеӢүејәиҜ»дәҶдёӢжқҘгҖӮдёҚиҝҮе№іж‘ҠеҲҶжһҗиҝҷж ·зҡ„йғЁеҲҶе°ұж— иғҪдёәеҠӣдәҶпјҢйҖүжӢ©и·іиҝҮгҖӮ
еҫӘзҺҜдёҚеҸҳејҸжҳҜз®—еҜјжңҖејҖз«Ҝзҡ„еҶ…е®№пјҢд№ҹжҳҜз®—жі•жӯЈзЎ®жҖ§иҜҒжҳҺжңҖйҮҚиҰҒзҡ„й’ҘеҢҷгҖӮжң¬иҙЁдёҠпјҢеҫӘзҺҜдёҚеҸҳејҸжҳҜз®—жі•еҪ’зәіиҜҒжҳҺзҡ„еҪўејҸеҢ–гҖӮзҗҶи§Јз®—еҜјдёӯжҜҸдёӘз®—жі•еҫӘзҺҜдёҚеҸҳејҸзҡ„иҜҒжҳҺиҝҮзЁӢпјҢе°ұжҳҜеңЁзҗҶи§Јз®—жі•зҡ„иҝҗиЎҢеҺҹзҗҶгҖӮ
з®—еҜјйҳ…иҜ»дёҚйңҖиҰҒеҫҲж·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҲдҪ зңӢжҲ‘иҝҷж ·зҡ„еҲқдёӯз”ҹд№ҹиғҪеӢүејәзңӢпјүгҖӮеңЁзңӢй«ҳж–Ҝж¶Ҳе…ғLUPеҲҶи§Јзҡ„ж—¶еҖҷпјҢжҲ‘еҸӘжҳҜйҖҡиҝҮйҷ„еҪ•иЎҘд№ дәҶдёҖдёӢзҹ©йҳөзҡ„еҹәжң¬зҹҘиҜҶпјҢ然еҗҺе°ұеҸҜд»ҘзңӢеүҚйқўзҡ„LUPеҲҶи§Јз®—жі•дәҶгҖӮзҗҶи§Јз®—жі•зҡ„жӯЈзЎ®жҖ§жҳҜзӣёеҜ№е®№жҳ“зҡ„пјҢзҗҶи§Јз®—жі•и®ҫи®Ўзҡ„зІҫеҰҷпјҢеҸҚжҺЁз®—жі•и®ҫи®Ўзҡ„иҝҮзЁӢйҡҫд№ӢеҸҲйҡҫгҖӮ
д»Јз Ғе®һзҺ°жҳҜжңҖеҘҪзҡ„еӯҰд№ иҝҮзЁӢгҖӮеӣ дёәз«һиөӣзҡ„зјҳж•…жҲ‘дҪҝз”Ёзҡ„жҳҜcпјҢеҪ“然дҪ д№ҹеҸҜд»Ҙз”ЁpythonгҖҒjavaжҲ–иҖ…brainf**kпјҲйӣҫпјүгҖӮе•ғе®ҢдәҢеҚҒеӨҡйЎөзҡ„дәҢйЎ№е ҶпјҢ并且 ж•ІеҮәд»Јз ҒжҲҗеҠҹиҝҗиЎҢеҗҺпјҢеҪ“ж—¶зҡ„жҲ‘еҙ©жәғзҡ„еҸ‘зҺ°иҝҳжңүдёүеҚҒеӨҡйЎөзҡ„Fibonacciе ҶеңЁеҗҺйқўзӯүзқҖжҲ‘гҖӮдёәдәҶи®°дҪҸFibonacciе Ҷзҡ„и®ҫи®Ўз»ҶиҠӮпјҢжҲ‘йҮҚеӨҚеҶҷдәҶ20еӨҡйҒҚ д»ҘиҮідәҺй—ӯзқҖзңјзқӣйғҪиғҪеҶҷеҮәжқҘпјҢз»“жһңеҸ‘зҺ°еңЁз«һиөӣдёӯж №жң¬з”ЁдёҚеҲ°пјҢжҲ‘们жңүеҘҪз”ЁеҸҲеҘҪеҶҷзҡ„Pairing heapгҖӮе°Ҫз®ЎеҰӮжӯӨпјҢFibonacciе Ҷзҡ„иҜҒжҳҺз®ҖеҚ•иҖҢзӣҙи§ӮпјҢз®—жі•и®ҫи®Ўжңүи¶Јеҫ—еҫҲгҖӮ
е°қиҜ•дҝ®ж”№дјҳеҢ–з®—жі•еҜји®әдёҠзҡ„д»Јз ҒгҖӮеңЁзј–еҶҷзәҝжҖ§и§„еҲ’еҚ•зәҜжҖ§ зҡ„д»Јз Ғж—¶пјҢжҲ‘еҸ‘и§ү(n+m)*(n+m)зҡ„зҹ©йҳөејӮеёёжөӘиҙ№пјҢзЁҚдҪңжҖқиҖғеҸ‘зҺ°еҸҜд»Ҙж”№жҲҗn*mзҡ„зҹ©йҳөеҠ дёҠеҮ дёӘйҷ„еҠ еҗ‘йҮҸдҝЎжҒҜпјӣиҝӣдёҖжӯҘпјҢеҜ№е…Ёе№әжЁЎзҡ„жғ…еҶөпјҢеҸҜд»ҘдҪҝз”ЁзЁҖз–Ҹ зҹ©йҳөеёёи§Ғзҡ„дјҳеҢ–ж–№жі•вҖ”вҖ”й“ҫиЎЁжӣҝд»ЈиЎҢеҗ‘йҮҸгҖӮеҮ дёӘдјҳеҢ–иҝҮеҗҺпјҢжҲ‘з»ҲдәҺеҸҜд»ҘеңЁз«һиөӣе…Ғи®ёзҡ„ж—¶й—ҙгҖҒз©әй—ҙгҖҒзј–з ҒйҮҸеҶ…еҶҷдёҖдёӘйқһеӨҡйЎ№ејҸзҡ„зәҝжҖ§и§„еҲ’еҚ•зәҜеҪўз®—жі•дәҶгҖӮ
еҝ« йҖҹеӮ…йҮҢеҸ¶еҸҳжҚўд№ҹжҳҜдёӘжңүи¶Јзҡ„дҫӢеӯҗгҖӮжҲ‘们йғҪзҹҘйҒ“пјҢеҝ«йҖҹеӮ…йҮҢеҸ¶еҸҳжҚўзҡ„и®Ўз®—жҳҜеңЁеӨҚж•°еҹҹдёҠзҡ„пјҢиҖҢи®Ўз®—жңәдёӯеӨҚж•°зҡ„ж•°еҖјзІҫеәҰдјҡеҜјиҮҙFFTеңЁеҗ‘йҮҸжҜ”иҫғй•ҝзҡ„ж—¶еҖҷдёўеӨұдҝЎжҒҜгҖӮеҗҺ жқҘеӯҰиҝҮж•°и®әйғЁеҲҶпјҢеҸ‘зҺ°еӨҚж•°еҹҹжҳҜеҸҜд»Ҙз”ұдёҖдәӣзү№е®ҡзҡ„жЁЎж•ҙж•°иҝҗз®—еҸ–д»Јзҡ„пјҢдәҺжҳҜFFTе°ұеҸҜд»Ҙиў«з”ЁжқҘеҠ йҖҹй«ҳзІҫеәҰд№ҳжі•гҖӮеҶҚеҗҺжқҘпјҢеҸ‘и§үиҝҷдёӘж–№жі•еҸ«еҒҡеҝ«йҖҹж•°и®әеҸҳжҚўгҖӮ
жҜҸдёҖз« зҡ„иҜҫеҗҺд№ йўҳжҳҜжЈҖйӘҢжң¬з« еҶ…е®№жҳҜеҗҰжҺҢжҸЎзҡ„еҮҶеҲҷгҖӮеҰӮжһңиҜҫеҗҺд№ йўҳжңүдәҢеҲҶд№ӢдёҖд»ҘдёҠж— жі•зӢ¬з«Ӣи§ЈеҶіпјҢдёҚеҰЁйҮҚж–°йҳ…иҜ»жң¬з« еҶ…е®№пјҢз»ҷж·ұе…ҘжҖқиҖғз•ҷдәӣж—¶й—ҙгҖӮз»“еҗҲд№ йўҳйҳ…иҜ»з« иҠӮд№ҹжҳҜеҸҜиЎҢзҡ„гҖӮпјҲжҲ‘и®°еҫ—зҪ‘дёҠеҸҜд»ҘжҗңеҲ°йғЁеҲҶз« иҠӮзҡ„зӯ”жЎҲпјү
иҜҙеҲ°еә•пјҢз®—жі•еҜји®әеҸӘжҳҜжң¬еҹәзЎҖж•ҷжқҗпјҢе…¶дёӯж— и®әж•°жҚ®з»“жһ„гҖҒеӣҫи®әпјҢиҝҳжҳҜеҠЁжҖҒ规еҲ’пјҢиҙӘеҝғз®—жі•пјҢйғҪеҸӘжҳҜеҹәзЎҖеҶ…е®№гҖӮеҰӮжһңзңӢдёҚжҮӮпјҢдҪ йңҖиҰҒйҮҚж–°зңӢдёҖдёӢиҝҷдёҖз« пјӣеҰӮжһңдёҖзӣҙзңӢдёҚжҮӮпјҢдҪ йңҖиҰҒйҮҚж–°д»ҺеӨҙиҜ»иҝҷжң¬д№ҰпјӣеҰӮжһңдҪ еҸ‘и§үиғҪзңӢжҮӮдәҶпјҢиҜҙжҳҺйҖҡиҝҮеҹ№е…»пјҢдҪ д№ еҫ—дәҶжһ„йҖ жҖ§зҡ„гҖҒвҖңз®—жі•вҖқзҡ„жҖқиҖғиғҪеҠӣгҖӮ
жҜ”еҰӮи®ІеҲ°еҝ«йҖҹжҺ’еәҸпјҢеҫҲеӨҡд№ҰеҸҜиғҪи®ІдәҶеҝ«йҖҹжҺ’еәҸзҡ„еҺҹзҗҶе°ұе®ҢдәҶгҖӮдҪҶиҝҷжң¬д№Ұе°ұзӣҙжҺҘи®ІдәҶеҺҹе§Ӣзҡ„еҝ«йҖҹжҺ’еәҸеҸҜд»Ҙж”№иҝӣзҡ„ең°ж–№пјҡ1. еңЁе°Ҹж•°з»„дёҠпјҢеҲҮжҚўеҲ°жҸ’е…ҘжҺ’еәҸпјӣ2. дёүеҸ–ж ·еҲҮеҲҶпјӣ3. дёүеҗ‘еҲҮеҲҶзҡ„еҝ«йҖҹжҺ’еәҸгҖӮ
дјҳе…ҲйҳҹеҲ—жҖҺд№Ҳе’ҢжҺ’еәҸз®—жі•жүҜдёҠе…ізі»е‘ўпјҹе…¶е®һдјҳе…ҲйҳҹеҲ—е°ұжҳҜеҸҜд»Ҙз”Ёе ҶжҺ’еәҸжқҘе®һзҺ°пјҢе ҶжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰе’Ңеҝ«йҖҹжҺ’еәҸжҳҜдёҖж ·зҡ„пјҢдҪҶжҳҜе®һйҷ…дёӯдёәд»Җд№Ҳе ҶжҺ’еәҸзҡ„иҝҗиЎҢж—¶й—ҙиҰҒжҜ”еҝ«йҖҹжҺ’еәҸеӨҡе‘ўпјҹеӣ дёәиҝҷе’ҢCPUзҡ„Cacheе‘ҪдёӯзҺҮжңүе…ізі»пјҢе ҶжҺ’еәҸдёҚз¬ҰеҗҲз®—жі•иҝҗиЎҢзҡ„еұҖйғЁжҖ§еҺҹеҲҷ
иҝҳжҜ”еҰӮд№Ұдёӯ2.5иҠӮпјҢи®ІдәҶжҺ’еәҸз®—жі•зҡ„е®һйҷ…з”ЁйҖ”гҖӮ
иҝҷжң¬д№ҰдёҚе…үе‘ҠиҜүдҪ з®—жі•зҡ„еҺҹзҗҶпјҢиҝҳе‘ҠиҜүдҪ з®—жі•зҡ„з”ЁйҖ”гҖӮ
иҝҷжҳҜжҲ‘еңЁд»Ҡе№ҙжұӮиҒҢиҝҮзЁӢдёӯйқўиҜ•зҡ„ж—¶еҖҷиў«й—®еҲ°зҡ„пјҢеӣ дёәд№ӢеүҚеҫҲе°‘жҺҘи§ҰStreamingзҡ„з®—жі•пјҢеңЁеҗ¬еҲ°иҝҷдёӘйўҳзӣ®зҡ„ж—¶еҖҷиў«жғҠе‘ҶдәҶпјҢж №жң¬дёҚиғҪзҗҶи§Јпјҡ
з»ҷдёҖдёӘStreamingзҡ„DataпјҢжңӘзҹҘй•ҝеәҰпјҢиҰҒжұӮеңЁStreamingз»“жқҹеҗҺиҝ”еӣһNдёӘDataпјҢдё”жҳҜзӯүжҰӮзҺҮзҡ„гҖӮ
еңЁеҗ¬еҲ°иҝҷдёӘй—®йўҳзҡ„ж—¶еҖҷз®ҖзӣҙжғҠе‘ҶдәҶгҖӮеҰӮжһңStreamingй•ҝеәҰе·ІзҹҘдёәLпјҢеҪ“然еҜ№дәҺжҜҸдёҖдёӘDataпјҢжҲ‘з”ҹжҲҗдёҖдёӘN/Lзҡ„жҰӮзҺҮеҚіеҸҜгҖӮдҪҶжҳҜй•ҝеәҰжңӘзҹҘпјҢд№ҹеҚіжҰӮзҺҮжңӘзҹҘпјҢжҖҺд№ҲеҸҜиғҪеңЁDataжқҘзҡ„ж—¶еҖҷеҲӨж–ӯиҰҒдёҚиҰҒдҝқз•ҷиҝҷдёӘDataпјҢиҝҳиғҪдҝқиҜҒжҳҜзӯүжҰӮзҺҮзҡ„вҖҰвҖҰзҷҫжҖқдёҚеҫ—е…¶и§ЈгҖӮ
дәӢеҗҺдёҖз•Әз ”з©¶пјҢжүҚеҸ‘зҺ°дәҶиҝҷзұ»з®—жі•пјҢз®—жі•д№Ӣз®ҖеҚ•д»ӨдәәжғҠеҸ№пјҡ
йҰ–е…Ҳдҝқз•ҷеүҚNдёӘDataпјҢеҜ№дәҺеҗҺйқўжқҘзҡ„Dataд»ҘN/iзҡ„жҰӮзҺҮйҖүжӢ©жҳҜеҗҰдҝқз•ҷпјҢiдёәеҪ“еүҚDataеәҸеҸ·пјҢдҝқз•ҷзҡ„иҜқеңЁеҺҹжқҘдҝқз•ҷзҡ„Nзҡ„DataдёӯйҡҸжңәеү”йҷӨдёҖдёӘгҖӮжңҖеҗҺиҝ”еӣһиҝҷNзҡ„еҚіеҸҜгҖӮ
иҜҒжҳҺд№ҹеҫҲе®№жҳ“пјҢеҘҮеҰҷеҫ—ең°ж–№еңЁдәҺеңЁи®Ўз®—жҰӮзҺҮзҡ„ж—¶еҖҷпјҢеҮәзҺ°дәҶеҫҲй•ҝзҡ„пјҢеҸҜд»ҘеүҚеҗҺдёҠдёӢдёҚж–ӯзәҰжҺүзҡ„еҲҶејҸгҖӮзӣёдә’зәҰеҺ»д№ӢеҗҺеү©дёӢзҡ„жҰӮзҺҮеҲҡеҘҪжҳҜN/LпјҢLдёәжҖ»й•ҝеәҰгҖӮз®ҖзӣҙзҫҺеҰҷжһҒдәҶпјҒ
жҳҫ然иҝҷзұ»з®—жі•д№ҹйқһеёёжңүз”ЁпјҢеӣ дёәеңЁе®һйҷ…й—®йўҳдёӯдјҡеҮәзҺ°еӨ§йҮҸйңҖиҰҒеңЁStreamingзҡ„ж•°жҚ®дёӯиҝӣиЎҢSampleпјҢдёәдёӢдёҖжӯҘеӨ„зҗҶж•°жҚ®еҒҡеҮҶеӨҮзҡ„жғ…еҪўгҖӮиҖҢиҝҷз«ҹ然жңүдёҖдёӘO(L)зҡ„з®—жі•пјҢзңҹжҳҜеӨӘжғҠиүідәҶпјҒ
йҰ–е…ҲжҳҜKMPе’ҢдёҺд№Ӣзӣёе…ізҡ„ACиҮӘеҠЁжңәпјҲAho-Corasick automatonпјҢеҲҡжҺҘи§Ұд»ҘдёәжҳҜиҮӘеҠЁACжңәпјүпјҢе…¶жҖқжғіе’Ңж•ҲзҺҮзңҹзҡ„еҫҲжғҠиүігҖӮ
然еҗҺжҳҜеҝ«йҖҹеӮ…йҮҢеҸ¶еҸҳжҚўпјҲFFTпјүпјҢеҸҜд»Ҙд»Ҙзҡ„еӨҚжқӮеәҰи®Ўз®—nж¬ЎеӨҡйЎ№ејҸд№ҳжі•гҖӮ
е…¶ж¬ЎжҳҜжү©еұ•ж¬§еҮ йҮҢеҫ—з®—жі•пјҢж•°и®әйўҳжңҖеёёз”Ёз®—жі•дәҶпјҢжұӮд№ҳжі•йҖҶе…ғгҖҒи§ЈдёҖж¬ЎдёҚе®ҡж–№зЁӢи¶…зә§еҘҪз”ЁпјҢиҖҢдё”д»Јз ҒеҫҲзҹӯеҫҲеҘҪи®°гҖӮ
еҶҚж¬ЎжҳҜеҝ«йҖҹе№ӮеҸ–жЁЎз®—жі•пјҢзҗҶи§Јд№ӢеҗҺд»Јз ҒеҫҲеҘҪеҶҷпјҢиҖҢдё”ж•ҲзҺҮеҫҲй«ҳгҖӮkйҳ¶зҹ©йҳөзҡ„nж¬Ўж–№еӨҚжқӮеәҰд»…дёәпјҲдёҚз”Ёstrassenжі•еҠ йҖҹзҡ„жғ…еҶөпјүгҖӮ
жңҖеҗҺеҶҚжҺЁиҚҗдёҖдёӘеҘҪз”ЁдҪҶдёҚе®Ңе…ЁдёҘи°Ёзҡ„з®—жі•пјҡMiller-Rabinзҙ ж•°жөӢиҜ•з®—жі•гҖӮйқһеёёеҝ«иҖҢдё”й”ҷиҜҜзҺҮеҫҲдҪҺе•ҠпјҒ
иҮӘйҖӮеә”иҫӣжҷ®жЈ®е…¬ејҸпјҢеҜ№дёүзӮ№иҫӣжҷ®жЈ®е…¬ејҸйҖ’еҪ’и°ғз”Ёзҡ„з§ҜеҲҶз®—жі•пјҢд»Јз ҒдёҚеҲ°20иЎҢпјҢи§ЈеҶіжүҖжңүдёҖз»ҙе®ҡз§ҜеҲҶй—®йўҳгҖӮ
ж—ӢиҪ¬еҚЎеЈіз®—жі•еҸҜд»ҘеңЁOпјҲNпјүж—¶й—ҙеҶ…жұӮеӨҡиҫ№еҪўзӣҙеҫ„гҖӮ
еҝ«йҖҹжҺ’еәҸз®—жі•д№ҹжҳҜйқһеёёеҘҪз”Ёзҡ„пјҢ#include<stdlib.h>然еҗҺи°ғеә“жҳҜжҜ”иөӣдёӯжүҖжңүиҰҒжҺ’еәҸзҡ„ең°ж–№зҡ„еӨ„зҗҶж–№жі•пјҢеҝ«йҖҹжҺ’еәҸз®—жі•и®©жҲ‘жғҠиүізҡ„ең°ж–№жҳҜжҲ‘еҺ»зңҒеӣҫд№ҰйҰҶзңӢи§ҒдёӨдёӘеҝ—ж„ҝиҖ…йңҖиҰҒжҠҠиҝҳеӣһжқҘзҡ„дёҖе Ҷд№ҰжҢүйЎәеәҸе…Ҙжһ¶пјҢз®ЎзҗҶе‘ҳеӨ§еҰҲз»ҷ他们ж•ҷзҡ„ж—¶еҖҷиҜҙпјҡвҖңдҪ е…ҲеңЁиҝҷе Ҷд№ҰйҮҢжӢүеҮәдёҖжң¬жқҘпјҢжҠҠжҜ”е®ғеҸ·е°Ҹзҡ„жү”еҲ°дёҖиҫ№пјҢжҜ”е®ғеӨ§зҡ„жү”еҲ°еҸҰдёҖиҫ№пјҢ然еҗҺеү©дёӢдёӨе Ҷ继з»ӯиҝҷж ·ж•ҙпјҢиҝҷж ·жҺ’зҡ„еҝ«пјҒвҖқиҝҷжҳҜжҲ‘и§ҒиҜҶиҝҮжңҖжғҠиүізҡ„з®—жі•дҪҝз”ЁпјҢжІЎжңүд№ӢдёҖпјҒ
The power of power of 2
дёӢеҚҲи·ҹеҗҢдәӢеҗғйҘӯзҡ„ж—¶еҖҷжӯЈеҘҪиҒҠеҲ°дёҖдёӘй—®йўҳпјҡеҒҮи®ҫдҪ з«ҷеңЁдёҖдёӘи¶іеӨҹй•ҝзҡ„иө°е»ҠдёҠпјҢеңЁиҝҷдёӘиө°е»Ҡзҡ„жҹҗдёӘдҪҚзҪ®жңүдёҖдёӘзү©е“ҒдҪ йңҖиҰҒеҺ»жүҫеҲ°е®ғпјҢиҜ·й—®дҪ еә”иҜҘйҖүжӢ©д»Җд№Ҳж ·зҡ„жҗңзҙўзӯ–з•ҘгҖӮиҝҷдёӘй—®йўҳзҡ„е…ій”®еңЁдәҺдҪ дёҚзҹҘйҒ“зӣ®ж ҮжҳҜеңЁдҪ зҡ„е·Ұиҫ№иҝҳжҳҜеҸіиҫ№пјҢдёәдәҶдҝқиҜҒеңЁзәҝжҖ§еӨҚжқӮеәҰеҶ…жүҫеҲ°е®ғпјҢдҪ еҸҜд»Ҙе…Ҳеҗ‘е·Ұиө°1жӯҘпјҢеӣһеҲ°иө·зӮ№пјҢеҶҚеҗ‘еҸіиө°1жӯҘпјҢеҶҚеӣһеҲ°иө·зӮ№е№¶еҗ‘е·Ұиө°2жӯҘпјҢвҖҰвҖҰпјҢе°ұиҝҷж ·жҢүз…§ 1пјҢ2пјҢ4пјҢ8пјҢ…зҡ„зӯүжҜ”ж•°еҲ—иҝӣиЎҢжҗңзҙўпјҢдёҖзӣҙеҲ°еҸ‘зҺ°зӣ®ж ҮдёәжӯўгҖӮпјҲиҷҪ然еңЁиҝҷйҮҢ2зҡ„зӯүжҜ”并йқһжҳҜжңҖдјҳзҡ„пјҢдҪҶиҝҷдёӘдёҚйҮҚиҰҒгҖӮпјү
еҫҲз®ҖеҚ•зҡ„жҖқжғіеҜ№еҗ§пјҢдҪҶдёҚзҹҘеҪ“йқўиҜ•ж—¶йҒҮеҲ°вҖңиҜ·й—®жҖҺд№ҲжЈҖжөӢдёҖдёӘй“ҫиЎЁжҳҜеҗҰжңүзҺҜвҖқзҡ„й—®йўҳж—¶дҪ жҳҜеҗҰиғҪдёҫдёҖеҸҚдёүе‘ўпјҹжҲ‘еҸҚжӯЈжҳҜжІЎжғіеҲ°пјҢдҪҶжҳҜжңүдәәжғіеҲ°дәҶпјҢиҝҷе°ұжҳҜBrent’s Algorithm http://en.wikipedia.org/wiki/Cycle_detection гҖӮиҝҷдёӘз®—жі•дёҺжүҖи°“зҡ„ж ҮеҮҶи§Јжі•пјҲеҝ«ж…ўжҢҮй’ҲпјҢжҲ–иҖ…еҸ«еҒҡFloyd’s AlgorithmпјүдёҖж ·дјҳз§ҖпјҲеҰӮжһңдёҚжҳҜжӣҙеҘҪзҡ„иҜқпјҢпјүиҜ·еҠЎеҝ…йҡҸиә«иЈ…еӨҮпјҢиҝҷж ·дёӢж¬ЎиӢҘжңүйқўиҜ•е®ҳиҝҳй—®дҪ е°ұеҸҜд»ҘеҘҪеҘҪз§ҖдёҖжҠҠпјҡиҝҷдёӘй—®йўҳжҲ‘жңүдёүз§Қи§Јжі•blablabla…然еҗҺжҠҠBrent’s AlgorithmдёўеҮәеҺ»зіҠд»–дёҖи„ёгҖӮ
2. Fractional Cascading
http://en.wikipedia.org/wiki/Fractional_cascadingпјҢеҸІдёҠжңҖй…·зӮ«зҡ„з®—жі•и®ҫи®ЎжҠҖе·§жІЎжңүд№ӢдёҖгҖӮйҰ–е…ҲеҗҚеӯ—е°ұеҸ–еҫ—йқһеёёйӘҡеҢ…пјҢе…¶ж¬ЎпјҢиҝҳеҚҒеҲҶжңүз–—ж•ҲгҖӮеҲ©з”Ёе®ғеҸҜд»ҘдёҖж¬ЎжҖ§и§ЈеҶіи®Ўз®—еҮ дҪ•дёӯзҡ„дёҖеӨ§зҘЁй—®йўҳпјҢжҜ”еҰӮOrthogonal Range QueryпјҢMultiple List QueryпјҢPoint LocationпјҢзӯүзӯүгҖӮ
3. Rabin Flips a Coin
https://rjlipton.wordpress.com/2009/03/01/rabin-flips-a-coin/гҖӮжұӮе№ійқўдёҠжңҖиҝ‘зӮ№еҜ№зҡ„O(nlogn)з®—жі•еӨ§е®¶йғҪзҹҘйҒ“пјҢеӣ дёәз®—жі•еҜји®әдёҠжңүеҶҷгҖӮдҪҶжҳҜO(n)зҡ„з®—жі•е°ұжІЎйӮЈд№ҲеӨҡдәәдәҶи§ЈдәҶгҖӮRabin's AlgorithmжҳҜйҡҸжңәз®—жі•дёӯзҡ„дёҖдёӘе…ёеһӢд»ЈиЎЁпјҢзңӢдёҠеҺ»зӣҙжҺҘзІ—жҡҙпјҢз”ҡиҮіжҜ”з®—еҜјдёҠйӮЈдёӘеҲҶжІ»жі•иҝҳиҰҒз®ҖеҚ•еҫ—еӨҡпјҢдёәд»Җд№ҲжҹҗеҗҚе…¶еҰҷе°ұO(n)дәҶе‘ўпјҹ
4. Indirection
5. Amortizing – Deamortizing
жҲ‘第дёҖж¬ЎеӯҰз®—жі•зӣҙжҺҘзңӢгҖҠз®—жі•еҜји®әгҖӢпјҢз»“жһңдҝЎеҝғеӨ§еҸ—жү“еҮ»гҖӮеҗҺжқҘеҸ‘зҺ°Robert SedgewickеңЁCourseraдёҠеҮәдәҶдёҖзі»еҲ—з®—жі•и§Ҷйў‘ж•ҷзЁӢпјҢжҠҠдёҖдёӘз®—жі•д»ҘеҠЁз”»зҡ„еҪўејҸеұ•зҺ°еҮәжқҘпјҢйқһеёёйҖӮеҗҲж–°жүӢгҖӮиҜҫзЁӢеҗҚеӯ—е°ұеҸ«AlgorithmпјҢжҷ®жһ—ж–ҜйЎҝеӨ§еӯҰзҡ„пјҢеҲҶдёәPart 1е’ҢPart 2гҖӮ
зңӢи§Ҷйў‘дёҖиҫ№зңӢдёҖиҫ№еҒҡ笔记пјҢзңӢе®ҢдёҖдёӘеҚ•е…ғи·ҹзқҖжҠҠд»Јз ҒеҶҷдёҖйҒҚгҖӮзңӢе®Ңж•ҙдёӘж•ҷзЁӢд№ӢеҗҺжҠҠжүҖжңүз®—жі•йғҪй»ҳеҶҷдёҖйҒҚпјҢеҝҳи®°зҡ„з®—жі•еӨҚд№ дёҖйҒҚгҖӮе°ұй…ұгҖӮ
жӯЈеҘҪжҲ‘д№ҹеңЁеӯҰз®—жі•пјҢеҲқеӯҰиҖ…пјҢжҲ‘и§үеҫ—иҜҙеңЁеӯҰе®ҢдёҖй—ЁиҜӯиЁҖзҡ„иҜӯжі•пјҢжҜ”еҰӮCпјҢжҜ”еҰӮpythonеҗҺгҖӮеҺ»дәҶи§Јж•°жҚ®з»“жһ„иҝҳжңүз®—жі•пјҢиҝҷжҳҜдёҖ件еҫҲйҮҚиҰҒзҡ„дәӢгҖӮ
жҲ‘жқҘеҲҶдә«дёӢжҲ‘зӣ®еүҚзҡ„еӯҰд№ з»ҸйӘҢгҖӮ
йҰ–е…ҲеҲҡжҺҘи§Ұз®—жі•ж—¶пјҢжҲ‘зңӢзҡ„жҳҜгҖҠе•Ҡе“Ҳ!з®—жі•гҖӢгҖӮ
дҪңиҖ…пјҡе•Ҡе“ҲзЈҠгҖӮжӣҫеңЁдёӯ科йҷўзҺ©еҚ•зүҮжңәпјҢеңЁеҫ®иҪҜдәҡжҙІз ”究йҷўејҖеҸ‘вҖңзҲ¬иҷ«вҖқпјҢеңЁеӣҪйҷ…дјҡи®®дёҠеҸ‘иЎЁи®әж–ҮпјҢд№ҹеҒҡиҝҮиҖҒеёҲпјҢжҳҜе…ЁеӣҪйқ’е°‘е№ҙдҝЎжҒҜеӯҰеҘҘжһ—еҢ№е…ӢйҮ‘зүҢж•ҷз»ғгҖӮ
е•Ҡе“Ҳ!з®—жі• (иұҶз“Ј)
жҳҜCиҜӯиЁҖзҡ„д№ҰзұҚпјҢеҶҷзҡ„еҫҲжңүи¶ЈпјҢйқһеёёйҖӮеҗҲе…Ҙй—ЁиҜ»пјҢиғҪеӨҹеҹ№е…»дҪ еӯҰд№ е…ҙи¶Јзҡ„гҖӮ
д№ӢеҗҺеҸҜд»ҘзңӢзҡ„жҳҜзҪ‘жҳ“е…¬ејҖиҜҫзҡ„иҜҫзЁӢпјҢз»ҷдёҠй“ҫжҺҘ
ж•°жҚ®з»“жһ„е’Ңз®—жі•
е°Ҹз”Ійұјзҡ„пјҢи®Ізҡ„йқһеёёжЈ’пјҢдҪҶжҲ‘зӣ®еүҚиҝҳжІЎжңүе…ЁйғЁеӯҰе®Ң~~~~
иҝҳжңүдёҖдёӘжҳҜйә»зңҒзҗҶе·ҘеӯҰйҷўзҡ„е…¬ејҖиҜҫ
йә»зңҒзҗҶе·ҘеӯҰйҷўе…¬ејҖиҜҫпјҡз®—жі•еҜји®әи®ЎеҲ’иҜҰжғ…
жңҖеҗҺе°ұжҳҜеңЁзңӢз»Ҹе…ёд№ӢдҪңгҖҠз®—жі•еҜји®әгҖӢ
з®—жі•еҜји®ә (иұҶз“Ј)
еҘҪйҡҫпјҒпјҒпјҒпјҒпјҒеҘҪеҺҡпјҒпјҒпјҒпјҒпјҒйңҖиҰҒеҫҲеҘҪзҡ„ж•°еӯҰеҹәзЎҖгҖӮжҲ‘жҳҜдёҖиҫ№еҲ·д№ йўҳпјҢдёҖиҫ№зҷҫеәҰи°·жӯҢгҖӮзңӢдёҚжҮӮзҡ„еҸӘиғҪе…Ҳи·ідәҶпјҢеёҢжңӣиҝҷдёӘжҡ‘еҒҮиғҪе…ҲжөҸи§Ҳе®Ңеҗ§гҖӮд»ҘеҗҺеҶҚеӨҡзңӢеҮ йҒҚгҖӮ
第дёҖзҜҮж–ҮзҢ®дёҖе®ҡиҰҒеӨҡзңӢеҮ йҒҚпјҢз»ҶеҢ–еҲ°жҜҸдёҖдёӘе…¬ејҸжҺЁеҜје’Ңз»“и®әпјҲ既然иҜҙеҲ°е…¬ејҸжҺЁеҜјпјҢж•°еӯҰеӣә然йҮҚиҰҒпјҢжіӣеҮҪпјҢе·ҘзЁӢж•°еӯҰпјҢе·ҘзЁӢзҹ©йҳөи®әзӯүзӯүж—¶дёҚж—¶иҰҒеҺ»еӣһйЎҫдёӢпјүпјҢеңЁжӯӨеҹәзЎҖдёҠзј–зЁӢе®һзҺ°гҖӮи®°дҪҸпјҢе…ҲзңӢж–ҮзҢ®еҶҚзңӢд№ҰпјҢжҲ–иҖ…иҜҙд№Ұжң¬еҸӘжҳҜеӯҰд№ з®—жі•зҡ„иҫ…еҠ©е·Ҙе…·пјҢдёҚиҰҒиҠұеӨ§йҮҸж—¶й—ҙдёҖдёӘеӯ—дёҖдёӘеӯ—еҺ»з»ҶиҜ»гҖӮзӯүдҪ еҜ№з»Ҹе…ёз®—жі•зҡ„жҺҢжҸЎз§ҜзҙҜеҲ°дёҖе®ҡзЁӢеәҰд№ӢеҗҺпјҢеҸҜд»Ҙе°қиҜ•еҲӣ新延伸пјҢжҜ”еҰӮе°ҸжіўеҸҳжҚўеӣҫеғҸеҺ»еҷӘдёӯеҜ№ж–№е·®зҡ„дј°и®ЎпјҢе°Ҷе…ЁеұҖж–№е·®дј°и®Ўж”№дёәеұҖйғЁеҲҶеӯҗеёҰж–№е·®дј°и®ЎпјҢе…¶еӨ„зҗҶж•ҲжһңжҳҜеҗҰж”№е–„пјҹ
жҺЁиҚҗгҖҠз®—жі•еҜји®әгҖӢпјҢдҪҶдёҚжҳҜдёҖдёҠжқҘе°ұзңӢпјҢжҲ‘жғіејәи°ғзҡ„жңүеҰӮдёӢеҮ зӮ№пјҡ
пјҲ1пјүеӯҰд№ з®—жі•дёҚжҳҜ件жҳ“дәӢпјҢеә”иҜҘжңүдёҖдёӘзі»з»ҹеҢ–зҡ„еӯҰд№ иҝҮзЁӢпјӣ
пјҲ2пјүеӯҰд№ з®—жі•иҰҒжңүеҫҲеҘҪзҡ„ж•°еӯҰеҹәзЎҖпјҢеҗҰеҲҷеӯҰеҲ°зҡ„з®—жі•еҸӘиғҪжҳҜз”ҹжҗ¬зЎ¬еҘ—пјҢйҒҮеҲ°е®һйҷ…й—®йўҳиҝҳжҳҜдёҚдјҡпјӣпјҲ3пјүеӯҰд№ з®—жі•жңҖеҘҪзҡ„дёӨжң¬д№Ұд»Қ然жҳҜз®—жі•еҜји®ә (иұҶз“Ј)е’Ңз®—жі•и®ҫи®Ў (иұҶз“Ј)гҖӮ
дёҚз®ЎжҳҜи®Ўз®—жңәдё“дёҡпјҢиҝҳжҳҜе…¶е®ғдё“дёҡжғіиҮӘеӯҰз®—жі•пјҢеӯҰд№ зҡ„и·ҜзәҝеӨ§иҮҙжҳҜиҝҷж ·зҡ„пјҡ
йҳ¶ж®өдёҖпјҡ
еҹәзЎҖж•°еӯҰиҜҫпјҡеҫ®з§ҜеҲҶпјҢзәҝжҖ§д»Јж•°пјҢжҰӮзҺҮи®ә
жІЎжңүеҫ®з§ҜеҲҶжһҒйҷҗпјҢ收ж•ӣзӯүжҰӮеҝөпјҢжҖҺд№ҲеҺ»зҗҶи§Јз®—жі•дёӯж—¶й—ҙеӨҚжқӮеәҰпјҢз©әй—ҙеӨҚжқӮеәҰзҡ„жҰӮеҝөпјӣдёҚжҮӮзҹ©йҳөз®—жі•дёӯзҡ„еӣҫз®—жі•жҖҺд№ҲеҺ»е…ҘжүӢпјҢдёҚжҮӮжҰӮзҺҮи®әйҡҸжңәз®—жі•еә”иҜҘдёҚеҘҪеӯҰпјҢж—¶й—ҙеӨҚжқӮеәҰдј°и®Ўз®—дёҚжқҘгҖӮеӯҰд№ д№ҰзұҚеҸҜеҸӮиҖғеӯҰж Ўи®ҫзҡ„зӣёе…іиҜҫзЁӢпјҢжҰӮзҺҮи®әзҡ„иҜқжҺЁиҚҗдёҖжң¬д№ҰпјҡжҰӮзҺҮи®әдёҺж•°зҗҶз»ҹи®Ў (иұҶз“Ј)гҖӮиҝҷдёүй—ЁеҹәзЎҖиҜҫжҳҜдёҖе®ҡиҰҒеӯҰеҘҪзҡ„гҖӮ
йҳ¶ж®өдәҢпјҡ
и®Ўз®—жңәзӣёе…іж•°еӯҰпјҡзҰ»ж•Јж•°еӯҰпјҢеӣҫи®ә
зҰ»ж•Јж•°еӯҰйҮҢйқўжңүз®—жі•пјҢи®Ўж•°пјҢеҪ’зәізӯүеҹәжң¬жҰӮеҝөпјҢеӣҫи®әйҮҢжӣҙжҳҜеӣҠжӢ¬дәҶж ‘пјҢеӣҫе’ҢжөҒзҡ„жүҖжңүзҗҶи®әзҹҘиҜҶпјҢиҝҷдәӣжҳҜж ‘пјҢеӣҫпјҢжөҒзӯүз®—жі•зҡ„еҹәзЎҖгҖӮзҰ»ж•Јж•°еӯҰжҺЁиҚҗд№ҰзұҚпјҡзҰ»ж•Јж•°еӯҰеҸҠе…¶еә”з”Ё (иұҶз“Ј)пјҢеӣҫи®әжҺЁиҚҗд№ҰзұҚпјҡеӣҫи®ә (иұҶз“Ј)гҖӮ
и®Ўз®—жңәзӣёе…іпјҡCиҜӯиЁҖпјҢж•°жҚ®з»“жһ„
ж•°еӯҰжҜ•з«ҹеҸӘжҳҜзҗҶи®әпјҢиҝҳеҫ—жңүе®һйҷ…зҡ„зј–зЁӢе·Ҙе…·пјҢжҺЁиҚҗеӯҰдёҖй—Ёе…Ҙй—Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢCиҜӯиЁҖжңҖдҪіпјҲд№ҹжңүй«ҳж ЎдёҖдёҠжқҘе°ұеӯҰC++жҲ–иҖ…javaзҡ„пјҢдёӘдәәдёҚжҺЁиҚҗпјүпјҢиҝҳжңүж•°жҚ®з»“жһ„жӣҙжҳҜйҮҚдёӯд№ӢйҮҚпјҢиҝҷжҳҜдҪ иғҪжҠҠж ‘пјҢеӣҫиғҪз”Ёи®Ўз®—жңәиҜӯиЁҖиЎЁиҫҫеҮәжқҘзҡ„еҹәзЎҖпјҢжҲ‘ж•ўиҜҙпјҢеҸ«дҪ е®һзҺ°дёҖйў—з®ҖеҚ•зҡ„дәҢеҸүж ‘пјҢдҪ йғҪдёҚдёҖе®ҡиғҪеҶҷеҮәжқҘпјҢйӮЈдҪ иҝҳи°ҲеӯҰд»Җд№Ҳз®—жі•пјҢж•°жҚ®з»“жһ„жҺЁиҚҗд№ҰзұҚпјҡж•°жҚ®з»“жһ„ (иұҶз“Ј)пјҢCиҜӯиЁҖе’Ңж•°жҚ®з»“жһ„еҸҜд»ҘеңЁеӯҰд№ дёҠиҝ°ж•°еӯҰзҹҘиҜҶд№Ӣдёӯз©ҝжҸ’зқҖдёҖиө·еӯҰгҖӮ
йҳ¶ж®өдёүпјҡ
зі»з»ҹеӯҰд№ з®—жі•пјҢе•ғгҖҠз®—жі•еҜји®әгҖӢеҗ§
е…¶е®һйҖҡиҝҮйҳ¶ж®өдёҖпјҢйҳ¶ж®өдәҢзҡ„еӯҰд№ пјҢе·Із»Ҹеҹәжң¬жҺҢжҸЎдәҶз®—жі•зӣёе…ізҡ„жүҖжңүзҹҘиҜҶдәҶпјҢйӮЈиҝҳзјәд»Җд№Ҳе‘ўпјҹзі»з»ҹеӯҰд№ з®—жі•пјҢиҖҢгҖҠз®—жі•еҜји®әгҖӢе°ұиғҪеҫҲеҘҪзҡ„з»ҷжҲ‘们дёҖдёӘеӯҰд№ з®—жі•зҡ„еӨ§жЎҶжһ¶пјҢж·ұе…Ҙе…¶дёӯеҗ§пјҢдҪ дјҡеҸ‘зҺ°дёҠйқўи®Ізҡ„еҶ…е®№дҪ жҳҜйӮЈд№ҲзҶҹжӮүпјҢдҪҶжҳҜдҪ зҡ„收иҺ·еҸҲжҳҜйӮЈд№ҲеӨҡгҖӮеңЁж•ҙдёӘиҝҮзЁӢпјҢеҸҜз»“еҗҲгҖҠз®—жі•и®ҫи®ЎгҖӢиҝҷжң¬д№ҰдёҖиө·еӯҰпјҢгҖҠз®—жі•еҜји®әгҖӢзңӢдёҚжҮӮеҶ…е®№зҡ„еҺ»гҖҠз®—жі•и®ҫи®ЎгҖӢдёҠзңӢпјҢдёӨжң¬дә’иЎҘгҖӮ
йҳ¶ж®өеӣӣпјҡ
з®—жі•е®һи·өпјҢжҖқз»ҙжү©еұ•гҖӮ
еҲ°иҝҷе„ҝе·Із»ҸжІЎжңүд»Җд№Ҳж–№жі•иҖҢиЁҖдәҶпјҢе°ұжҳҜеӨҡз»ғд№ пјҢејҘиЎҘдёҚжҮӮзҡ„зҹҘиҜҶпјҢ继з»ӯз»ғд№ пјҢз»ғд№ йўҳеҸҜеҸӮиҖғзҪ‘дёҠзҡ„дёҖдәӣз®—жі•йўҳйӣҶпјҢеҰӮleetcodeжҲ–иҖ…ACMйўҳжҲ–иҖ…еҗ„еӨ§дә’иҒ”зҪ‘е…¬еҸёз¬”иҜ•йқўиҜ•йўҳгҖӮдёӘдәәжҺЁиҚҗдёӨжң¬д№ҰзұҚпјҡзј–зЁӢзҸ зҺ‘ (иұҶз“Ј)пјҢзј–зЁӢд№ӢзҫҺ (иұҶз“Ј)пјҢдёӨжң¬д№ҰйғҪжңүдёҖе®ҡйҡҫеәҰпјҢдҪҶжҳҜеҰӮжһңеүҚеҮ дёӘйҳ¶ж®өйғҪиғҪеҒҡеҘҪзҡ„иҜқпјҢдҪ иҺ·еҫ—зҡ„дёҖе®ҡжҳҜи¶Је‘ігҖӮ
жңҖеҗҺпјҢиҝҳжҳҜиҰҒејәи°ғдёҖзӮ№пјҢд№ҹжҳҜжҲ‘еҸҚеӨҚејәи°ғзҡ„пјҢеҺҡз§ҜжүҚиғҪи–„еҸ‘пјҢдёҚиҰҒжө®иәҒпјҢдёҚиҰҒжғізқҖзңӢдёҖжң¬д№Ұе°ұжҠҠз®—жі•еӯҰеҘҪпјҢз®—жі•жҳҜиҙҜз©ҝж•ҙдёӘзј–зЁӢз”ҹж¶Ҝзҡ„пјҢжҜ•з«ҹиҝҷдёӘејҸеӯҗдёҚжҳҜиҜҙзқҖзҺ©зҡ„пјҡзЁӢеәҸ=з®—жі•+ж•°жҚ®з»“жһ„гҖӮ
еёҢжңӣеӨ§е®¶иғҪйқҷдёӢеҝғжқҘпјҢд»ҺжңҖеҹәзЎҖзҡ„ж•°еӯҰзҹҘиҜҶе’Ңж•°жҚ®з»“жһ„еӯҰиө·пјҢдёҚиҰҒиҙӘеӨҡпјҢеӯҰжүҺе®һжүҚжҳҜзҺӢйҒ“гҖӮеёҢжңӣеӨ§е®¶йғҪиғҪжҠҠз®—жі•еӯҰеҘҪпјҢиғҪеҶҷеҮәй«ҳиҙЁйҮҸзҡ„д»Јз ҒпјҢдёҺеӨ§е®¶дёҖеҗҢиҝӣжӯҘпјҢе…ұеӢүгҖӮ
и®ҫи®Ўи®Ўз®—жңәзЁӢеәҸз®—жі•е’ҢжұӮи§Јж•°еӯҰйўҳжңүеҫҲеӨ§зҡ„зӣёеҗҢд№ӢеӨ„гҖӮзЁӢеәҸз®—жі•жңҖз»ҲиҰҒз”ЁжҢҮд»ӨиЎЁиҫҫпјҢи§Јж•°еӯҰйўҳзҡ„ж–№жі•жңҖз»ҲиҰҒз”Ёж•°еӯҰе…¬ејҸжқҘиЎЁиҫҫгҖӮеҫҖеҫҖи§ЈеҶій—®йўҳзҡ„ж №жң¬еңЁдәҺеҰӮдҪ•жғіеҲ°жұӮи§Јзҡ„ж–№жі•пјҢиҖҢдёҚжҳҜеҺ»и®°еҝҶжұӮи§Јж–№жі•зҡ„е…·дҪ“жӯҘйӘӨгҖӮеёӮйқўдёҠз»қеӨ§еӨҡж•°зҡ„з®—жі•д№ҰзұҚпјҲеҢ…жӢ¬гҖҠз®—жі•еҜји®әгҖӢгҖҠз®—жі•пјҡcиҜӯиЁҖе®һзҺ°гҖӢгҖҠзј–зЁӢзҸ зҺ‘гҖӢзӯүпјүпјҢеҹәжң¬йғҪд»…д»…з»ҷеҮәдәҶз®—жі•зҡ„е…·дҪ“жӯҘйӘӨгҖҒеӨҚжқӮеәҰеҲҶжһҗгҖҒжӯЈзЎ®жҖ§иҜҒжҳҺгҖӮеҪ“жҲ‘зңӢи§Ғеҝ«йҖҹжҺ’еәҸгҖҒе ҶжҺ’еәҸгҖҒеҠЁжҖҒ规еҲ’зӯүи®©жҲ‘жғҠеҸ№зҡ„з®—жі•ж—¶пјҢжҲ‘жҖ»жҳҜеңЁжғідҪңиҖ…жҳҜжҖҺд№ҲжғіеҲ°иҝҷдёӘз®—жі•зҡ„пјҹдҪҶжҲ‘е°ұжҳҜзҷҫжҖқдёҚеҫ—е…¶и§ЈгҖӮзӣҙеҲ°жңҖиҝ‘жҲ‘зңӢеҲ°дәҶдёӨжң¬д№ҰпјҲд»…д»…зңӢдәҶе°ҸйғЁеҲҶпјүжүҚж…ўж…ўејҖе§ӢйўҶжӮҹдёҖзӮ№зӮ№з®—жі•и®ҫи®Ўзҡ„еҘҘеҰҷгҖӮ
1гҖҒгҖҠз®—жі•еј•и®ә—-дёҖз§ҚеҲӣйҖ жҖ§ж–№жі•гҖӢпјҲе»әи®®е…ҲзңӢ第5з« пјҢзңҹжҳҜзҲҪзҲҶдәҶпјү
2гҖҒгҖҠThe Science of ProgrammingгҖӢ
еҸҰеӨ–пјҢеҰӮжһңжғідәҶи§ЈжҖҺд№ҲжғіеҲ°жұӮи§Јж•°еӯҰйўҳзҡ„ж–№жі•пјҢе»әи®®зңӢзңӢгҖҠжҖҺж ·и§ЈйўҳгҖӢ
еҺ»жЁЎжӢҹпјҲеҪ“然模жӢҹеҸӘйҷҗдәҺеҹәзЎҖзҡ„з®—жі•)гҖӮз”ҡиҮіжҳҜжүӢеҠЁжЁЎжӢҹпјҢжҜ”еҰӮжҲ‘д№ӢеүҚеӯҰж·ұжҗңпјҢеӯҰйҖ’еҪ’пјҢд»Јз ҒеҫҲз®ҖеҚ•пјҢдҪҶжҳҜеӣ дёәж¶үеҸҠеҲ°ж ҲпјҢиҖҢдҪ зҡ„еӨ§и„‘зҹӯж—¶й—ҙеҶ…еӯҳеӮЁзҡ„ж Ҳж·ұеәҰеҸӘжңүеҮ еұӮпјҲдёҙж—¶еҸҳйҮҸи¶ҠеӨҡдҪ еӨ§и„‘иғҪжЁЎжӢҹзҡ„ж Ҳж·ұеәҰе°ұи¶Ҡе°‘пјүпјҢе®һйҷ…дёҠдҪ жІЎеҠһжі•з”ЁеӨ§и„‘еҺ»жғігҖӮжҜ”еҰӮеӯҰд№ еӣҫзҡ„ж·ұжҗңпјҢдёҖејҖе§ӢжҲ‘жҳҜдёҚзҗҶи§Јзҡ„пјҢеҜ№йҖ’еҪ’жІЎеҠһжі•зҗҶи§ЈгҖӮеҗҺжқҘжҲ‘е°ұеңЁзәёдёҠжЁЎжӢҹеҮәжқҘпјҢе»әз«ӢеҘҪйӮ»жҺҘиЎЁд»ҘеҗҺпјҢжҢүз…§д»Јз ҒжӯҘйӘӨдёҖжӯҘжӯҘзәёз¬”жқҘжЁЎжӢҹпјҢж…ўж…ўе°ұзҹҘйҒ“дәҶд»Јз Ғзҡ„е·ҘдҪңиҝҮзЁӢгҖӮдҪ еӯҰд№ еҝ«жҺ’д№ҹжҳҜпјҢеҪ“然дҪ иғҢд»Јз Ғд№ҹиғҪеҶҷеҮәжқҘпјҢдҪҶжҳҜеҸҜиғҪдёҚзҗҶи§ЈпјҢеҫҲеҝ«е°ұеҝҳдәҶгҖӮгҖҠз®—жі•еҜји®әгҖӢд№ҰдёҠе°ұжңүжҜ”иҫғз»ҶиҮҙзҡ„жү§иЎҢиҝҮзЁӢпјҢдҪ жүӢеҠЁжЁЎжӢҹдёӢpartitionе’Ңquicksortзҡ„иҝҮзЁӢпјҢдёҖејҖе§Ӣе°ұз”ЁеҫҲз®ҖеҚ•зҡ„з”ЁдҫӢпјҢжҠҠж•ҙдёӘиҝҮзЁӢйғҪжүӢеҠЁжү§иЎҢдёҖйҒҚпјҢж…ўж…ўе°ұдәҶи§ЈдәҶгҖӮеҫҲеӨҡз®—жі•йғҪжңүдёҖдёӘеҫӘзҺҜдёҚеҸҳејҸпјҢдҪ д»Јз ҒеҰӮжһңйҖ»иҫ‘жӯЈзЎ®е№¶дё”иғҪеӨҹз»ҙжҢҒеҫӘзҺҜдёҚеҸҳејҸпјҢдёҖиҲ¬еҶҷеҮәжқҘе°ұжҳҜжӯЈзЎ®зҡ„гҖӮ
е»әи®®жүҫжң¬гҖҠз®—жі•гҖӢжҲ–иҖ…гҖҠз®—жі•еҜји®әгҖӢиҝҷдәӣж•ҷжқҗпјҢжҜҸеӯҰд№ дёҖдёӘз®—жі•е°ұе…ҲеӨ§иҮҙжөҸи§ҲдёӢпјҢ 然еҗҺз»ҶиҮҙеҲҶжһҗжҜҸдёҖжӯҘд»Јз Ғзҡ„жү§иЎҢиҝҮзЁӢпјҲзәёз¬”жЁЎжӢҹжҲ–иҖ…д»Јз ҒеҚ•жӯҘи°ғиҜ•пјүпјҢеҪ“зЎ®и®ӨдҪ зңҹжӯЈжҳҺзҷҪд№ӢеҗҺпјҢе°қиҜ•дёҚзңӢд»Јз Ғе°ұйқ еҜ№з®—жі•иҝҮзЁӢзҡ„дәҶи§Је’ҢжӯЈзЎ®зҡ„йҖ»иҫ‘еҺ»иҮӘе·ұе®һзҺ°гҖӮ
еҪ“然пјҢжҲ‘дёҚи®ӨдёәдҪ еҶҷеҮәеҫҲеӨҡз®—жі•е°ұжҳҜй«ҳжүӢдәҶпјҢзҺ°еңЁеӨ§йғЁеҲҶй«ҳзә§иҜӯиЁҖдёҚйңҖиҰҒдҪ йҮҚеӨҚйҖ иҪ®еӯҗпјҢдҪ йҖ еҮәжқҘзҡ„иҙЁйҮҸд№ҹиҝңйҖҠдәҺеә“дёӯйӮЈдәӣй«ҳжүӢзҡ„д»Јз ҒпјҢеҸҜд»ҘеҺ»еӯҰд№ д»–д»¬д»Јз Ғзҡ„е®һзҺ°пјҢжҜ”еҰӮзңӢзңӢstlжәҗз ҒгҖӮзңҹжӯЈе·ҘзЁӢз”ЁеҲ°зҡ„д»Јз ҒдёҺдёҖиҲ¬з®—жі•е®һзҺ°иҝҳжҳҜжңүеҫҲеӨҡж”№иҝӣзҡ„гҖӮ
жңҖйҮҚиҰҒзҡ„дёҚжҳҜдҪ дјҡеҶҷиҝҷдәӣз®—жі•дәҶпјҢиҖҢжҳҜеӯҰдјҡдәҶеҫҲеӨҡжҖқжғігҖӮжҜ”еҰӮдәҢеҲҶзҡ„жҖқжғіпјҢйҖ’еҪ’зҡ„жҖқжғіпјҢеҲҶжІ»зҡ„жҖқжғіпјҢеҠЁжҖҒ规еҲ’пјҢиҙӘеҝғзӯүпјҢд»ҘеҸҠзҺ°е®һдёӯеҫҲеӨҡж•°жҚ®з»“жһ„зҡ„жҠҪиұЎзӯүгҖӮйҡҫзҡ„дёҚжҳҜеӯҰдјҡдәҶз®—жі•пјҢиҖҢжҳҜеҰӮдҪ•иҝҗз”Ёиҝҷдәӣз®—жі•жҖқжғіеҺ»и§ЈеҶій—®йўҳгҖӮ
жҲ‘и®°еҫ—еӨ§дёҖеӯҰж ЎжңүдёӘд»Җд№Ҳж•°еӯҰе»әжЁЎзҸӯпјҢдҪңдёәиҖғиҜ•е…ҘзҸӯйңҖиҰҒжҸҗдәӨдёҖдёӘзЁӢеәҸи§ЈдёҖеӨ§е Ҷеә”з”Ёйўҳдёӯзҡ„дёҖдёӘгҖӮеҪјж—¶з®—жі•иҜҫи®Ўз®—жңәзі»иҝҳжІЎжңүж•ҷпјҢе…¶д»–зі»жӣҙдёҚз”ЁиҜҙгҖӮдҪҶжҳҜиҝҳжҳҜжңүеҗ„з§Қдәәзү©з”ЁиҮӘеҸ‘жҳҺзҡ„еҗ„з§Қз®—жі•еҠ дёҠиҮӘеӯҰзҡ„Cе’ҢC++жҠҠеҗ„з§Қй—®йўҳйғҪе•ғдёӢжқҘдәҶгҖӮдёҚз”Ёд»»дҪ•жЎҶжһ¶зӣҙжҺҘC++/COMеҠ 3Dзў°ж’һжЈҖжөӢзҡ„DirectXжёёжҲҸз…§ж ·жңүдәәеҒҡеҮәжқҘпјҢиҝҳдёҚжҳҜи®Ўз®—жңәзі»зҡ„гҖӮжҲ‘йӮЈж—¶и§үеҫ—е·Із»ҸеҲ°жҲ‘и„‘еҠӣжһҒйҷҗзҡ„DirectX/OpenGLиӢұж–ҮжүӢеҶҢеңЁд»–зңӢжқҘе’Ңж—Ҙжј«дёҖж ·з®ҖеҚ•еҝ…йЎ»жҳҜж•°и®әеҸҳжҚў,жҲ‘дёҚе«Ңдёўдәә,зңӢеҲ°иҝҷдёӘз®—жі•д№ӢеүҚжҲ‘ж №жң¬дёҚзҹҘйҒ“ж•°и®әиғҪе№Іеҗ—з”Ё.
дёҖдёӘеҹәдәҺж•°и®әзҡ„еҸҳжҚў,жҠҠж•ҙж•°еҹҹеҸҳжҚўеҲ°ж•ҙж•°еҹҹ,еұ…然иғҪе’ҢFFTеҪўејҸдёҠдёҖиҮҙ,иҝҳе’Ңе®ҡзӮ№DSP
з»“еҗҲеҫ—иҝҷд№ҲеҘҪ,иҝһд№ҳжі•еҷЁйғҪдёҚз”Ё,зӣҙжҺҘ移дҪҚе°ұиғҪеҝ«йҖҹз®—еҚ·з§Ҝ,жғҠдәҶ! еҪ“ж—¶жҳҜеңЁеӣҫд№ҰйҰҶзҡ„дёҖдёӘ
еҫҲз ҙ,ж—§зҡ„еҸ‘й»„зҡ„д№ҰдёҠзңӢеҲ°зҡ„,еҪ“ж—¶жңүдёҖз§Қж‘”дёӢжӮ¬еҙ–ж— ж„ҸдёӯеҸ‘зҺ°дәҶжӯҰеҠҹз§ҳзұҚзҡ„ж„ҹи§ү
дјӘйҡҸжңәз®—жі• пјҲPseudo Random DistributionпјҢз®Җз§°PRDпјҢдёҚжҳҜйңҖжұӮж–ҮжЎЈ!пјү
жҡҙеҮ»зңҹзҡ„зңӢи„ёеҗ—пјҹеҪ“然дёҚжҳҜдәҶпјҢеҪ“дҪ ж·ұеҲ»зҗҶи§ЈдәҶдјӘйҡҸжңәз®—жі•пјҢжҲ‘жғідҪ иҝҳжҳҜеҸҜд»ҘеҜ№жҡҙеҮ»иҝӣиЎҢдёҖдәӣдәәдёәе№Ійў„зҡ„гҖӮиҝҷдёӘж—¶еҖҷе°ұжҳҜдҪ dota ж°ҙе№іиҝҲеҗ‘еҸҰдёҖдёӘеўғз•Ңзҡ„ж—¶еҖҷдәҶгҖӮ
дјӘйҡҸжңәи·ҹзңҹйҡҸжңәжңүд»Җд№ҲеҢәеҲ«е‘ўпјҹжқҘдёҫдёӘдҫӢеӯҗеҗ§пјҢеҒҮеҰӮеү‘еңЈзҡ„жҡҙеҮ»еҮ зҺҮдёә20%пјҢйӮЈд№ҲзңҹйҡҸжңәзҡ„жғ…еҶөдёӢпјҢзі»з»ҹйҡҸжңәеңЁ1~100йҮҢйқўз”ҹдә§дёҖдёӘж•ҙж•°пјҢеҰӮжһңз”ҹжҲҗзҡ„ж•ҙж•°е°ҸдәҺзӯүдәҺ20пјҢйӮЈиҝҷж¬Ўж”»еҮ»е°ұеҲӨе®ҡдёәжҡҙеҮ»гҖӮиҝҷдёӘж—¶еҖҷе°ұжңүеҸҜиғҪеҮәзҺ°иҝһз»ӯ5ж¬Ўж”»еҮ»е…ЁжҳҜи·іеҠҲпјҢи„ёй»‘еҫ—йҖүжүӢеҸҜиғҪиҝһз»ӯ10ж¬Ўж”»еҮ»д№ҹжІЎжңүдёҖж¬ЎжҡҙеҮ»гҖӮиҖҢжһҒйҷҗзҡ„жғ…еҶөе°ұжҳҜпјҢдҪ зҡ„BMжҲ–иҖ…PAеҸҜиғҪдёҖж•ҙеңәйғҪеңЁжҡҙеҮ»пјҲеҚ§ж§ҪпјҢдҪ дё«ејҖжҢӮе‘ўпјүпјҢжҲ–иҖ…дҪ жү“е®ҢдёҖж•ҙеңәйғҪжІЎжҡҙеҮ»иҝҮдёҖж¬ЎпјҲиү№пјҢз®ҖзӣҙзҢӘйҳҹеҸӢе•ҠпјүгҖӮиҖҢдјӘйҡҸжңәе‘ўпјҢе°ұжҳҜз”ЁжқҘи§ЈеҶігҖҢеҮҸе°‘иҝһз»ӯжҖ§жҡҙеҮ»пјҢеҮҸе°‘иҝһз»ӯжҖ§жІЎжҡҙеҮ»гҖҚиҝҷдёӘй—®йўҳгҖӮ
иҝҳжҳҜжӢҝеү‘еңЈ20%жҡҙеҮ»жҰӮзҺҮдёҫдҫӢпјҢиҝҷж—¶еҖҷеү‘еңЈз¬¬дёҖж¬Ўж”»еҮ»жҡҙеҮ»зҡ„жҰӮзҺҮжҳҜ5.57%пјҢиҖҢдёӢж¬Ўзҡ„ж”»еҮ»е°ұдјҡжҳҜ11.14%пјҢеҰӮжһң第дәҢж¬ЎиҝҳжІЎжҡҙеҮ»пјҢйӮЈд№ҲжҺҘдёӢжқҘзҡ„第дёүж¬Ўж”»еҮ»зҡ„жҡҙеҮ»жҰӮзҺҮе°ұжҸҗеҚҮеҲ°дәҶ16.71%пјҢжҜҸж¬ЎйғҪеҠ 5.57%пјҢзӣҙеҲ°з¬¬17ж¬Ўж”»еҮ»е°ұдјҡжҳҜ100.26%зҡ„дҝқиҜҒжҖ§жҡҙеҮ»пјҲ (вҠҷoвҠҷ)вҖҰпјҢеҘҪеғҸиҝҳзңҹжңүи„ёй»‘зҡ„жғ…еҶөеӯҳеңЁпјүгҖӮжҡҙеҮ»д№ӢеҗҺеӣһеҲ°д№ӢеүҚзҡ„5.57%пјҢиҝҷж ·еңЁеӨҡж¬Ўзҡ„ж”»еҮ»еҗҺдјҡеҪўжҲҗдёӘе№іеқҮ20%жҡҙеҮ»зҡ„еҮ зҺҮгҖӮ
д»ҘдёӢдҪҝз”ЁPRDжңәеҲ¶зҡ„еҲ—иЎЁ
иҝӣж”»зұ»пјҢжҡҙеҮ»гҖҒйҮҚеҮ»гҖҒеҸҢеҲҖгҖҒжј©ж¶Ў
йҳІеҫЎзұ»пјҢеұұеІӯзҡ„зҡ®иӮӨпјҢжүҖжңүзӣҫзұ»
дёҚеҸ—PRDжңәеҲ¶жҺ§еҲ¶зҡ„зү©е“Ғжңү
зўҺйӘЁй”ӨпјҢж·ұжёҠд№ӢеҲҖзҡ„жҷ•пјҢиқҙиқ¶/еӨ©е Ӯд№ӢжҲҹзҡ„й—ӘгҖӮ
жҰӮзҺҮе…¬ејҸ
P(N) иЎЁзӨәеңЁз¬¬Nж¬Ўж”»еҮ»д№ӢеҗҺжҹҗдёӘеҠЁдҪңеҸ‘з”ҹеҫ—жҰӮзҺҮпјҲдёӢйқўиҝҳжҳҜд»ҘжҡҙеҮ»дёҫдҫӢеҗ§пјүпјҢNиЎЁзӨә第Nж¬Ўдҝ®жӯЈжҰӮзҺҮеҗҺеҫ—ж”»еҮ»ж¬Ўж•°пјҲжңҖе°ҸеҖјдёә1пјүпјҢCиЎЁзӨәжҡҙеҮ»еҸ‘з”ҹзҡ„еҲқе§ӢжҰӮзҺҮд»ҘеҸҠжҜҸж¬Ўж”»еҮ»д№ӢеҗҺжҰӮзҺҮзҡ„еўһйҮҸпјҢжҳҜдёӘз®ҖеҚ•ең°зәҝжҖ§е…ізі»гҖӮеҪ“Nи¶іеӨҹеӨҡеҫ—ж—¶еҖҷпјҢPпјҲNпјүжҖ»дјҡи¶Ӣеҗ‘дәҺ1гҖӮеңЁд»ҘдёӢзҡ„ж–Үз« йҮҢпјҢжҠҖиғҪжҸҸиҝ°дёҠзҡ„жҰӮзҺҮдјҡд»Ҙ P(E) жқҘд»ЈжӣҝпјҢиЎЁзӨәжңҹжңӣеҖјгҖӮ
PRD еёёж•°C
д»ҘдёӢжңүдёӨдёӘиЎЁжқҘжҸҸиҝ°еёёзҶҹCгҖӮP(E)иЎЁзӨәжңҹжңӣеҖјпјҢCжҳҜеёёж•°гҖӮMAX NиЎЁзӨә зҗҶи®әдёҠеҸ еҠ еҲ°100%жҡҙеҮ»д№ӢеүҚзҡ„жңҖеҗҺдёҖж¬Ўж”»еҮ»ж¬Ўж•°пјҢдёҫдёӘдҫӢеӯҗпјҢеҰӮдёӢиЎЁпјҢжҜ”еҰӮзҡ„жҡҙеҮ»еҮ зҺҮжҳҜ45%пјҢCжҳҜ0.24931пјҢйӮЈд№ҲNе°ұжҳҜ4пјҢеӣ дёәд№ӢеүҚзҡ„иҝһз»ӯ4ж¬Ўж”»еҮ»йғҪеҸҜд»ҘжҳҜжҷ®йҖҡж”»еҮ»пјҢдҪҶ第дә”ж¬Ўзҡ„ж—¶еҖҷпјҢеҝ…е®ҡжҡҙеҮ»гҖӮ
еҪ“然д»ҘдёҠеҫ—зҗҶи®әеҖјдёҚжҳҜжҡҙйӣӘе®һйҷ…дёӯеә”з”Ёзҡ„ж•°еҖјпјҢе®һйҷ…еә”з”ЁжҳҜеҰӮдёӢиЎЁ
еңЁдёҠйқўиЎЁдёӯеҸҜд»ҘеҸ‘зҺ°пјҢеҪ“жҡҙеҮ»еҮ зҺҮеҲ°дёҖе®ҡеҖјеҫ—ж—¶еҖҷпјҢе®һйҷ…жҡҙеҮ»еҮ зҺҮе°ұдҪҺдәҺP(actual)е°ұдҪҺдәҺP(E),иҝҷеҗҺйқўе°ұдјҡж¶үеҸҠеҲ°жҡҙеҮ»ж”¶зӣҠйҖ’еҮҸзҡ„й—®йўҳпјҢиҝҷйҮҢе°ұдёҚж·ұе…Ҙи®Ёи®әдәҶпјҢеҝ…е®ҡdotaйҮҢйқўзҡ„жҡҙеҮ»еҘҪеғҸд№ҹдёҚжҳҜйӮЈд№ҲеҘҪе ҶпјҢеғҸ WOW йҮҢйқўеҖ’жҳҜеҸҜд»Ҙи®Ёи®әдёҖдёӢгҖӮ
еҶҚжҠҠдёӨдёӘеӣҫж”ҫдёҖиө·еҜ№жҜ”пјҢеҘҪеҘҪж„ҹеҸ—дёҖдёӢгҖӮеёёж•°CеңЁеңЁ30%зҡ„ж—¶еҖҷе®һйҷ…еҖји·ҹзҗҶи®әеҖјиҝҳжҳҜеҫҲжҺҘиҝ‘зҡ„пјҢдҪҶжҳҜи¶…иҝҮиҝҷдёӘеҖјд»ҘеҗҺпјҢиҜҜе·®е°ұејҖе§ӢеӨ§дәҶгҖӮ
йӮЈд№Ҳеј•иө·иҝҷдёӘжҰӮзҺҮеҒҸе·®зҡ„еҺҹеӣ жҳҜд»Җд№Ҳе‘ўпјҹз®ҖеҚ•еҪ’зәіжҳҜз”ұд»ҘдёӢдёӨзӮ№еӣ зҙ йҖ жҲҗзҡ„
1.еёёж•°Cзҡ„жңүж•ҲдҪҚж•°гҖӮжҲ‘们еҸҜд»Ҙд»ҺдёҠйқўзҡ„иЎЁж јдёӯзңӢеҲ°пјҢеңЁе®һйҷ…иҝҗз®—дёӯжҲ‘们没жңүйҮҮз”Ёж— зәҝжңүж•ҲдҪҚиҖҢжҳҜеҸ–дәҶдёҖдёӘиҝ‘дјјзҡ„5дҪҚе°Ҹж•°зӮ№пјҢйҖ жҲҗдәҶд№ӢеҗҺзҡ„иҜҜе·®гҖӮеҰӮжһңжҳҜйҮҮеҸ–еҠЁжҖҒе®һж—¶иҝҗз®—зҡ„Cзҡ„иҜқпјҢиҝҷдјҡеңЁжҜҸдёҖж¬Ўж”»еҮ»еҠЁдҪңзҡ„еҲӨе®ҡйғҪдјҡиҖ—иҙ№йқһеёёеӨҡзҡ„CPUиө„жәҗпјҢеӣ жӯӨйҖүеҸ–дәҶдёҖз§ҚйқҷжҖҒзҡ„look up tableгҖӮ
2.жүҖжңүзҡ„ж•°еҖјйғҪжҳҜдјҡеӨ©жўҜең°еӣҫеҮҶеӨҮзҡ„пјҢиҖҢдёҚжҳҜжҷ®йҖҡз”ЁжҲ·иҮӘе·ұзј–иҫ‘зҡ„ең°еӣҫгҖӮжҲ‘们еҸҜд»ҘеҸ‘зҺ°еӨ©жўҜең°еӣҫйҮҢйқўжҠҖиғҪжҰӮзҺҮеҖјжңҖеӨ§зҡ„зү№ж®Ҡж”»еҮ»жҳҜзүӣеӨҙдәәзҡ„зІүзўҺпјҢ25%пјҢеҶҚеӣһеӨҙзңӢзңӢпјҢеңЁ30%д»ҘдёӢпјҢе®һйҷ…жҠҖиғҪи§ҰеҸ‘жҰӮзҺҮе’ҢжңҹжңӣжҰӮзҺҮжҳҜеҹәжң¬дёҖиҮҙзҡ„пјҢ30%д»ҘеҗҺзҡ„CеҖјйғҪжҳҜеңЁз”Ёд№ӢеүҚзҡ„ж•°жҚ®жӢҹеҗҲеҮәжқҘзҡ„гҖӮиҖҢдё”иҜҙе®һиҜқпјҢжҡҙйӣӘзІ‘зІ‘зӣ®еүҚд№ҹдёҚеңЁж„Ҹиҝҷдәӣжғ…еҶөгҖӮ